
Executive Summary
We recently identified a bucket hijacking technique impacting multiple services across major cloud service providers (CSPs). The attack technique exploits a fundamental architectural flaw that is common across cloud providers and could potentially affect other cloud providers as well.
Our research reveals that an attacker can silently compromise an organization's active data streams by rerouting data into an external storage bucket. Because a storage bucket name is globally unique, an attacker can simply delete the bucket and then recreate it under the attacker's own account using the same name. This therefore creates a global namespace risk. This bucket hijacking reroutes critical logs and sensitive data directly to the attacker’s environment.
We have shared these findings with Google Cloud, Amazon Web Services (AWS), and Microsoft Azure.
We have not yet identified a real-world threat actor using this attack technique. However, we recommend organizations take steps now to head off the potential impact, particularly since we anticipate that real-world attempts to use this attack technique would be difficult to detect.
Palo Alto Networks customers are better protected from the threats discussed above through the following products and services:
Unit 42 Cloud Security Assessment can help turn cloud complexity into actionable security insights.
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
| Related Unit 42 Topics | Cloud Logging, Google Cloud, AWS, Microsoft Azure |
Key Architectural Elements Enabling the Attack
Before detailing the attack methodology, it’s important to understand several architectural elements that, when combined, make bucket hijacking possible.
Data Stream Overview
A data stream is an automated, continuous pipeline designed for high-volume data movement between services. Once configured, these streams operate autonomously in the background to push telemetry, audit logs or objects from a source environment to a designated storage destination for processing and long-term retention.
Major CSPs facilitate automated data streams. These streams serve as critical nodes for routing, processing and backing up data within an organization's infrastructure, such as:
- A cloud logging sink in Google Cloud acts as a router for log entries, directing them to a chosen destination. While primarily used to route and store logs in centralized log buckets for purposes like analysis and retention, a sink can also export logs to a Google Cloud Storage (GCS) bucket.
- Bucket replication in AWS is a feature that automatically duplicates data from a source S3 bucket to a designated destination S3 bucket.
Global Uniqueness of Bucket Names
Cloud environments often stream data into buckets such as an S3 bucket in AWS or a GCS bucket in Google Cloud. Because bucket names are typically unique across the entire cloud provider, no two users can have the same bucket name. This design simplifies data stream establishment by providing a single, predictable target. However, it also creates a shared namespace where a destination's identity is tied solely to its name, rather than to a specific, immutable account owner. This characteristic is the foundational logic behind our discovery.
Permissions to Modify Data Stream Destinations
The data stream is frequently defined by a routing resource that is configured with a specific destination. To legitimately modify this destination, the user must possess specific, granular identity and access management (IAM) update permissions for that resource.
For example, modifying the destination for a cloud logging sink requires the logging.sinks.update permission. This routes logs to a bucket. Our research found that certain permissions outside of this traditional update purview could be leveraged to reroute data streams.
The Bucket Hijacking Attack
We now turn to discussing the attack flow before any mitigations were provided by the affected CSPs. After compromising a cloud environment and securing the permissions required to delete a target bucket, an attacker was effectively positioned to intercept and redirect a cloud data stream. By deleting the original bucket and immediately recreating a new bucket with the same name within their own account, the attacker could have redirected the data stream. This could have led to the exfiltration of the target's data to the attacker's account.
Figure 1 shows the attack flow diagram.

Simulating Bucket Hijacking in Google Cloud Logging
We simulated the bucket hijacking technique in Google Cloud Logging. In the simulation, we used a sink that routes logs to a cloud storage resource, as shown in Figure 2.
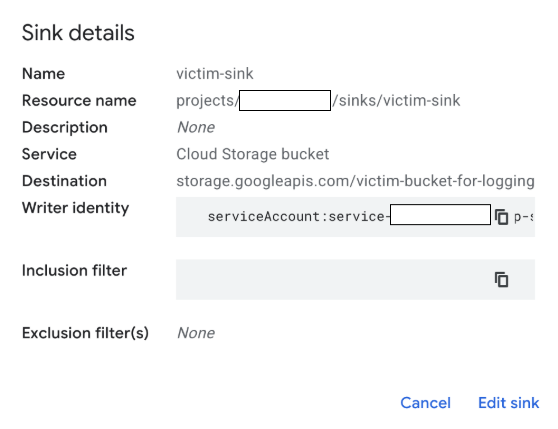
After routing the logs, the original cloud storage bucket was deleted, as Figure 3 shows.
