
Executive Summary
We identified vulnerabilities in three open-source artificial intelligence/machine learning (AI/ML) Python libraries published by Apple, Salesforce and NVIDIA on their GitHub repositories. Vulnerable versions of these libraries allow for remote code execution (RCE) when a model file with malicious metadata is loaded.
Specifically, these libraries are:
- NeMo: A PyTorch-based framework created for research purposes that is designed for the development of diverse AI/ML models and complex systems created by NVIDIA
- Uni2TS: A PyTorch library created for research purposes that is used by Salesforce's Morai, a foundation model for time series analysis that forecasts trends from vast datasets
- FlexTok: A Python-based framework created for research purposes that enables AI/ML models to process images by handling the encoding and decoding functions, created by researchers at Apple and the Swiss Federal Institute of Technology’s Visual Intelligence and Learning Lab
These libraries are used in popular models on HuggingFace with tens of millions of downloads in total.
The vulnerabilities stem from libraries using metadata to configure complex models and pipelines, where a shared third-party library instantiates classes using this metadata. Vulnerable versions of these libraries simply execute the provided data as code. This allows an attacker to embed arbitrary code in model metadata, which would automatically execute when vulnerable libraries load these modified models.
As of December 2025, we have found no malicious examples using these vulnerabilities in the wild. Palo Alto Networks notified all affected vendors in April 2025 to ensure they had a chance to implement mitigations or resolve the issues before publication.
- NVIDIA issued CVE-2025-23304, rated High severity, and released a fix in NeMo version 2.3.2
- The researchers who created FlexTok updated their code in June 2025 to resolve the issues
- Salesforce issued CVE-2026-22584, rated High severity, and deployed a fix on July 31, 2025
These vulnerabilities were discovered by Prisma AIRS, which is able to identify models leveraging these vulnerabilities and extract their payloads.
Additionally, Palo Alto Networks customers are better protected from the threats discussed above through the following products and services:
- Cortex Cloud’s Vulnerability Management
- The Unit 42 AI Security Assessment can help organizations reduce AI adoption risk, secure AI innovation and strengthen AI governance.
- If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
| Related Unit 42 Topics | Python, LLMs, Machine Learning |
AI/ML Model Formats
AI/ML training and inference pipelines depend on saving complex internal states, such as learned weights and architecture definitions. These internal states are saved as model artifacts, and the artifacts must be shared between producers and consumers. Libraries provide built-in mechanisms to serialize these artifacts.
Python libraries for AI/ML have long depended on functionality from the pickle module in the Python standard library to store and load Python objects to and from files. This module serializes Python objects by creating a simple program to reconstruct the objects, and the pickle module is executed when the Python objects are loaded. Because the pickle module executes code when loading files, using it brings significant security risks.
The PyTorch library’s file format simply embeds .pickle files in a container format. Other libraries like scikit-learn use .pickle or other extensions used for pickle (like .joblib) on their own. Most popular AI/ML libraries clearly document these risks and provide mature mitigations to prevent the execution of unexpected code by default.
Security Issues in New Model Formats
Newer formats have been developed to address the security issues of these pickle-based formats. These “safe” formats largely achieve this by only supporting the serialization of model weights or by representing pipelines as data instead of code, using formats like JSON. For example, HuggingFace’s safetensors format only allows for the storage of model weights and a single JSON object to store model metadata.
Older formats have also moved away from relying on the pickle module. For example, PyTorch will only load model weights by default. If pickle loading is enabled, PyTorch will only execute functions from a predefined allow list that should prevent the execution of arbitrary code.
While these newer formats and updates remove the ability to serialize pipelines as code, they do not make applications and libraries using these models impervious to traditional exploits. Security researchers at JFrog have identified vulnerabilities in applications that use these formats using well-known techniques such as XSS and path traversal.
Technical Analysis
While newer formats have removed the ability to store model state and configurations as code, researchers still have use cases for serializing that information. Because these libraries are large and the configurations of their classes can be complex, many libraries use third-party tools to accomplish this.
Hydra is a Python library maintained by Meta that is a tool commonly used to serialize model state and configuration information.
