
Resumen ejecutivo
Nuestra investigación reveló una vulnerabilidad fundamental en la cadena de suministro de IA que permite a los atacantes obtener Ejecución Remota de Código (RCE, por sus siglas en inglés) y capacidades adicionales en plataformas principales como Azure AI Foundry de Microsoft, Vertex AI de Google y miles de proyectos de código abierto. Nos referimos a este problema como Reutilización de Espacios de Nombres de Modelos (Model Namespace Reuse).
Hugging Face es una plataforma que permite a los desarrolladores de IA crear, compartir e implementar modelos y conjuntos de datos (datasets). En dicha plataforma, los espacios de nombres (namespaces) son los identificadores de los modelos, los cuales son repositorios de Git almacenados en el hub de Hugging Face. Los modelos de Hugging Face contienen configuraciones, pesos, código e información para que los desarrolladores puedan utilizarlos.
La reutilización de espacios de nombres de modelos ocurre cuando los catálogos de modelos de un proveedor de nube o el propio código recuperan un modelo eliminado o transferido basándose en su nombre. Al volver a registrar un espacio de nombres abandonado y recrear su ruta original, los actores maliciosos pueden atacar las canalizaciones (pipelines) que implementan modelos basándose únicamente en su nombre. Esto potencialmente permite a los atacantes implementar modelos maliciosos y obtener capacidades de ejecución de código, entre otros impactos.
Aunque hemos realizado una divulgación responsable de este hallazgo a Google, Microsoft y Hugging Face, el problema de fondo sigue siendo una amenaza para cualquier organización que obtenga modelos basándose únicamente en su nombre. Este descubrimiento demuestra que confiar en los modelos solo por su nombre es insuficiente y exige una reevaluación crítica de la seguridad en todo el ecosistema de IA.
Las organizaciones pueden obtener ayuda para evaluar la postura de seguridad de la nube a través de la Evaluación de la seguridad en la nube de Unit 42.
La Evaluación de la seguridad de la IA de Unit 42 puede ayudar a las organizaciones a potenciar el uso y el desarrollo seguros de la IA.
Si cree que puede haber resultado vulnerado o tiene un problema urgente, póngase en contacto con el equipo de respuesta ante incidentes de Unit 42.
| Temas relacionados con Unit 42 | Cadena de suministro, GenAI |
Explicación de la reutilización del espacio de nombres del modelo
Es esencial comprender cómo Hugging Face organiza e identifica los modelos para entender la técnica de reutilización del espacio de nombres de los modelos. El recurso más común en su plataforma es el modelo. Estos modelos son esencialmente repositorios Git que contienen configuraciones de modelos, ponderaciones y cualquier código o información adicional que los desarrolladores y los investigadores puedan necesitar para utilizar los modelos con eficacia.
Cómo los desarrolladores obtienen modelos
Con fines de identificación y acceso, los desarrolladores pueden referenciar y extraer modelos utilizando una convención de nomenclatura en dos partes: Author/ModelName. En esta estructura, el componente Author (Autor) representa al usuario o la organización de Hugging Face que publicó el modelo, mientras que ModelName es el nombre del modelo.
Por ejemplo, si AIOrg publicó el modelo Translator_v1, el nombre del modelo es AIOrg/Translator_v1. Los nombres de los autores sirven como identificadores únicos. Si ya existe un autor, no se puede crear uno nuevo con el mismo nombre.
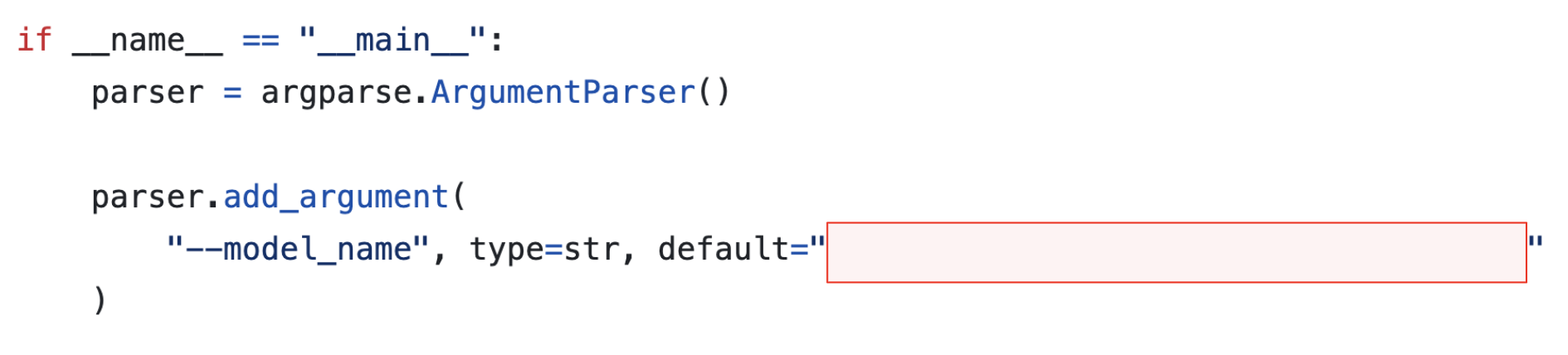
Los desarrolladores utilizan el identificador Author/ModelName directamente en su código en varias bibliotecas de Hugging Face para obtener y utilizar modelos. Por ejemplo, los desarrolladores pueden utilizar el código que se muestra en la Figura 1 para obtener el modelo Translator_v1 de la biblioteca Transformers de uso común.

