
Avant-propos
Notre étude a mis en évidence une faille fondamentale dans la chaîne d'approvisionnement de l'IA, permettant à des attaquants d'obtenir une Exécution de Code à Distance (RCE) ainsi que d'autres capacités sur des plateformes majeures telles que l'Azure AI Foundry de Microsoft, Vertex AI de Google et des milliers de projets open source. Nous avons baptisé cette problématique « Model Namespace Reuse » (Réutilisation d'espaces de noms de modèles).
Hugging Face est une plateforme qui permet aux développeurs d'IA de créer, partager et déployer des modèles et des jeux de données. Sur cette plateforme, les espaces de noms (namespaces) servent d'identifiants pour les modèles, qui sont des dépôts Git stockés sur le hub Hugging Face. Les modèles Hugging Face contiennent des configurations, des poids, du code et des informations permettant aux développeurs de les utiliser.
Le « Model Namespace Reuse » se produit lorsque des catalogues de modèles de fournisseurs de cloud, ou le code associé, récupèrent un modèle supprimé ou transféré en se basant sur son nom. En réenregistrant un espace de noms abandonné et en recréant son chemin d'accès d'origine, des acteurs malveillants peuvent cibler les pipelines qui déploient des modèles en se fiant uniquement à leur nom. Cela peut potentiellement permettre à des attaquants de déployer des modèles malveillants et d'obtenir des capacités d'exécution de code, entre autres impacts.
Bien que nous ayons divulgué cette vulnérabilité de manière responsable à Google, Microsoft et Hugging Face, le problème fondamental demeure une menace pour toute organisation qui récupère des modèles en se basant uniquement sur leur nom. Cette découverte prouve que la confiance accordée aux modèles sur la seule base de leur nom est insuffisante et nécessite une réévaluation critique de la sécurité dans l'ensemble de l'écosystème de l'IA.
Les organisations peuvent bénéficier d’un accompagnement dans l’évaluation de leur posture de sécurité grâce à l’Évaluation de la sécurité du cloud de l’Unit 42.
Notre approche les aide également à sécuriser l’usage et le développement de l’IA.
Si vous pensez que votre entreprise a pu être compromise ou si vous faites face à une urgence, contactez l’équipe Unit 42 de réponse à incident.
| Unit 42 – Thématiques connexes | Supply Chain, GenAI |
Réutilisation des espaces de noms de modèles : l’explication
Comprendre comment Hugging Face organise et identifie les modèles est essentiel pour saisir la technique de réutilisation des espaces de noms. La ressource la plus courante sur cette plateforme sont les modèles, qui sont en réalité des dépôts Git qui contiennent la configuration, les poids ainsi que tout code ou élément supplémentaire dont les développeurs et chercheurs peuvent avoir besoin pour les utiliser efficacement.
Comment les développeurs récupèrent les modèles
Pour identifier et accéder aux modèles, les développeurs utilisent une convention de nommage en deux parties : Author/ModelName. Dans cette structure, la partie Author correspond à l’utilisateur ou à l’organisation Hugging Face ayant publié le modèle, tandis que ModelName est le nom du modèle.
Par exemple, si l’organisation AIOrg publie le modèle Translator_v1, le nom complet du modèle sera AIOrg/Translator_v1. Les noms d’auteur servent d’identifiants uniques : si un auteur existe déjà, il n’est pas possible d’en créer un autre portant le même nom.
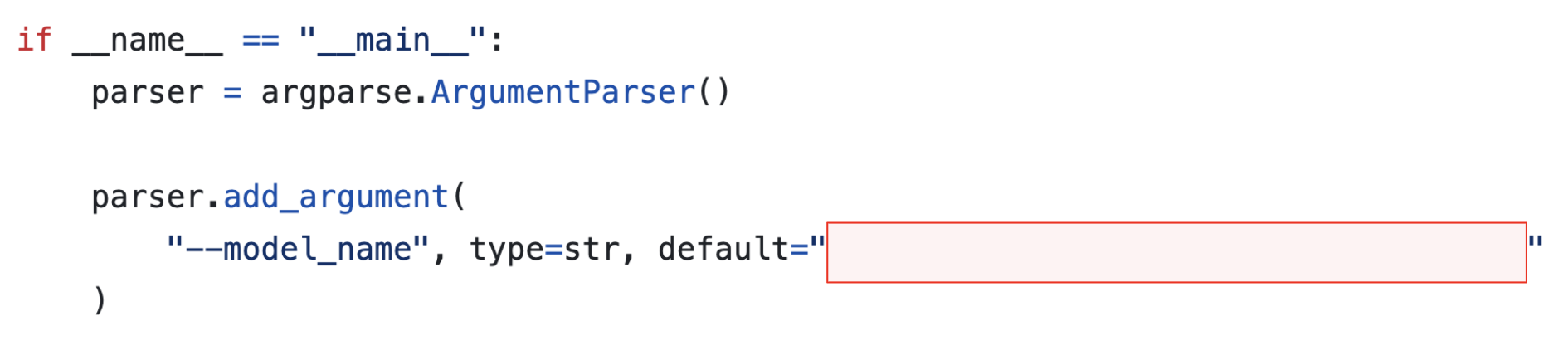
Les développeurs emploient directement cet identifiant Author/ModelName dans leur code, au sein des différentes bibliothèques Hugging Face, pour télécharger et utiliser les modèles. Ainsi, le code présenté à la figure 1 permet de récupérer le modèle Translator_v1 depuis la bibliothèque Transformers, largement utilisée.

