
Last week (2019-02-11) a new vulnerability in runC was reported by its maintainers, originally found by Adam Iwaniuk and Borys Poplawski. Dubbed CVE-2019-5736, it affects Docker containers running in default settings and can be used by an attacker to gain root-level access on the host.
Aleksa Sarai, one of runC’s maintainers, found that the same fundamental flaw exists in LXC. As opposed to Docker though, only privileged LXC containers are vulnerable. Both runC and LXC were patched and new versions were released.
The vulnerability gained a lot of traction and numerous technology sites and commercial companies addressed it in dedicated posts. Here at Twistlock, our CTO John Morello wrote an excellent piece with all the relevant details and the mitigations offered by the Twistlock platform.
Initially, the official exploit code wasn’t to be released publicly until 2019-02-18, in order to prevent malicious parties from weaponizing it before users have had some time to update. In the following days though, several people decided to release their own exploit code. That led the runC team to eventually release their exploit code earlier (2019-02-13) since – as they put it – “the cat was out of the bag”.
This post aims to be a comprehensive technical deep dive into the vulnerability and it’s various exploitation methods.
So What Is runC?
RunC is a container runtime originally developed as part of Docker and later extracted out as a separate open source tool and library. As a “low level” container runtime, runC is mainly used by “high level” container runtimes (e.g. Docker) to spawn and run containers, although it can be used as a stand-alone tool.
“High level” container runtimes like Docker will normally implement functionalities such as image creation and management and will use runC to handle tasks related to running containers – creating a container, attaching a process to an existing container (docker exec) and so on.
Procfs
To understand the vulnerability, we need to go over some procfs basics. The proc filesystem is a virtual filesystem in Linux that presents information primarily about processes, typically mounted to /proc. It is virtual in a sense that it does not exist on disk. Instead, the kernel creates it in memory. It can be thought of as an interface to system data that the kernel exposes as a filesystem. Each process has its own directory in procfs, at /proc/[pid]:
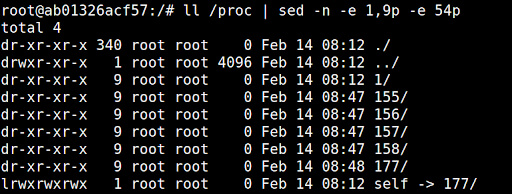
As shown in the image above, /proc/self is a symbolic link to the directory of the currently running process (in this case pid 177). Each process’s directory contains several files and directories with information on the process. For the vulnerability, the relevant ones are:
- /proc/self/exe – a symbolic link to the executable file the process is running, and ;
- /proc/self/fd – a directory containing the file descriptors open by the process.
For example, by listing the files under /proc/self using ls /proc/self one can see that /proc/self/exe points to the ‘ls’ executable.
![]()
That makes sense as the one accessing /proc/self is the ‘ls’ process that our shell spawned.
The Vulnerability
Let’s go over the vulnerability overview given by the runC team:
The vulnerability allows a malicious container to (with minimal user interaction) overwrite the host runc binary and thus gain root-level code execution on the host. The level of user interaction is being able to run any command ... as root within a container in either of these contexts:
- Creating a new container using an attacker-controlled image.
- Attaching (docker exec) into an existing container which the attacker had previous write access to.
Those two scenarios might seem different, but both require runC to spin up a new process in a container and are implemented similarly. In both cases, runC is tasked with running a user-defined binary in the container. In Docker, this binary is either the image’s entry point when starting a new container, or docker exec’s argument when attaching to an existing container.
When this user binary is run, it must already be confined and restricted inside the container, or it can jeopardize the host. In order to accomplish that, runC creates a ‘runC init’ subprocess which places all needed restrictions on itself (such as entering or setting up namespaces) and effectively places itself in the container. Then, the runC init process, now in the container, calls the execve syscall to overwrite itself with the user requested binary.

This is the method used by runC both for creating new containers and for attaching a process to an existing container.