Esta estructura jerárquica permite lograr una atribución y una organización claras. Sin embargo, en ausencia de controles estrictos del ciclo de vida sobre estos espacios de nombres, esta estructura también crea una superficie de ataque inesperada.
La técnica de reutilización del espacio de nombres del modelo aprovecha la forma en que Hugging Face gestiona los espacios de nombres Author/ModelName después de que una organización o un autor eliminen su propia cuenta. Nuestra investigación en este ámbito reveló un aspecto crítico: cualquiera puede volver a registrar un espacio de nombres eliminado.
Cuando se elimina un usuario o una organización de Hugging Face, su espacio de nombres único no deja de estar disponible de forma permanente. En su lugar, estos identificadores vuelven a una reserva de nombres disponibles, lo que le permite a otro usuario crear posteriormente una organización con el mismo nombre. Este proceso de reutilización se muestra en Caso de uso 1: Vertex AI.
Supresión de la propiedad en Hugging Face
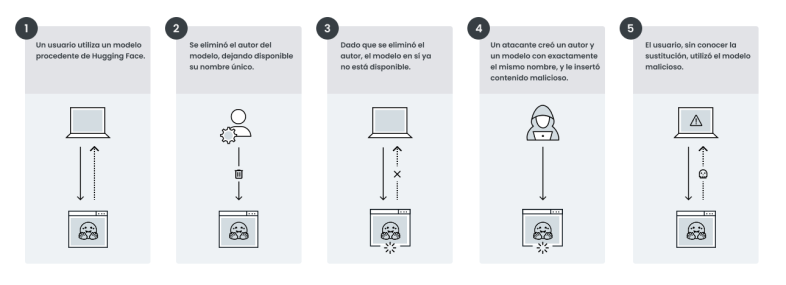
Considere la siguiente situación hipotética de un modelo cuyo autor ha sido eliminado:
La organización DentalAI creó el modelo legítimo toothfAIry. El modelo puede analizar imágenes dentales y detectar con precisión caries y otras anomalías dentales. Su eficacia y facilidad de uso la convirtieron en una favorita de desarrolladores, investigadores dentales y profesionales de la salud. Con el tiempo, DentalAI/toothfAIry se integró en herramientas de diagnóstico, plataformas médicas e incluso repositorios de tecnología sanitaria de código abierto.
En algún momento, sin embargo, los desarrolladores de DentalAI eliminaron la organización de Hugging Face. Un actor malicioso se percató de ello y, para aprovecharse de la situación, recreó la organización DentalAI y subió una versión comprometida del modelo toothfAIry con el mismo nombre.
Como resultado, todas las bases de código y los conductos que todavía hacen referencia al modelo original ahora están en grave riesgo.
Se podría suponer que, mientras un nombre de modelo de confianza siga funcionando en su código, no habrá riesgo de reutilización maliciosa de ese espacio de nombres. Esto es un error de concepto. Sin que los desarrolladores sean conscientes, las bases de código y los flujos podrían extraer e implementar la versión maliciosa. Los modelos maliciosos podrían dar lugar a una serie de resultados no deseados, desde diagnósticos incorrectos hasta el acceso no autorizado continuo por parte de un atacante en los sistemas afectados.
En la Figura 2, se describen los pasos que se siguen en esta situación hipotética.
Otro posible vector de ataque se deriva de la forma en que Hugging Face gestiona la transferencia de propiedad de los modelos.