Cette structure hiérarchique permet une attribution claire et une organisation cohérente. Cependant, en l’absence de garde-fous stricts concernant le cycle de vie de ces espaces de noms, une surface d’attaque inattendue voit le jour.
La technique de réutilisation des espaces de noms de modèles exploite la manière dont Hugging Face gère les identifiants Author/ModelName après la suppression d’un compte, qu’il s’agisse d’un utilisateur ou d’une organisation. Nos recherches dans ce domaine ont mis en évidence un point critique : n’importe qui peut réenregistrer un espace de noms supprimé.
Lorsqu’un utilisateur ou une organisation est supprimé de Hugging Face, son espace de noms unique ne devient pas définitivement indisponible. Ces identifiants retournent dans un pool d’options disponibles, permettant à un autre utilisateur de créer ultérieurement une organisation sous le même nom. Ce mécanisme de réutilisation est illustré dans l’Étude de cas 1 – Vertex AI.
Suppression d’un propriétaire dans Hugging Face
Considérons le scénario fictif suivant d’un modèle dont l’auteur a été supprimé :
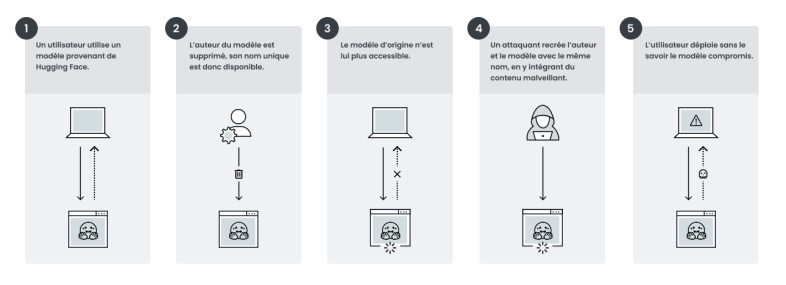
L’organisation DentalAI avait créé le modèle légitime toothfAIry. Ce modèle permettait d’analyser des images dentaires et de détecter avec précision les caries ainsi que d’autres anomalies dentaires. Grâce à son efficacité et à sa simplicité d’utilisation, il est rapidement devenu un outil apprécié des développeurs, des chercheurs en odontologie et des professionnels de santé. Au fil du temps, DentalAI/toothfAIry a été intégré à des outils de diagnostic, des plateformes médicales et même à des dépôts open source spécialisés en technologies de santé.
Mais les développeurs de DentalAI l’ont finalement supprimée de Hugging Face. Un acteur malveillant a remarqué cette opportunité et en a profité pour recréer l’organisation, puis y charger une version compromise du modèle toothfAIry sous le même nom.
En conséquence, tous les dépôts de code et pipelines continuant de référencer le modèle original se retrouvent désormais gravement exposés.
On pourrait croire que si un nom de modèle de confiance continue de fonctionner dans le code, c’est qu’il n’existe aucun risque de réutilisation malveillante de cet espace de noms. Il s’agit en fait d’une idée reçue. Des dépôts de code et des pipelines peuvent télécharger et déployer une version compromise à l’insu des développeurs. Ces modèles malveillants peuvent entraîner une série de conséquences imprévues : diagnostics erronés, ou encore accès non autorisé et persistant aux systèmes concernés par les attaquants.
La figure 2 illustre les étapes de ce scénario fictif.
Un autre vecteur d’attaque potentiel réside dans la manière dont Hugging Face gère le transfert de propriété des modèles.
Transfert de propriété dans Hugging Face
Hugging Face permet en effet de modifier l’auteur d’un modèle en transférant sa propriété d’un détenteur à un autre. Ce transfert génère un nouvel espace de noms pour le modèle – AIOrg/Translator_v1 devient AIOrgNew/Translator_v1, par exemple. Les utilisateurs peuvent alors déployer le modèle via ce nouvel identifiant. Toutefois, l’espace de noms d’origine reste lui aussi accessible pour le déploiement.
Lorsqu’un utilisateur soumet une requête à l’ancien espace de noms, Hugging Face le redirige automatiquement vers le nouvel espace. Cette redirection s’applique à tous les points d’accès : interface utilisateur (UI), Rest API et kits de développement logiciel (SDK).
Cette approche est logique et voulue : Hugging Face cherche à garantir la continuité des pipelines, même après un changement d’espace de noms. Mais, comme le montre le scénario précédent, si l’organisation détentrice du modèle original est supprimée, l’espace de noms redevient disponible pour un nouvel enregistrement.