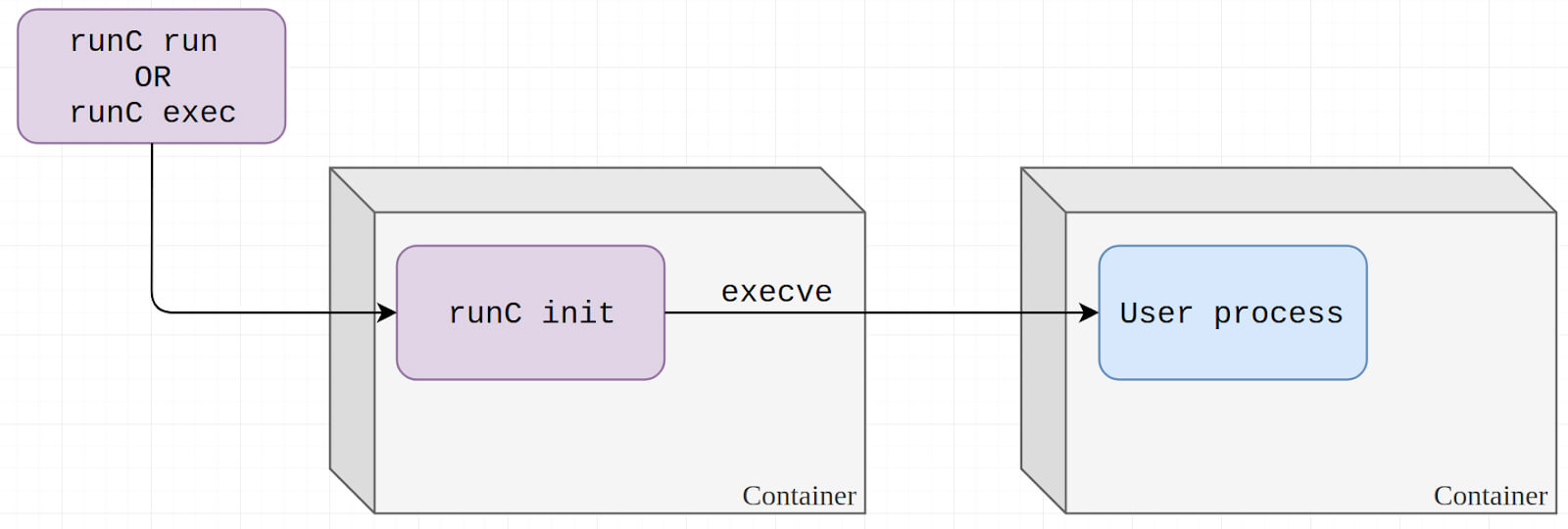
The researchers who revealed the vulnerability discovered that an attacker can trick runC into executing itself by asking it to run /proc/self/exe, which is a symbolic link to the runC binary on the host.
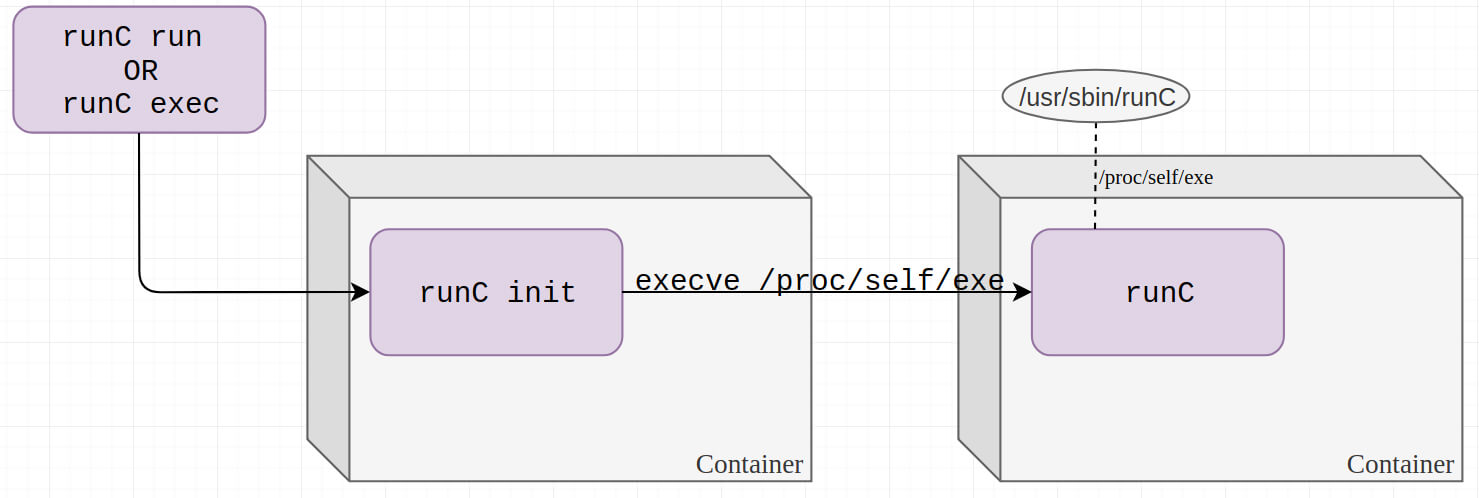
An attacker with root access in the container can then use /proc/[runc-pid]/exe as a reference to the runC binary on the host and overwrite it. Root access in the container is required to perform this attack as the runC binary is owned by root.