Transferencia de propiedad en Hugging Face
Hugging Face ofrece la posibilidad de cambiar el autor de un modelo transfiriendo la propiedad del propietario actual a otro. Esta transferencia resulta en un nuevo espacio de nombres para el modelo; por ejemplo, cambiar de AIOrg/Translator_v1 a AIOrgNew/Translator_v1. Los usuarios pueden implementar el modelo utilizando este nuevo espacio de nombres. Sin embargo, el espacio de nombres original sigue siendo accesible para su implementación.
Cuando un usuario envía una solicitud al antiguo espacio de nombres, Hugging Face lo redirige automáticamente al nuevo espacio de nombres actual. Esta redirección se aplica a todos los puntos de acceso, incluida la interfaz de usuario (UI), las API REST y los kits de desarrollo de software (SDK) comunes.
Este comportamiento es lógico e intencional. El objetivo de Hugging Face es garantizar que los flujos existentes sigan funcionando sin problemas, incluso después de un cambio de espacio de nombres. Sin embargo, como se muestra en la situación anterior, si el propietario del modelo original elimina su organización, el espacio de nombres vuelve a estar disponible para su registro.
Si un actor malicioso registra el espacio de nombres, se rompe el mecanismo de redirección, haciendo que el modelo comprometido tenga prioridad sobre el nuevo modelo legítimo.
Para explicar esta situación hipotética, recurriremos de nuevo a la salud dental.
Otra organización, Dentalligence, adquirió DentalAI. Como parte de la adquisición, DentalAI transfirió todos sus modelos de IA a la organización Dentalligence. Tras la transferencia, los administradores de DentalAI borraron la organización original de Hugging Face, ya que había sido totalmente absorbida por Dentalligence.
Todos los modelos pertenecientes a DentalAI, como DentalAI/toothfAIry, pasaron a ser accesibles a través de nuevas rutas, como Dentalligence/toothfAIry. En aras de la continuidad, Hugging Face mantuvo las redirecciones de los antiguos espacios de nombres a los nuevos, lo que permitía a los usuarios acceder a los modelos sin actualizar su código.
Sin embargo, un actor malicioso se dio cuenta de que la organización DentalAI original estaba disponible. El atacante registró una nueva organización con ese nombre y subió modelos maliciosos utilizando los mismos nombres que los que DentalAI alojaba antes de la adquisición.
Como los nombres originales de los modelos siguieron siendo válidos e implementables durante toda la transición, los usuarios no se enteraron del cambio. No encontraron tiempo de inactividad y no tuvieron que cambiar los nombres de los modelos en su código. Por ejemplo, al solicitar la extracción del modelo DentalAI/toothfAIry se extrae automáticamente Dentalligence/toothfAIry. Como resultado, cuando el actor malicioso insertaba su versión utilizando los nombres originales, los usuarios, sin saberlo, empezaban a implementar las versiones maliciosas en lugar de los modelos de confianza que habían integrado originalmente.
Comparación de las situaciones hipotéticas
En miles de proyectos de código abierto existen espacios de nombres de modelos reutilizables codificados. Entre ellos se incluyen repositorios populares y con muchas estrellas, y repositorios que pertenecen a organizaciones destacadas del sector. Además, estos modelos suponen una amenaza para los usuarios de las principales plataformas de IA.
En la tabla, se resumen las diferencias entre las dos situaciones.
| Supresión de la propiedad | Transferencia de la propiedad | |
| Causa | Se borró el autor del modelo de Hugging Face. | Se transfirió el modelo a un nuevo propietario, y se eliminó el autor anterior de Hugging Face. |
| Experiencia del usuario | Los usuarios experimentarán un tiempo de inactividad, ya que el modelo no existe. | Los usuarios no se verán afectados, ya que sus solicitudes se redirigen al nuevo modelo. |
| Códigos de estado HTTP en el acceso al modelo | 404 | 307 |
| Señales de identificación | El autor del modelo ya no está disponible en Hugging Face. | Al intentar acceder al modelo, Hugging Face redirige al usuario a un autor diferente. Además, el autor anterior ya no está disponible. |
Tabla 1. Diferencias clave entre los modelos reutilizables eliminados y los modelos reutilizables transferidos.
La reutilización del espacio de nombres del modelo en la práctica
Estudio de caso n.º 1: Vertex AI
Google Vertex AI es una plataforma gestionada de aprendizaje automático (ML) en Google Cloud Platform (GCP). Los desarrolladores utilizan Vertex AI para crear y escalar modelos que se integran con otros servicios de Google Cloud.