Dans ce cas, si un acteur malveillant s’approprie cet espace de noms, le mécanisme de redirection est rompu : la version compromise du modèle prend alors le pas sur la version légitime.
Pour illustrer ce scénario fictif, reprenons l’exemple du domaine dentaire.
L’organisation Dentalligence a racheté DentalAI. Dans le cadre de cette acquisition, DentalAI a transféré l’ensemble de ses modèles d’IA vers l’organisation Dentalligence. Une fois le transfert effectué, les administrateurs de DentalAI ont supprimé l’organisation d’origine de Hugging Face, puisqu’elle était désormais entièrement intégrée à Dentalligence.
Tous les modèles auparavant publiés sous DentalAI (comme DentalAI/toothfAIry) sont alors devenus accessibles via leurs nouveaux chemins, tels que Dentalligence/toothfAIry. Pour assurer la continuité, Hugging Face a maintenu des redirections depuis les anciens espaces de noms vers les nouveaux, permettant aux utilisateurs de continuer à accéder aux modèles sans modifier leur code.
Mais un acteur malveillant a constaté que l’organisation DentalAI était de nouveau disponible. Il l’a recréée et y a téléchargé des modèles compromis, en reprenant exactement les mêmes noms que ceux auparavant utilisés par DentalAI.
Comme les noms de modèles originaux restaient valides et déployables durant toute la transition, les utilisateurs n’ont rien remarqué. Ils n’ont subi aucune interruption de service et n’ont pas eu à modifier leurs appels de modèles dans le code. Ainsi, une requête visant à télécharger DentalAI/toothfAIry redirigeait automatiquement vers Dentalligence/toothfAIry. Lorsque l’acteur malveillant a inséré sa version sous les anciens noms, les utilisateurs ont donc commencé à déployer les modèles compromis à la place des versions de confiance qu’ils avaient intégrées initialement.
Comparaison des scénarios
Des espaces de noms de modèles réutilisables codés en dur existent dans des milliers de projets open source. Ils se retrouvent aussi bien dans des dépôts populaires, largement étoilés, que dans d’autres appartenant à des organisations de premier plan. De tels modèles représentent en outre une menace pour les utilisateurs des principales plateformes d’IA.
Le tableau 1 résume les différences entre les deux scénarios.
| Suppression du propriétaire | Transfert de propriété | |
| Cause | L’auteur du modèle a été supprimé de Hugging Face. | Le modèle a été transféré à un nouveau propriétaire et l’ancien auteur a été supprimé de Hugging Face. |
| Expérience utilisateur | Les utilisateurs subiront des temps d’arrêt, le modèle n’existant plus. | Les utilisateurs ne seront pas affectés, leurs requêtes étant redirigées vers le nouveau modèle. |
| Codes HTTP lors de l’accès au modèle | 404 | 307 |
| Signes distinctifs | L’auteur du modèle n’est plus disponible sur Hugging Face. | Lorsqu’on tente d’accéder au modèle, Hugging Face redirige vers un autre auteur. En outre, l’ancien auteur n’est plus disponible. |
Tableau 1. Différences clés entre les modèles supprimés réutilisables et les modèles transférés réutilisables.
Réutilisation des espaces de noms de modèles en pratique
Étude de cas n° 1 : Vertex AI
Google Vertex AI est une plateforme de machine learning (ML) managée au sein de Google Cloud Platform (GCP). Les développeurs utilisent Vertex AI pour créer et mettre à l’échelle des modèles qui s’intègrent avec d’autres services Google Cloud.
Le Model Garden est une fonctionnalité clé de Vertex AI : il s’agit d’un dépôt centralisé de modèles pré entraînés provenant de Google, de tiers et de la communauté open source. Fait notable, il prend en charge le déploiement direct de modèles issus de Hugging Face. Concrètement, les utilisateurs peuvent sélectionner un modèle sur Hugging Face et le déployer sur Vertex AI en seulement quelques étapes, sans avoir à réaliser de packaging spécifique.
La figure 3 illustre le déploiement du modèle distilbert/distilgpt2.
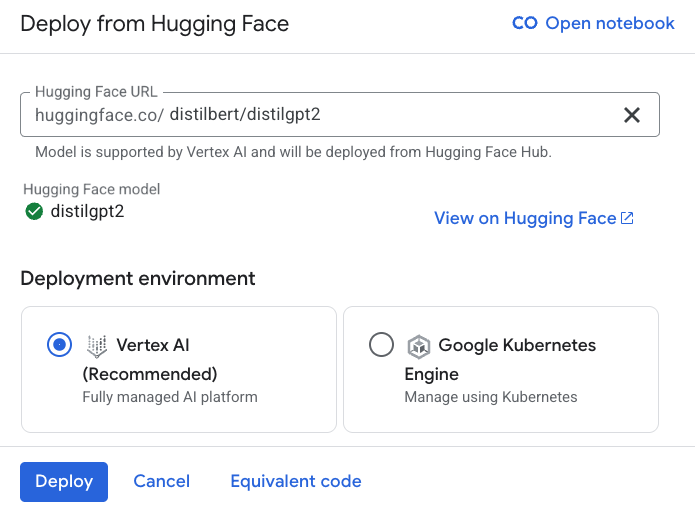
Il convient de noter que tous les modèles ne sont pas immédiatement déployables via Vertex AI. Une coche verte placée à côté du nom du modèle indique que Google l’a vérifié et qu’il peut être déployé.