The next time runC is executed, the attacker will achieve code execution on the host. Since runC is normally run as root (e.g. by the Docker daemon), the attacker will gain root access on the host.
Why not runC init?
The image above might mislead some to believe the vulnerability (i.e. tricking runC into executing itself) is redundant. That is, why can’t an attacker simply overwrite /proc/[runc-init-pid]/exe instead?
A patch for a similar runC vulnerability, CVE-2016-9962, mitigates this kind of attack.
CVE-2016-9962 revealed that the runC init process possessed open file descriptors from the host which could be used by an attacker in the container to traverse the host’s filesystem and thus break out of the container. Part of the patch for this flaw was setting the runc init process as ‘non-dumpable’ before it entering the container.
In the context of CVE-2019-5736, the ‘non-dumpable’ flag denies other processes from dereferencing /proc/[pid]/exe, and therefore mitigates overwriting the runC binary through /proc/[runc-init-pid]/exe [1]. Calling execve drops this flag though, and hence the new runC process’ /proc/[runc-pid]/exe is accessible.
The Symlink Problem
The vulnerability may appear to contradict the way symbolic links are implemented in Linux.
Symbolic links simply hold the path to their target. For a runC process, /proc/self/exe should contain something like /usr/sbin/runc.
When a symlink is accessed by a process, the kernel uses the path present in the link to find the target under the root of the accessing process.
That begs the question – when a process in the container opens the symbolic link to the runC binary, why doesn’t the kernel searches for the runC path inside the container root?
The answer is that /proc/[pid]/exe does not follow the normal semantics for symbolic links. Technically this might count as a violation of POSIX, but as I mentioned earlier procfs is a special filesystem. When a process opens /proc/[pid]/exe, there is none of the normal procedure of reading and following the contents of a symlink. Instead, the kernel just gives you access to the open file entry directly.
Exploitation
Soon after the vulnerability was reported, when no POCs were publicly released yet, I attempted to develop my own POC based on the detailed description of the vulnerability given in the LXC patch addressing it. You can find the complete POC code here.
Let’s break down LXC’s description of the vulnerability:
when runC attaches to a container the attacker can trick it into executing itself. This could be done by replacing the target binary inside the container with a custom binary pointing back at the runC binary itself. As an example, if the target binary was /bin/bash, this could be replaced with an executable script specifying the interpreter path #!/proc/self/exe
The ‘#!’ syntax is called shebang and is used in scripts to specify an interpreter. When the Linux loader encounters the shebang, it runs the interpreter instead of the executable.
As seen in the video, the program finally executed by the loader is:
interpreter [optional-arg] executable-path
When the user runs something like docker exec container-name /bin/bash, the loader will recognize the shebang in the modified bash and execute the interpreter we specified – /proc/self/exe, which is a symlink to the runC binary.
We can proceed to overwrite the runC binary from a separate process in the container through /proc/[runc-pid]/exe.