Una característica clave de Vertex AI es Model Garden, un repositorio centralizado de modelos preentrenados de Google, terceros y la comunidad de código abierto. En particular, Model Garden de Vertex AI admite la implementación directa de modelos de Hugging Face. Esto significa que los usuarios pueden seleccionar un modelo de Hugging Face e implementarlo en Vertex AI en unos pocos pasos, sin necesidad de empaquetado personalizado.
En la Figura 3, se muestra la implementación del modelo distilbert/distilgpt2.
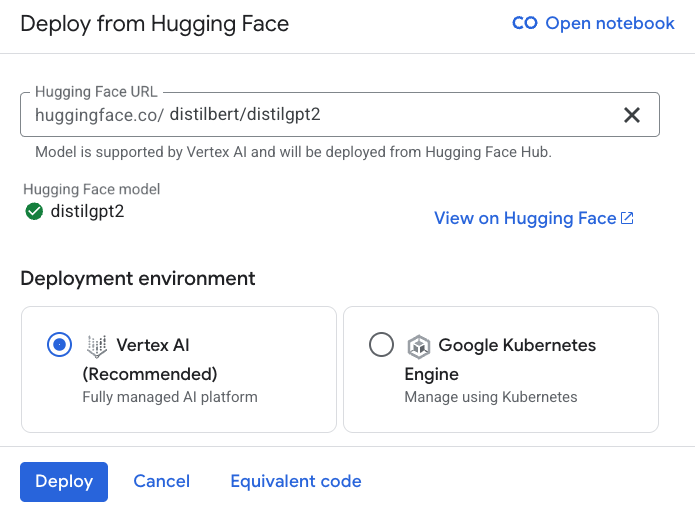
Es importante señalar que no todos los modelos pueden implementarse inmediatamente a través de Vertex AI. Una marca de verificación verde junto al nombre del modelo significa que Google verificó que el modelo se puede implementar en Vertex AI.
Además, la interfaz ofrece un cómodo enlace a la ficha del modelo en Hugging Face, lo que permite a los usuarios revisar rápidamente la documentación, las licencias y otros detalles clave. En la Figura 4, se muestra un ejemplo de la tarjeta del modelo distilbert/distilgpt2.
Al examinar la lista de modelos que Vertex AI ofrece para su implementación directa desde Hugging Face y al comprobar si se eliminaron los autores originales, identificamos varios modelos reutilizables. Se trata de modelos que cumplen las dos condiciones siguientes:
- El propietario del modelo eliminó la organización del autor de Hugging Face
- Vertex AI sigue enumerando y verificando el modelo
En las Figuras 5 y 6, se ilustra un ejemplo de este tipo de modelo, que puede implementarse en Vertex AI, aunque su autor no esté en Hugging Face.
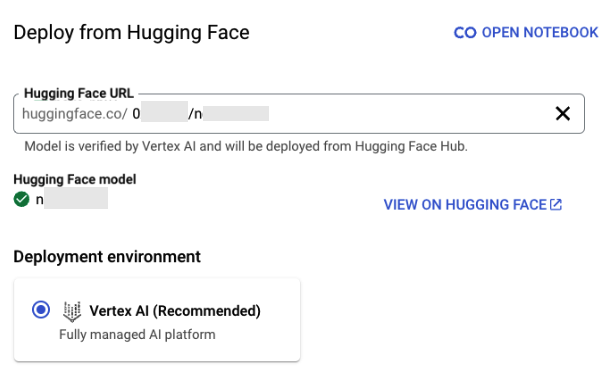
Registramos uno de los espacios de nombres de autor y creamos un modelo con el mismo nombre dentro, como se muestra en la Figura 7.
Una vez realizada la toma de control, cualquier implementación del modelo original dará lugar a la implementación de nuestro nuevo modelo.
Para demostrar el impacto potencial de una técnica de este tipo, incrustamos una carga útil en el modelo que inicia un shell inverso desde la máquina que ejecuta la implementación hasta nuestros servidores. Una vez que Vertex AI implementó el modelo, obtuvimos acceso a la infraestructura subyacente que albergaba el modelo, en concreto, el entorno de endpoint. En la Figura 8, se muestra el shell inverso desde el endpoint hasta nuestra máquina controlada.

El entorno al que se accede es un contenedor dedicado con un alcance limitado dentro del entorno GCP. Una vez demostrado este vector, eliminamos la puerta trasera del repositorio del modelo.