We identified three open-source AI/ML Python libraries used by models on HuggingFace that leverage Hydra to load these configurations from model metadata in a way that allows for arbitrary code execution:
- NeMo: A PyTorch-based framework created for research purposes designed for the development of diverse AI/ML models and complex systems created by NVIDIA
- Uni2TS: A PyTorch library created for research purposes used by Salesforce's Morai, a foundation model for time series analysis that forecasts trends from vast datasets
- FlexTok: A Python-based framework created for research purposes that enables AI/ML models to process images by handling the encoding and decoding functions, created by researchers at Apple and the Swiss Federal Institute of Technology’s Visual Intelligence and Learning Lab
Hydra
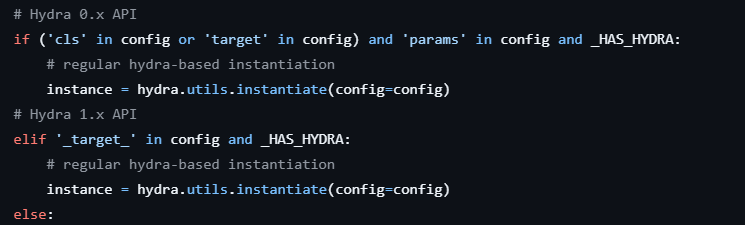
All the vulnerabilities we identified use the hydra.utils.instantiate() function, which is intended to “instantiate different implementations of an interface.”
The Hydra API takes as arguments a configuration object (like a Python dictionary or an OmegaConf object) that describes the target interface to instantiate and optional *args and **kwargs parameters to be passed to that interface. This configuration expects a _target_ value specifying the class or callable to instantiate, and an optional _args_ value defining arguments for _target_.
In each of the cases we identified, hydra.utils.instantiate() is only used to instantiate instances of library classes with simple arguments stored in metadata. Figure 1 shows an example of the metadata NeMo passes to the instantiate() function.
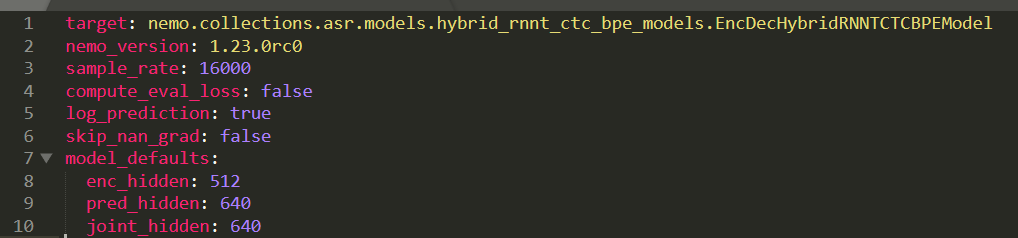
What these libraries appear to have overlooked is that instantiate() doesn’t just accept the name of classes to instantiate. It also takes the name of any callable and passes it the provided arguments.
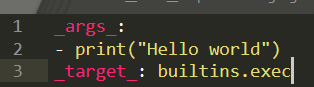
By leveraging this, an attacker can more easily achieve RCE using Python's built-in functions like eval() and os.system(). In all the proofs of concept we used to test these vulnerabilities, we employed a payload using builtins.exec() as the callable and a string containing Python as an argument.
Since these issues were first identified, Hydra has been updated to add a warning to its documentation stating that RCE is possible when using instantiate() and to add a simple block-list mechanism. This mechanism works by comparing the _target_ value against a list of dangerous functions like builtins.exec() before it is called.
Because this mechanism uses exact matches against import targets before they are imported, it is trivially evaded by using implicit imports from the Python standard library (e.g., enum.bltns.eval) or from the target application (e.g., nemo.core.classes.common.os.system). However, the Hydra documentation clearly states that this mechanism is not exhaustive and shouldn’t be relied on solely to prevent the execution of malicious code. As of January 2026, this block-list mechanism is not yet available in a Hydra release.
NeMo
NVIDIA has been developing the NeMo library since 2019, as a “scalable and cloud-native generative AI framework.” NeMo uses its own file formats with the .nemo and .qnemo file extensions, which are simply TAR files containing a model_config.yaml file that stores model metadata along with a .pt file or a .safetensors file, respectively.
The main entry points for loading these .nemo model files are restore_from() and from_pretrained(). There are several layers of abstraction, but ultimately, the serialization mix-in is used to handle loading the model configuration once it has been loaded from the embedded model_config.yaml file. Figure 2 shows the vulnerable call to hydra.utils.instantiate().