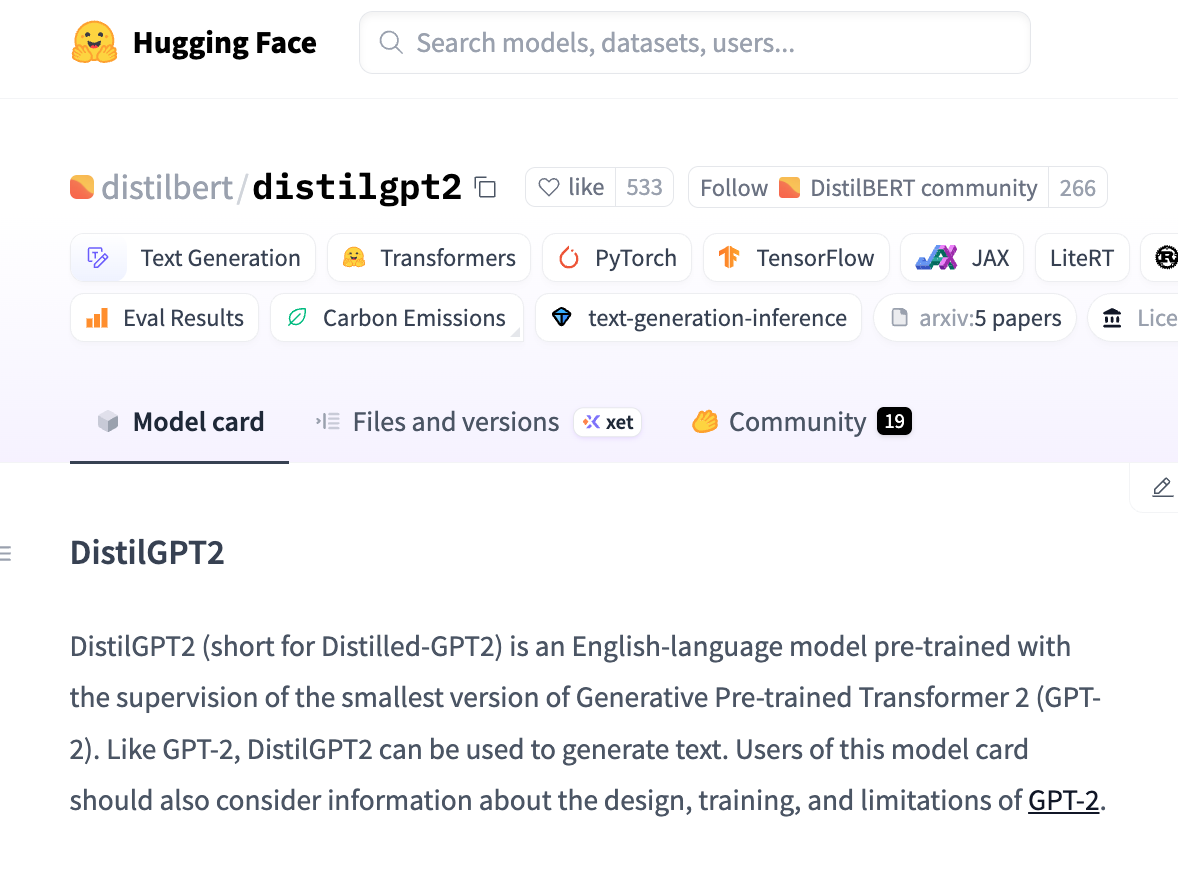
De plus, l’interface propose un lien direct vers la fiche du modèle sur Hugging Face, permettant aux utilisateurs de consulter rapidement la documentation, la licence et d’autres informations essentielles. La figure 4 présente un exemple de fiche de modèle pour distilbert/distilgpt2.
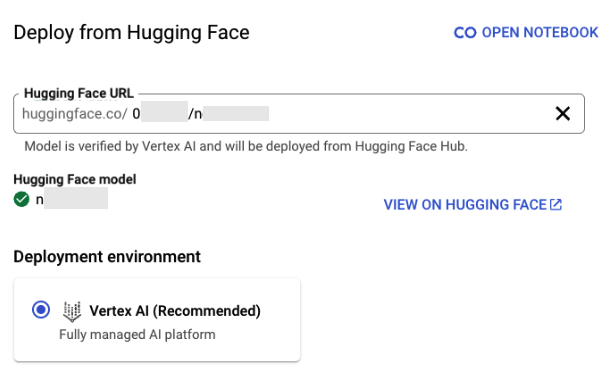
En examinant la liste des modèles proposés par Vertex AI pour un déploiement direct depuis Hugging Face, et en vérifiant si leurs auteurs originaux avaient été supprimés, nous avons identifié plusieurs modèles réutilisables. Ces modèles répondent à deux conditions :
- L’organisation originale a été supprimée de Hugging Face.