Desde que informamos de este problema a Google en febrero de 2025, Google comenzó a realizar análisis diarios para identificar los modelos que han quedado huérfanos. El escaneado marca los modelos huérfanos como “verificación fallida”, impidiendo que puedan implementarse en Vertex.
Estudio de caso n.º 2: Azure AI Foundry
Azure AI Foundry es la plataforma de Microsoft para el desarrollo de aplicaciones de ML y de IA generativa. Proporciona herramientas para las distintas fases del ciclo de vida de la IA, incluida la ingesta de datos, el entrenamiento de modelos, la implementación y la supervisión.
El núcleo de Azure AI Studio es su catálogo de modelos, un centro que incluye modelos básicos de Microsoft, colaboradores de código abierto y proveedores comerciales. El catálogo de Azure AI Foundry permite a los usuarios implementar y personalizar modelos en la plataforma. En la Figura 9, se muestra que el catálogo incluye muchos modelos procedentes de Hugging Face.
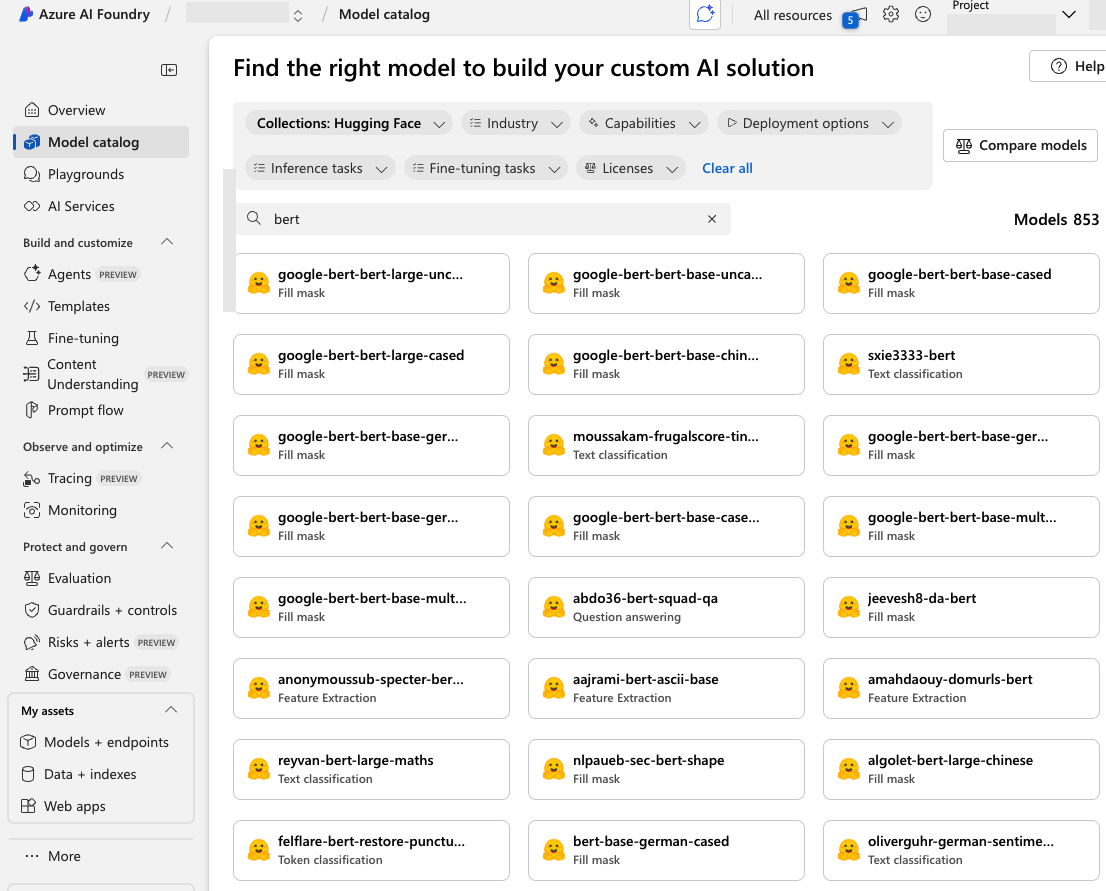
Revisamos la lista de modelos disponibles en Azure AI Foundry y nos centramos en los procedentes de Hugging Face. Comprobamos si la cuenta del autor original de cada modelo había sido eliminada. Una vez más, identificamos varios modelos reutilizables: modelos cuyos espacios de nombres de autor ya no pertenecían a nadie, pero seguían estando disponibles para la implementación.