At no point is any sanitization done on the metadata before it is passed to instantiate(). Because the call is made before the target model class begins its initialization, it is easy to create a model_config.yaml file with a working payload, as shown in Figure 3.
NeMo also integrates with HuggingFace and supports passing the name of a model hosted on HuggingFace to from_pretrained(), which is the way most NeMo models on HuggingFace appear to be used. This call is also vulnerable because once the model is downloaded from HuggingFace, the same code paths are followed.
As of January 2026, over 700 models on HuggingFace from a variety of developers are provided in NeMo format NeMo. Many of these models are among the most popular on HuggingFace, such as NVIDIA’s parakeet. This vulnerability appears to have existed since at least 2020.
The PyTorch format that NeMo extends supports code execution with embedded .pickle files, but it clearly documents this. This PyTorch format also disables arbitrary execution by default and offers several safeguards, such as allowlisting usable modules during the loading of .pickle files. NeMo does allow for the loading of embedded .pickle files inside of the PyTorch files embedded in .nemo files, but the built-in allow list mechanism in PyTorch should prevent arbitrary code execution.
NVIDIA acknowledged this issue, released a CVE record CVE-2025-23304 rated High severity and issued a fix in NeMo version 2.3.2.
To address this issue, NeMo added a safe_instantiate function to validate the _target_ values from Hydra configurations before they are executed. This function recursively looks for _target_ values in the configuration and validates each one, which prevents using nested objects for RCE. A new _is_target_allowed function first checks each _target_ value against an allow list of prefixes containing package names from NeMo, PyTorch and related libraries.
This prefix check alone would not be sufficient to prevent implicit imports of dangerous modules, as is the case for Hydra’s new block-list mechanism. However, NeMo additionally imports each target using Hydra and checks to see whether:
- It is a subclass of an expected class
- The import has a module name from an allow list of expected modules
By checking the actual imported value against these allow lists, NeMo ensures only expected targets are executed. For example, the target nemo.core.classes.common.os.system resolves to the posix module, which is clearly not part of the NeMo library.
Uni2TS
In 2024, Salesforce’s AI research team published an article titled Unified Training of Universal Time Series Transformers, which introduced a set of models that were published on HuggingFace. This research and the use of these models depend on uni2TS, an open-source Python library that accompanied the Salesforce article.
The uni2TS library exclusively works with .safetensors files, which were explicitly designed to provide a safe alternative to model formats that allow for code execution. The safetensors format also does not explicitly support storing model or pipeline configurations.
To facilitate storing these configurations, libraries such as HuggingFace’s huggingface_hub use a config.json file stored in a model’s repository. For models using classes in one of HuggingFace’s core ML libraries, this is done securely because only parameters that can be stored directly in JSON primitive types are used. These values are then passed to a predefined, hard-coded set of classes.
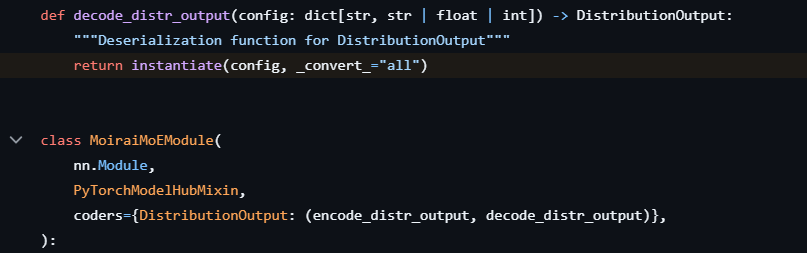
However, huggingface_hub provides a PyTorchModelHubMixin interface for creating custom model classes that can be integrated with the rest of their framework. As part of this interface, values are read from the packaged config.json file and passed to the model class.
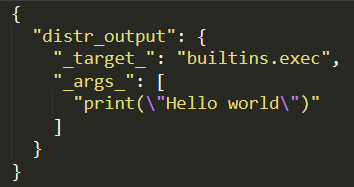
This interface provides a little-used mechanism for registering functions called coders, which process specific arguments before they are passed to the class. The uni2TS library leverages this mechanism to decode the configuration of a specific argument using a call to hydra.utils.instantiate() before it is passed to the target class, shown in Figure 4.
This code is executed when one of the published models is loaded using either MoraiModule.from_pretrained() or MoraiMoEModule.from_pretrained(). By adding our payload to the config.json file packaged with models using uni2TS as shown in Figure 5, RCE can be achieved when the model is loaded.