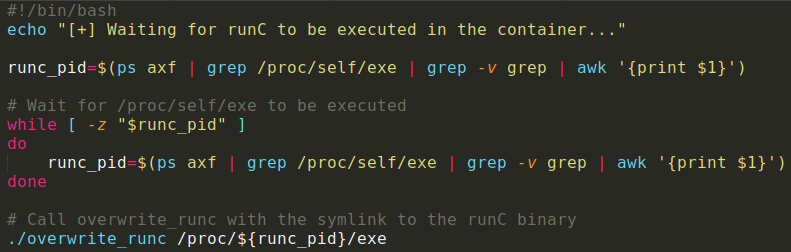
The attacker can then proceed to write to the target of /proc/self/exe to try and overwrite the runC binary on the host. However in general, this will not succeed as the kernel will not permit it to be overwritten whilst runC is executing.
Basically, we cannot overwrite the runC binary while a process is running it. On the other hand, if the runC process exits, /proc/[runc-pid]/exe will vanish and we will lose the reference to the runC binary. To overcome this, we open /proc/[runc-pid]/exe for reading in our process, which creates a file descriptor at /proc/[our-pid]/fd/3.
We then wait for the runC process to exit, and proceed to open /proc/[our-pid]/fd/3 for writing, and overwrite runC.
Here is the code for overwrite_runc, shortened for brevity:
Let’s see some action! The exploit output shows the steps taken to overwrite runC. You can see that the runC process is running as pid 20054. The video can also be seen here.
This method has one setback though – it requires an additional process to run the attacker code. Since containers are started with only one process (i.e. the Docker’s image entry point), this approach couldn’t be used to create a malicious image that will compromise the host when run.
Some other POCs you might have seen that implement a similar approach are Frichetten’s and feexd’s.
Shared Libraries Approach
A different exploitation method is used in the official POC released by runC’s maintainers and is superior to POCs similar to mine since it can be implemented to compromise the host through two separate methods:
- When a user execs a command into an existing attacker controlled container
- When a user runs a malicious image
We’ll now look into building a malicious image since the previous POC already demonstrated the first scenario. The POC I wrote for this method is heavily based on q3k’s POC, which, to the best of my knowledge, was the first published malicious image POC. You can view the full POC code here.
Let’s go over the Dockerfile used to build the malicious image. First, the entry point of the image is set to /proc/self/exe in order to trick runC into executing itself when the image is run.
|
1 2 3 4 |
# Create a symbolic link to /proc/self/exe and set it as the image entrypoint RUN set -e -x ;\ ln -s /proc/self/exe /entrypoint ENTRYPOINT [ "/entrypoint" ] |
RunC is dynamically linked to several shared libraries at run time, which can be listed using the ldd command.

When the runC process is executed in the container, those libraries are loaded into the runC process by the dynamic linker. It is possible to substitute one of those libraries with a malicious version, that will overwrite the runC binary upon being loaded into the runC process.
Our Dockerfile builds a malicious version of the libseccomp library:
|
1 2 3 4 5 6 7 8 9 |
# Append the run_at_link function to the libseccomp-2.3.1/src/api.c file and build libseccomp ADD run_at_link.c /root/run_at_link.c RUN set -e -x ;\ cd /root/libseccomp-2.3.1 ;\ cat /root/run_at_link.c >> src/api.c ;\ DEB_BUILD_OPTIONS=nocheck dpkg-buildpackage -b -uc -us ;\ dpkg -i /root/*.deb |
The Dockerfile appends the content of run_at_link.c to one of libsecomp’s source files. Subsequently, the malicious libsecomp is built.

The constructor attribute (a GCC-specific syntax) indicates that the run_at_link function is to be executed as an initialization function [2] for libseccomp after the dynamic linker loads the library into the runC process. Since run_at_link will be executed by the runC process, it can access the runC binary at /proc/self/exe.
The runC process must exit for the runC binary to be writable though. To enforce the exit, run_at_link calls the execve syscall to execute overwrite_runc.
Since execve doesn’t affect the file descriptors open by the process, the same file descriptor trick from the previous POC can be used:
- The runC process loads the libseccomp library and transfers execution to the run_at_link function.
- run_at_link opens the runC binary for reading through /proc/self/exe. This creates a file descriptor at /proc/self/fd/${runc_fd_read}.