Para demostrar el riesgo, registramos uno de estos nombres de autor sin reclamar en Hugging Face y cargamos un modelo incrustado con un shell inverso. Tras la implementación, el shell inverso se ejecutó correctamente, concediéndonos acceso al endpoint subyacente, como se muestra en la Figura 10.
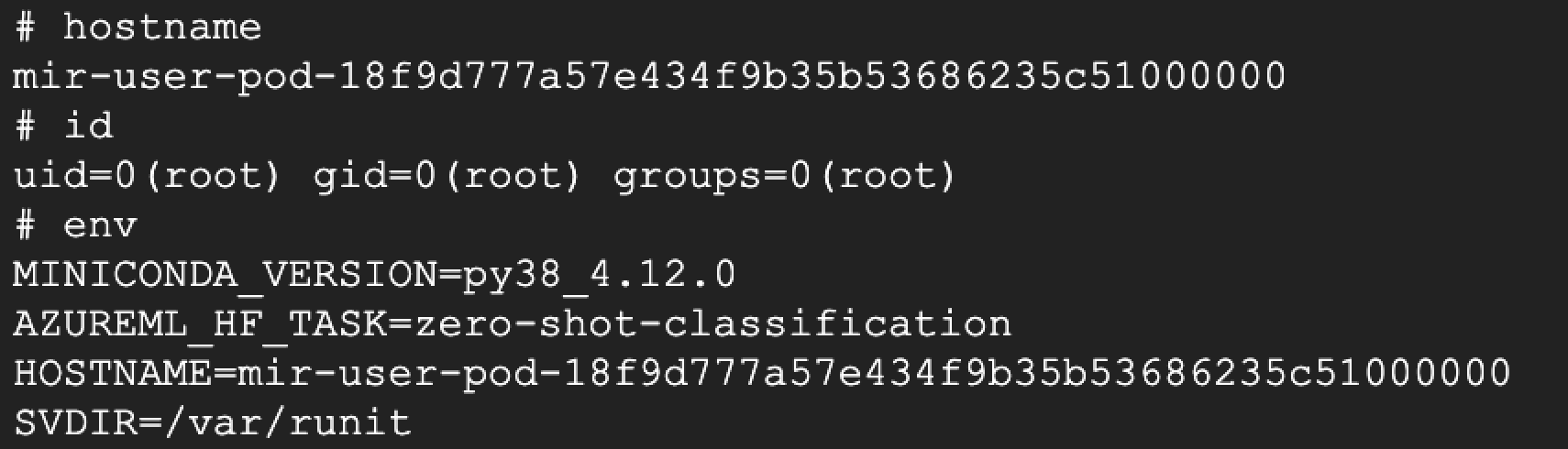
Al explotar este vector de ataque, obtuvimos permisos que se correspondían con aquellos del endpoint de Azure. Esto nos proporcionó un punto de acceso inicial al entorno Azure del usuario. Una vez demostrado este vector, eliminamos la puerta trasera del repositorio del modelo.
Estudio de caso n.º 3: Repositorios de código abierto
Tras observar el impacto de la reutilización de espacios de nombres de modelos en los principales servicios de IA en la nube, realizamos una búsqueda exhaustiva de repositorios de código abierto. Nuestro objetivo era identificar proyectos que hicieran referencia a modelos de Hugging Face mediante identificadores de tipo Author/ModelName que estuvieran disponibles para ser reclamados.
Estos proyectos exponen a sus usuarios a importantes riesgos de seguridad. Los atacantes pueden aprovecharse de las dependencias del proyecto al identificar un Author/ModelName disponible, registrarlo y cargarle archivos maliciosos. Es probable que luego estos archivos se implementen en entornos de usuario durante la implementación o la ejecución del proyecto.
Empezamos buscando en GitHub repositorios de código abierto con métodos SDK que obtuvieran modelos de Hugging Face. Luego, acotamos la búsqueda al identificar nombres de modelos en estos repositorios. Para descubrir modelos reutilizables, comprobamos en cada modelo si su autor había sido eliminado y si era posible registrarlo.
Esta investigación reveló miles de repositorios susceptibles, entre ellos varios proyectos muy conocidos y con muchas estrellas. Estos proyectos incluyen tanto modelos eliminados como modelos transferidos con el autor original eliminado, lo que hace que los usuarios no detecten la amenaza, ya que estos proyectos siguen funcionando con normalidad.
En las Figuras 11 y 12, se muestra la presencia de modelos y nombres reutilizables en proyectos populares de código abierto.