The Salesforce models using these libraries have hundreds of thousands of downloads so far on Hugging Face. Several adaptations of these models have also been published on HuggingFace by other users. No evidence of malicious activity involving these models has been discovered.
Salesforce has acknowledged this issue, released a CVE record CVE-2026-22584, rated High severity, and issued a fix on July 31. This fix implements an allow list and a strict validation check to ensure only explicitly permitted modules can be executed.
ml-flextok
Early in 2025, Apple and the Swiss Federal Institute of Technology’s Visual Intelligence and Learning Lab (EPFL VILAB) published research that introduced a supporting Python library called ml-flextok. Like uni2TS, ml-flextok works exclusively with the safetensors format and extends PyTorchModelHubMixin. It can also load metadata from a config.json file included in the model repository. This library also supports loading configuration data from the .safetensors file directly, storing this information in the metadata section of the file under the __metadata__ key.
Because the safetensors format represents metadata as a dictionary with string keys and string values, and because the model configuration depends on lists of parameters, a secondary encoding must be used. Ml-flextok leverages Python as this secondary encoding and uses ast.literal_eval() in the Python standard library to decode the metadata.
As documented, this function does not allow for arbitrary code execution but is susceptible to attacks causing memory exhaustion, excessive CPU consumption and process crashes. After the metadata has been decoded, ml-flextok directly passes it to hydra.utils.instantiate().
If the model is loaded from HuggingFace, this metadata is read from config.json and is not double-encoded since complex structures are supported. This JSON data is loaded as a dictionary, and specific sections are passed directly to instantiate().
In both cases, payloads are created with names matching instantiate() arguments. Depending on whether the payload is added to the .safetensors file directly or in the packaged config.json file, the encoding and placement of the payload differ slightly, but the payload is still straightforward. Figure 6 shows a payload placed in a .safetensors file's metadata.

As of January 2026, no models on HuggingFace appear to be using the ml-flextok library other than those models published by EPFL VILAB, which have tens of thousands of downloads in total.
Apple and EPFL VILAB have updated their code to resolve these issues by using YAML to parse their configurations and adding an allow list of classes they will pass to Hydra’s instantiate() function. They have also updated their documentation to indicate that strings stored in model files are executed as code and only models from trusted sources should be loaded.
Conclusion
Palo Alto Networks has not identified any model files leveraging these vulnerabilities for attacks in the wild. However, there is ample opportunity for attackers to leverage them.
It is common for developers to create their own variations of state-of-the-art models with different fine-tunings and quantizations, often from researchers unaffiliated with any reputable institution. Attackers would just need to create a modification of an existing popular model, with either a real or claimed benefit, and then add malicious metadata.
Prior to this finding, there was no indication that these libraries could be insecure or that only files from trusted sources should be loaded. HuggingFace does not currently make the contents of the metadata for these files easily accessible to users as it does in other cases (e.g., APIs referenced in .pickle files). Neither does it flag files using the safetensors or NeMo formats as being potentially unsafe.
Because the latest advances in this space often require code and not just model weights, there is a proliferation of supporting libraries. In October 2025, we identified over a hundred different Python libraries used by models on HuggingFace, almost 50 of which use Hydra in some manner. While these formats on their own may be secure, there is a very large attack surface in the code that consumes them.
Palo Alto Networks Protection and Mitigation
Palo Alto Networks customers are better protected from the threats discussed above through the following products:
- Prisma AIRS is able to identify models leveraging these vulnerabilities and extract their payloads.
- Cortex Cloud’s Vulnerability Management identifies and manages base images for cloud virtual machine and containerized environments. This allows for identification and alerting of vulnerabilities and misconfigurations, then provides remediation tasks for identified base level container images. The Cortex Cloud Agent can also detect the runtime operations discussed within this article.
- The Unit 42 AI Security Assessment can help organizations reduce AI adoption risk, secure AI innovation and strengthen AI governance.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 000 800 050 45107
- South Korea: +82.080.467.8774
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Additional Resources
- Hydra documentation – Hydra
- NeMo source code – NVIDIA-NeMo on GitHub
- uni2ts source code – SalesforceAIResearch on GitHub
- ml-flextok source code – Apple on GitHub
- Libraries of NeMo models – HuggingFace
Table of Contents
Related Vulnerabilities Resources

 High Profile Threats
High Profile Threats