- Le modèle reste listé et validé par Vertex AI.
Les figures 5 et 6 illustrent un exemple de ce type de modèle, qui peut être déployé sur Vertex AI, bien que son auteur n’existe pas sur Hugging Face.
Nous avons ensuite procédé à l’enregistrement de l’un des espaces de noms d’auteur et créé un modèle portant le même nom, comme l’illustre la figure 7.
Après cette prise de contrôle, tout déploiement du modèle original aboutissait désormais au déploiement de notre nouveau modèle.
Pour démontrer l’impact potentiel de cette technique, nous avons intégré dans le modèle un payload déclenchant un reverse shell depuis la machine effectuant le déploiement vers nos serveurs. Une fois le modèle déployé par Vertex AI, nous avons obtenu un accès à l’infrastructure sous-jacente hébergeant le modèle – plus précisément, au terminal. La figure 8 montre le reverse shell depuis le terminal vers notre machine contrôlée.

L’environnement accessible était un conteneur dédié, doté d’un périmètre limité au sein de GCP. Après avoir démontré ce vecteur d’attaque, nous avons retiré le backdoor du dépôt du modèle.
Depuis que nous avons signalé ce problème à Google en février 2025, des analyses sont effectuées chaque jour pour identifier les modèles orphelins. Ces analyses apposent aux modèles concernés le statut « verification unsuccessful », les empêchant ainsi d’être déployés sur Vertex.
Étude de cas n° 2 : Azure AI Foundry
Azure AI Foundry est la plateforme de Microsoft dédiée au développement d’applications de machine learning et de GenAI. Elle fournit des outils couvrant les différentes étapes du cycle de vie de l’IA, de l’ingestion des données à l’entraînement des modèles, en passant par le déploiement et la supervision.
Azure AI Studio est notamment bâtie sur le Model Catalog, un hub regroupant des modèles fondamentaux proposés par Microsoft, des contributeurs open source et divers éditeurs. Le catalogue d’Azure AI Foundry permet aux utilisateurs de déployer et de personnaliser des modèles directement sur la plateforme. La figure 9 montre que de nombreux modèles de ce catalogue proviennent de Hugging Face.
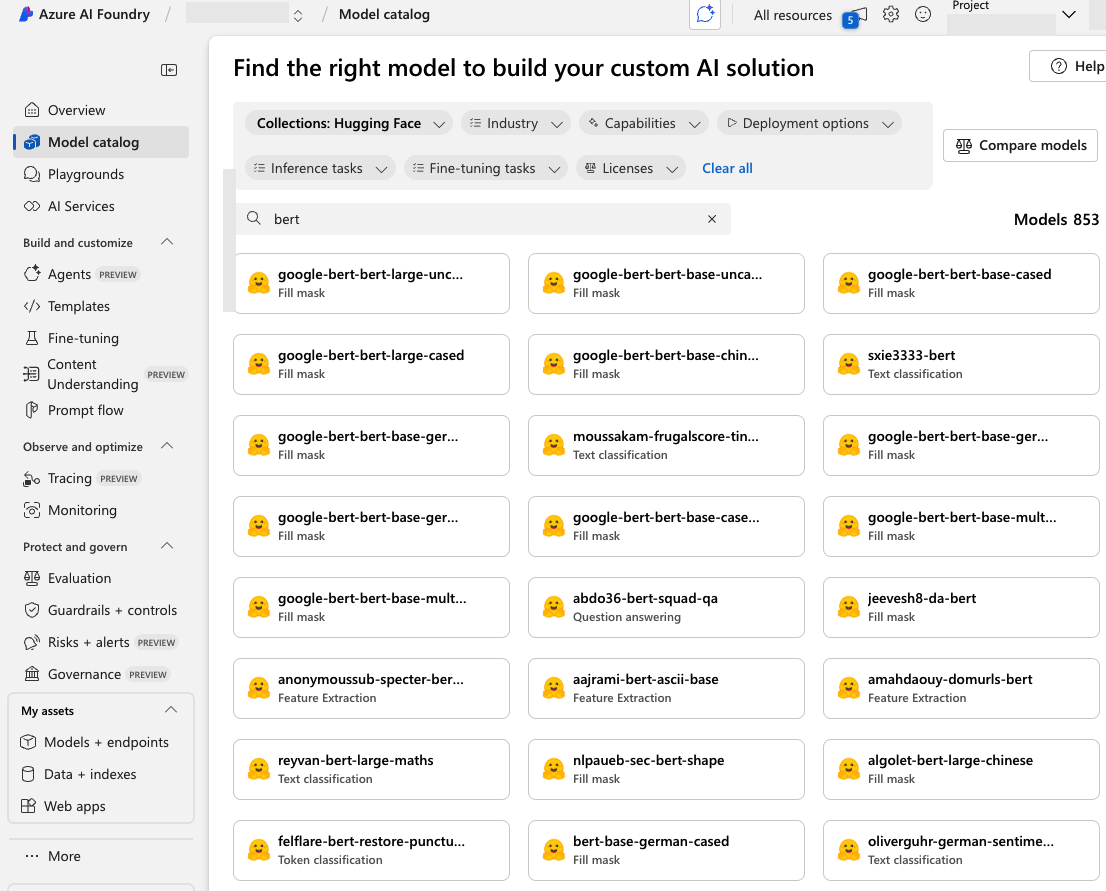
Nous avons passé en revue la liste des modèles disponibles dans Azure AI Foundry en nous concentrant sur ceux issus de Hugging Face. Pour chacun d’eux, nous avons vérifié si le compte de l’auteur original avait été supprimé. Là encore, nous avons identifié plusieurs modèles réutilisables – des modèles dont l’espace de noms n’était plus revendiqué, mais qui restaient disponibles pour le déploiement.