Estudio de caso n.º 4: Cadena de fugas en registros de modelos
Hasta ahora, hemos examinado escenarios en los que usuarios y desarrolladores obtienen modelos directamente de Hugging Face. Ya sea utilizando una plataforma de IA gestionada o un SDK de código abierto, muchos entornos lo utilizan como fuente principal.
Sin embargo, otros registros de modelos (sistemas centralizados que gestionan el almacenamiento, las versiones y el ciclo de vida de los modelos de ML) también extraen modelos de Hugging Face y los ofrecen a los usuarios como parte de sus modelos disponibles.
Esto crea un riesgo para la cadena de suministro. Si un registro de modelos ingiere modelos reutilizables de Hugging Face, esos modelos pueden propagarse hacia abajo. Como resultado, los usuarios que confían en dichos registros podrían estar expuestos a modelos comprometidos sin interactuar directamente con Hugging Face.
Tomemos Vertex AI como ejemplo. Como ya se ha comentado, Vertex AI ofrece una integración perfecta para implementar y utilizar modelos de Hugging Face en el entorno GCP. Los usuarios pueden obtener fácilmente un modelo utilizando el SDK de Vertex AI, como se muestra en la Figura 13.

En esta situación, el usuario obtiene el modelo model_name directamente de Vertex AI. Sin embargo, si este modelo proviene de Hugging Face y está disponible en el catálogo de modelos, el usuario podría acceder inadvertidamente a un modelo infectado.
Otra plataforma propiedad de Google que incorpora Hugging Face como fuente de modelos es Kaggle. Kaggle es un conocido centro de ciencia de datos y ML que proporciona conjuntos de datos, cuadernos y una colección de modelos preentrenados. En la Figura 14, se muestra que en su catálogo de modelos, Kaggle ofrece miles de modelos originados en Hugging Face que se pueden implementar.
Al igual que con los registros de modelos analizados anteriormente, Kaggle también ofrece varios modelos que son vulnerables a la reutilización de espacios de nombres de modelos, lo que supone un riesgo inmediato para sus usuarios.
El reto de la integridad de los modelos en la IA
Hacer un seguimiento de los modelos de ML es un desafío complejo y continuo. Los desarrolladores actualizan, afinan, bifurcan y vuelven a publicar sus modelos constantemente. A menudo, lo hacen a través de múltiples plataformas y organizaciones. Hemos observado oportunidades de reutilización de espacios de nombres de modelos en varias partes de estos sistemas complejos de varios componentes. Esto es cierto no solo en las implementaciones de modelos, que plantean el riesgo más inmediato y significativo. Encontramos referencias a modelos reutilizables en tarjetas de modelos, documentaciones, parámetros por defecto y cuadernos de ejemplos.
Que el mismo problema de reutilización de modelos exista en GCP, Azure y muchos proyectos de código abierto pone de relieve uno de los aspectos más críticos, y a menudo pasados por alto, de la seguridad de la IA y el ML: verificar que el modelo que se está utilizando sea realmente el que uno cree que es. Tanto si el proyecto extrae un modelo de un registro público, como si lo reutiliza desde un flujo interno o lo implementa a través de un servicio gestionado, siempre existe el riesgo de que alguien haya sustituido, manipulado o explotado la redirección del modelo.
Los modelos pueden proceder de diversos registros, no solo de Hugging Face. Model Garden de Vertex AI, el catálogo de modelos de Azure AI Foundry y Kaggle ofrecen una amplia gama de modelos, muchos de ellos obtenidos directamente de Hugging Face.
Esta integración, aunque es conveniente, introduce riesgos. Los desarrolladores que confían en los catálogos de modelos de confianza de los principales servicios de IA en la nube podrían implementar, sin saberlo, modelos maliciosos alojados originalmente en Hugging Face sin haber interactuado directamente con Hugging Face.
Cabe reconocer que todas estas plataformas se esfuerzan por proteger sus registros de modelos. Sin embargo, como hemos demostrado, ningún sistema es totalmente inmune al secuestro del espacio de nombres o a las vulnerabilidades de la cadena de suministro. Incluso con medidas de protección sólidas, un solo caso extremo que se pase por alto puede dar lugar a una explotación destructiva.
Garantizar la seguridad de las herramientas de IA no es responsabilidad exclusiva de los proveedores de plataformas. Los desarrolladores también deben tomar medidas activas para proteger los flujos y los entornos.