- run_at_link calls execve to execute overwrite_runc.
- The process is no longer running the runC binary, overwrite_runc opens /proc/self/fd/runc_fd_read for writing and overwrites the runC binary.
For the following video, I built a malicious image that overwrites the runC binary with a simple script that spawns a reverse shell at port 2345.
The docker run command executes runC twice. Once to create and run the container, which executes the POC to overwrite runC, and then again to stop the container using runc delete [3].
The second time runC is executed, it is already overwritten, and hence the reverse shell script is executed instead.
The Fix
RunC and LXC were both patched using the same approach, which is described clearly in the LXC patch commit:
To prevent this attack, LXC has been patched to create a temporary copy of the calling binary itself when it starts or attaches to containers. To do this LXC creates an anonymous, in-memory file using the memfd_create() system call and copies itself into the temporary in-memory file, which is then sealed to prevent further modifications. LXC then executes this sealed, in-memory file instead of the original on-disk binary. Any compromising write operations from a privileged container to the host LXC binary will then write to the temporary in-memory binary and not to the host binary on-disk, preserving the integrity of the host LXC binary. Also as the temporary, in-memory LXC binary is sealed, writes to this will also fail.
RunC has been patched using the same method. It re-executes from a temporary copy of itself when it starts or attaches to containers. Consequently, /proc/[runc-pid]/exe now points to the temporary file, and the runC binary can’t be reached from within the container.
The temporary file is also sealed to block writing to it, although overwriting it shouldn’t compromise the host.
This patch introduced some issues though. The temporary runC copy is created in-memory after the runc init process has already applied the container’s cgroup memory constraints on itself. For containers running with a relatively low memory limit (e.g 10Mb), this can cause processes in the container to be oom-killed (Out Of Memory killed) by the kernel when the runC init process attaches to the container.
If you are interested, an issue regarding this complication was created and contains a discussion about alternative fixes that might not introduce the same problem.
CVE-2019-5736 and Privileged Containers
As a general rule of thumb, privileged containers (of a given container runtime) are less secure then unprivileged containers (of the same runtime).
Earlier I stated that the vulnerability affects all Docker containers but only LXC’s privileged containers. So why are Docker unprivileged containers vulnerable while LXC unprivileged containers aren’t? Well, it’s because LXC and Docker define privileged containers differently. In fact, Docker unprivileged containers are considered privileged according to LXC philosophy.
Privileged containers are defined as any container where the container uid 0 is mapped to the host's uid 0.
The main difference is that LXC runs unprivileged containers in a separate user namespace by default, while Docker doesn’t.
User namespaces are a feature of Linux that can be used to separate the container root from the host root. The root inside the container, as well as all other users, are mapped to unprivileged users on the host. In other words, a process can have root access for operations inside the container but is unprivileged for operations outside it. If you would like a more in-depth explanation, I recommend LWN’s namespace series

Image from kinvolk.
So how does running the container in a user namespace mitigate this vulnerability?
The attacker is root inside the container but is mapped to an unprivileged user on the host. Therefore, when the attacker tries to open the host’s runC binary for writing, he is denied by the kernel.
You might wonder why Docker doesn’t run containers in a separate user namespace by default. It’s because user namespaces do have some drawbacks in the context of containers, which are a bit out of the scope of this post. If you are interested, Docker and rkt (another container runtime) both list the limitations of running containers in user namespaces.
Ending Note
I hope this post gave you a bit of insight into the different aspects of this vulnerability. If you are using either runC, Docker, or LXC, don’t forget to update to the patched version.
Feel free to reach out with any questions you may have through email or @TwistlockLabs.
[1] As a side note, privileged Docker containers (before the new patch) could use the /proc/pid/exe of the runc init process to overwrite the runC binary. To be exact, the specific privileges required are SYS_CAP_PTRACE and disabling AppArmor.
[2] For those familiar with Windows DLLs, it resembles DllMain.
[3] The container is stopped after overwrite_runc exits, since overwrite_runc was executed as the init process (PID 1) of the container.
Table of Contents
Related Resources





 High Profile Threats
High Profile Threats