Pour démontrer le risque, nous avons réenregistré l’un de ces noms d’auteur non revendiqués sur Hugging Face et y avons téléchargé un modèle contenant un reverse shell. Lors du déploiement, le reverse shell s’est exécuté avec succès, nous donnant accès au terminal sous-jacent (cf. figure 10).
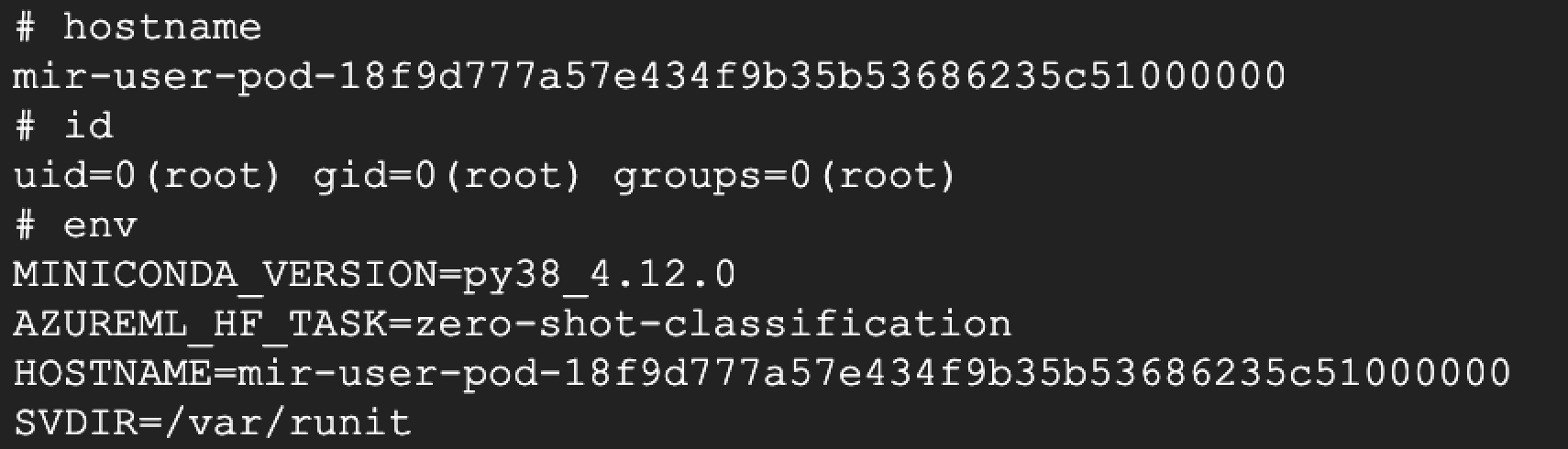
En exploitant ce vecteur d’attaque, nous avons obtenu des autorisations équivalentes à celles du terminal Azure. Cela nous a fourni un premier point d’accès à l’environnement Azure de l’utilisateur. Après avoir démontré ce vecteur d’attaque, nous avons retiré le backdoor du dépôt du modèle.
Étude de cas n° 3 : référentiels open source
Après avoir constaté l’impact de la réutilisation des espaces de noms de modèles sur les principaux services cloud d’IA, nous avons réalisé une recherche approfondie dans les référentiels open source. Nous souhaitions identifier les projets faisant référence à des modèles Hugging Face par des identifiants Author/ModelName disponibles pour réenregistrement.
De tels projets exposent leurs utilisateurs à des risques de sécurité majeurs. Les attaquants peuvent exploiter ces dépendances en repérant un identifiant Author/ModelName encore disponible, en le réenregistrant puis en y téléversant des fichiers malveillants. Ces derniers ont alors de fortes chances d’être déployés dans les environnements des utilisateurs lors de l’exécution ou du déploiement du projet.