Pasos prácticos para tener un ciclo de vida de ML que sea seguro
Ya hemos explorado algunos de los desafíos inherentes a la seguridad de los flujos que alimentan los modelos de ML. Desde la ingesta de datos hasta la implementación, es crucial garantizar la integridad en cada paso. La buena noticia es que no somos impotentes ante estas complejidades. Existen medidas concretas que podemos tomar para mejorar significativamente la seguridad y la fiabilidad de los sistemas de IA. A continuación, se mencionan algunas prácticas clave.
- Fijación de la versión: el uso de métodos como from_pretrained("Author/ModelName") para obtener modelos puede dar lugar a comportamientos inesperados, problemas de estabilidad o incluso la integración de modelos maliciosos debido a la obtención automática de la última versión. Una solución para este problema es fijar el modelo a una confirmación específica utilizando el parámetro de revisión. El comando from_pretrained("Author/ModelName", revision="abcdef1234567890") garantiza que el modelo se encuentre en un estado esperado y evita que el comportamiento del modelo cambie de forma inesperada. Esto ayuda al desarrollador a garantizar un comportamiento coherente del modelo para la depuración y la ejecución.
- Clonación de modelos y almacenamiento controlado: para entornos muy sensibles o de producción, recomendamos clonar el repositorio de modelos en una ubicación de confianza, como un almacenamiento local, un registro interno o almacenamiento en la nube. Este enfoque permite desacoplar la carga del modelo de cualquier fuente externa, lo que elimina el riesgo de que haya cambios previos o problemas de conectividad. Por supuesto, la clonación del modelo solo debe hacerse tras un proceso sólido de escaneado y verificación.
- Búsqueda de referencias reutilizables: escanee las referencias de modelos en los repositorios de código y trate las referencias de modelos como cualquier otra dependencia sujeta a políticas y revisión. El escaneo debe ser exhaustivo, ya que los modelos pueden existir en lugares inesperados, como los argumentos por defecto, docstrings y comentarios. El escaneo proactivo de las bases de código en busca de referencias de modelos reduce el riesgo de ataques a la cadena de suministro causados por la reutilización de espacios de nombres de modelos.
Conclusión: las nuevas realidades de la seguridad de la cadena de suministro de la IA
Mostramos cómo un atacante podría reclamar y reutilizar identificadores de modelos en Hugging Face para ejecutar código remoto dentro de plataformas de IA populares, como Vertex AI de Google, Azure AI Foundry y varios proyectos de código abierto. En ambos casos, el problema surge porque el nombre de un modelo por sí solo no basta para garantizar su integridad o fiabilidad.
Analizamos este tema con los proveedores mencionados en este artículo. La reutilización del espacio de nombres del modelo es un problema complejo de resolver y el riesgo sigue existiendo. No se trata de un problema aislado, sino de un desafío que es sistémico a la forma en que la comunidad de la IA gestiona y valida la integridad de los modelos compartidos. Este desafío va mucho más allá de la simple gestión del espacio de nombres, y nos obliga a enfrentarnos a cuestiones sobre la seguridad fundamental de la infraestructura de la IA, que evoluciona rápidamente.
Los usuarios pueden mejorar la seguridad con respecto a las amenazas descritas anteriormente al implementar la fijación de versiones, clonar repositorios de modelos en ubicaciones de almacenamiento de confianza y escanear en busca de referencias reutilizables.
Las organizaciones pueden obtener ayuda para evaluar la postura de seguridad de la nube a través de la Evaluación de la seguridad en la nube de Unit 42.
La Evaluación de la seguridad de la IA de Unit 42 puede ayudar a las organizaciones a potenciar el uso y el desarrollo seguros de la IA.
Si cree que puede haber resultado vulnerado o tiene un problema urgente, póngase en contacto con el equipo de respuesta ante incidentes de Unit 42 o llame al:
- Norteamérica: llamada gratuita: +1 (866) 486-4842 (866.4.UNIT42)
- Reino Unido: +44.20.3743.3660
- Europa y Oriente Medio: +31.20.299.3130
- Asia: +65.6983.8730
- Japón: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 00 800 050 45107
Palo Alto Networks ha compartido estos resultados con nuestros compañeros de Cyber Threat Alliance (CTA). Los miembros de CTA utilizan esta inteligencia para implementar rápidamente medidas de protección para sus clientes y desarticular sistemáticamente a los ciberdelincuentes. Obtenga más información sobre Cyber Threat Alliance.
Recursos adicionales
ÍNDICE
Relacionados Investigación de ciberseguridad en la nube Recursos