Nous avons commencé par rechercher sur GitHub des référentiels open source contenant des méthodes SDK destinées à récupérer des modèles sur Hugging Face. Nous avons ensuite affiné la recherche en identifiant les noms de modèles référencés dans ces référentiels. Pour détecter les modèles réutilisables, nous avons vérifié si leur auteur avait été supprimé et pouvait être réenregistré.
Cette enquête a révélé des milliers de référentiels vulnérables, parmi lesquels plusieurs projets bien connus et largement étoilés. Ces projets incluent à la fois des modèles supprimés et des modèles transférés dont l’auteur original a disparu, laissant les utilisateurs dans l’ignorance de la menace – dans la mesure où les projets continuent de fonctionner normalement.
Les figures 11 et 12 illustrent la présence de modèles et de noms réutilisables dans des projets open source populaires.

Étude de cas n° 4 : la chaîne de fuite des registres de modèles
Jusqu’à présent, nous avons examiné des scénarios dans lesquels utilisateurs et développeurs récupèrent directement des modèles depuis Hugging Face. Qu’il s’agisse d’une plateforme d’IA managée ou d’un SDK open source, beaucoup d’environnements s’appuient sur Hugging Face comme source principale.
Cependant, d’autres registres de modèles – des systèmes centralisés qui gèrent le stockage, le versionnage et le cycle de vie des modèles de ML – importent eux aussi des modèles depuis Hugging Face et les proposent aux utilisateurs via leur catalogue.
Cela crée un risque sur la supply chain. Si un registre intègre des modèles réutilisables issus de Hugging Face, ces derniers peuvent se propager en aval. Les utilisateurs qui s’appuient sur ces registres risquent donc d’être exposés à des modèles compromis, sans jamais interagir directement avec Hugging Face.
Prenons l’exemple de Vertex AI. Comme nous l’avons vu plus haut, Vertex AI propose une intégration transparente pour déployer et utiliser des modèles Hugging Face dans l’environnement GCP. Les utilisateurs peuvent facilement récupérer un modèle via le SDK Vertex AI, comme l’illustre la figure 13.

Dans ce scénario, l’utilisateur obtient le modèle model_name directement depuis Vertex AI. Mais si ce modèle provient de Hugging Face et figure dans le Model Catalog, l’utilisateur peut, à son insu, accéder à un modèle infecté.
Kaggle est une autre plateforme détenue par Google qui intègre Hugging Face comme source de modèles. Il s’agit d’un hub reconnu pour la data science et le machine learning, qui propose des jeux de données, des notebooks et une large collection de modèles pré entraînés. La figure 14 montre que, dans son Model Catalog, Kaggle propose des milliers de modèles issus de Hugging Face pour le déploiement.
Comme pour les registres évoqués précédemment, Kaggle propose également plusieurs modèles vulnérables à la réutilisation d’espaces de noms, ce qui représente un risque immédiat pour ses utilisateurs.
Le défi de l’intégrité des modèles en matière d’IA
Assurer le suivi des modèles de ML est un défi complexe et permanent. Les développeurs mettent à jour, affinent, dupliquent et republient constamment leurs modèles, souvent sur plusieurs plateformes et au sein de différentes organisations. Nous avons observé des opportunités de réutilisation d’espaces de noms de modèles sur divers éléments de ces systèmes complexes et multi-composants. Cela concerne non seulement les déploiements de modèles, qui représentent le risque le plus immédiat et le plus significatif, mais également les fiches de modèles, la documentation, les paramètres par défaut et les notebooks d’exemples.
Le fait de constater le même problème de réutilisation de modèles dans GCP, Azure et de nombreux projets open source met en lumière l’un des aspects les plus critiques – et trop souvent négligés – de la sécurité de l’IA et du ML : s’assurer que le modèle utilisé est bien celui que l’on croit utiliser. Qu’un projet récupère un modèle depuis un registre public, le réemploie à partir d’un pipeline interne ou le déploie via un service managé, le risque demeure qu’il ait été remplacé, altéré ou exploité via un détournement de redirection.
Les modèles peuvent provenir de registres variés, et pas uniquement de Hugging Face. Le Model Garden de Vertex AI, le Model Catalog d’Azure AI Foundry et Kaggle proposent tous une large gamme de modèles, dont beaucoup proviennent directement de Hugging Face.
Cette intégration, bien que pratique, introduit des risques. Les développeurs qui s’appuient sur les catalogues de modèles réputés des grands services d’IA hébergés dans le cloud peuvent, à leur insu, déployer des modèles malveillants initialement hébergés sur Hugging Face, sans jamais interagir directement avec cette plateforme.
À leur crédit, toutes ces plateformes déploient des efforts considérables pour sécuriser leurs registres de modèles. Toutefois, comme nous l’avons démontré, aucun système n’est totalement à l’abri d’un détournement d’espace de noms ou de vulnérabilités liées à la supply chain. Même avec des garde-fous solides, un simple cas limite non anticipé peut conduire à une exploitation destructrice.
Garantir la sécurité des outils d’IA n’est pas uniquement la responsabilité des fournisseurs de plateformes. Les développeurs doivent eux aussi prendre des mesures actives pour sécuriser leurs pipelines et leurs environnements.
Mesures pratiques pour sécuriser le cycle de vie du ML
Nous avons exploré certains des défis intrinsèques liés à la sécurisation des pipelines qui alimentent les modèles de ML. De l’ingestion des données au déploiement, garantir l’intégrité à chaque étape est essentiel. La bonne nouvelle, c’est que nous ne sommes pas démunis face à ces complexités. Des mesures concrètes peuvent être mises en place pour améliorer de manière significative la sécurité et la fiabilité des systèmes d’IA. Voici quelques pratiques clés.
- Version pinning (épinglage de version) : l’utilisation de méthodes telles que from_pretrained("Author/ModelName") pour récupérer des modèles peut entraîner des comportements inattendus, des problèmes de stabilité, voire l’intégration de modèles malveillants, en raison du téléchargement automatique de la dernière version disponible. Une solution consiste à « épingler » le modèle sur un commit spécifique grâce au paramètre revision. La commande from_pretrained("Author/ModelName", revision="abcdef1234567890") garantit que le modèle est dans l’état attendu et empêche tout changement de comportement imprévu. Cela permet au développeur d’assurer la cohérence du modèle, pour le débogage comme pour l’exécution.
- Clonage et stockage contrôlé des modèles : pour les environnements hautement sensibles ou en production, nous recommandons de cloner le référentiel du modèle dans un espace de confiance, comme un stockage local, un registre interne ou un espace cloud sécurisé. Cette approche permet de découpler le chargement du modèle de toute source externe, éliminant ainsi le risque de modifications en amont ou de problèmes de connectivité. Ce clonage doit bien entendu intervenir uniquement après un processus rigoureux d’analyse et de vérification.
- Recherche de références réutilisables : les références à des modèles dans les référentiels de code doivent être scannées et traitées comme n’importe quelle autre dépendance soumise à des politiques et à des revues de sécurité. L’analyse doit être exhaustive, car les modèles peuvent apparaître dans des emplacements inattendus, tels que des arguments par défaut, des docstrings ou des commentaires. Anticiper et analyser proactivement les bases de code à la recherche de références de modèles réduit le risque d’attaques sur la supply chain liées à la réutilisation d’espaces de noms.
Conclusion : les nouvelles réalités de la supply chain de l’IA
Nous avons montré comment un attaquant pouvait réenregistrer et réutiliser des identifiants de modèles sur Hugging Face afin d’exécuter du code à distance au sein de plateformes d’IA populaires comme Google Vertex AI, Azure AI Foundry et divers projets open source. Dans les deux cas, le problème tient au fait qu’un simple nom de modèle ne suffit pas à garantir son intégrité ou sa fiabilité.
Nous avons abordé cette problématique avec les fournisseurs mentionnés dans cet article. La réutilisation d’espaces de noms de modèles est un problème complexe – et ce risque existe toujours. Il ne s’agit pas d’un problème ponctuel, mais d’un défi systémique qui touche à la façon dont la communauté de l’IA gère et valide l’intégrité des modèles partagés. Ce défi dépasse largement la seule gestion des espaces de noms et nous oblige à poser des questions sur la sécurité fondamentale d’une infrastructure d’IA en pleine évolution.
Les utilisateurs peuvent renforcer leur sécurité face aux menaces décrites ci-dessus en mettant en œuvre le version pinning, en clonant les référentiels de modèles dans des espaces de stockage de confiance et en analysant les références réutilisables.
Les organisations peuvent bénéficier d’un accompagnement dans l’évaluation de leur posture de sécurité grâce à l’Évaluation de la sécurité du cloud de l’Unit 42.
Notre approche les aide également à sécuriser l’usage et le développement de l’IA.
Si vous pensez que votre entreprise a pu être compromise ou si vous faites face à une urgence, contactez l’équipe Unit 42 de réponse à incident ou composez l’un des numéros suivants :
- Amérique du Nord : Gratuit : +1 (866) 486-4842 (866.4.UNIT42)
- Royaume-Uni : +44 20 3743 3660
- Europe et Moyen-Orient : +31.20.299.3130
- Asie : +65.6983.8730
- Japon : +81 50 1790 0200
- Australie : +61.2.4062.7950
- Inde : 000 800 050 45107
Palo Alto Networks a partagé ces conclusions avec les autres membres de la Cyber Threat Alliance (CTA). Les membres de la CTA s’appuient sur ces renseignements pour déployer rapidement des mesures de protection auprès de leurs clients et perturber de manière coordonnée les activités des cybercriminels. Cliquez ici pour en savoir plus sur la Cyber Threat Alliance.
Pour aller plus loin
- Documentation sur le transfert de propriété – Hugging Face
SOMMAIRE
Associé Études sur la cybersécurité du cloud Ressources