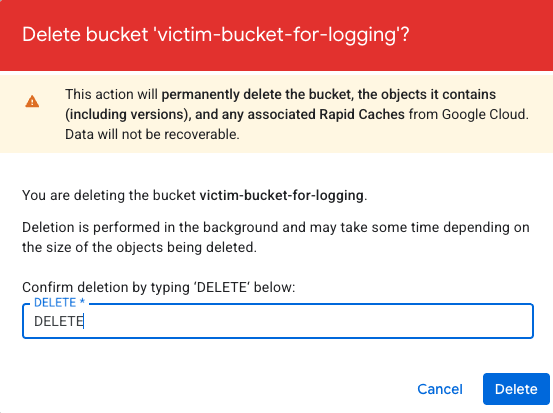
We then created a new bucket with the same name in an attacker-controlled environment, as shown in Figure 4.
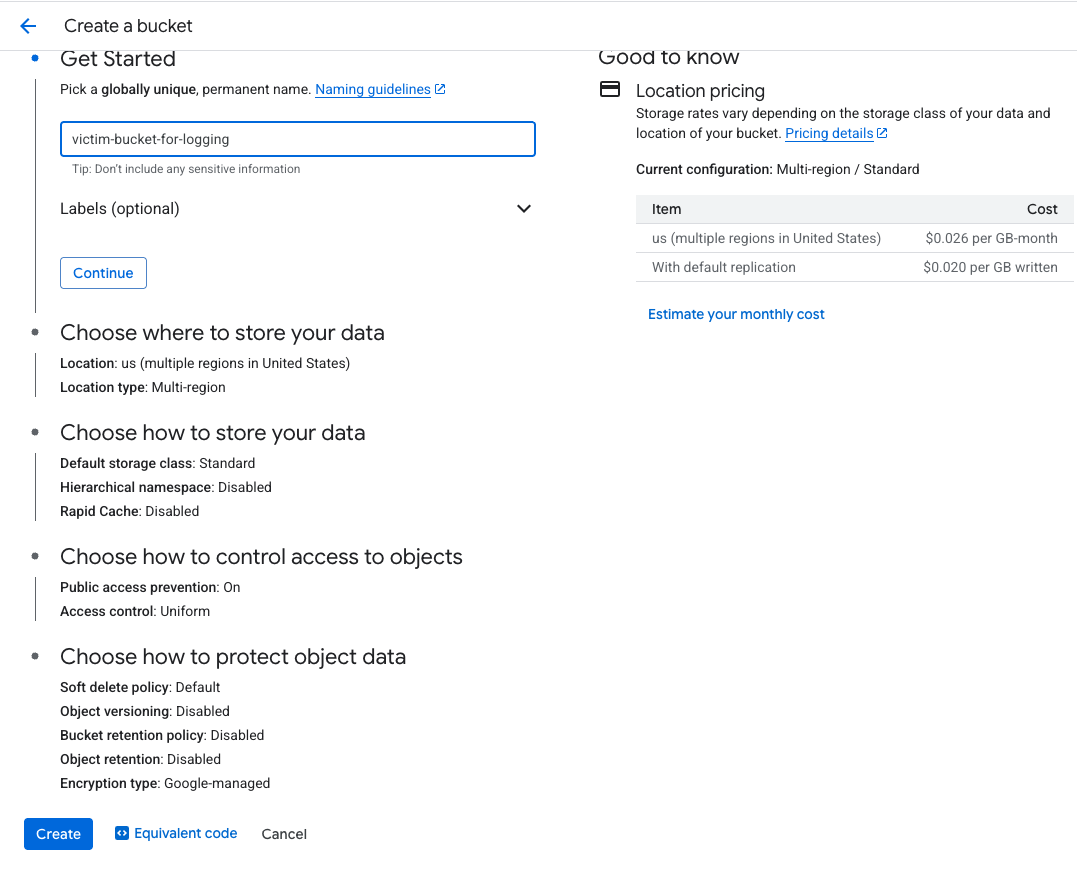
Subsequently, logs were routed to this external cloud storage bucket, allowing the attacker to obtain extensive information about the compromised environment, as shown in Figure 5. The required permissions the attacker needed to have are storage.objects.delete (to empty the bucket) and storage.bucket.delete (to delete the bucket).
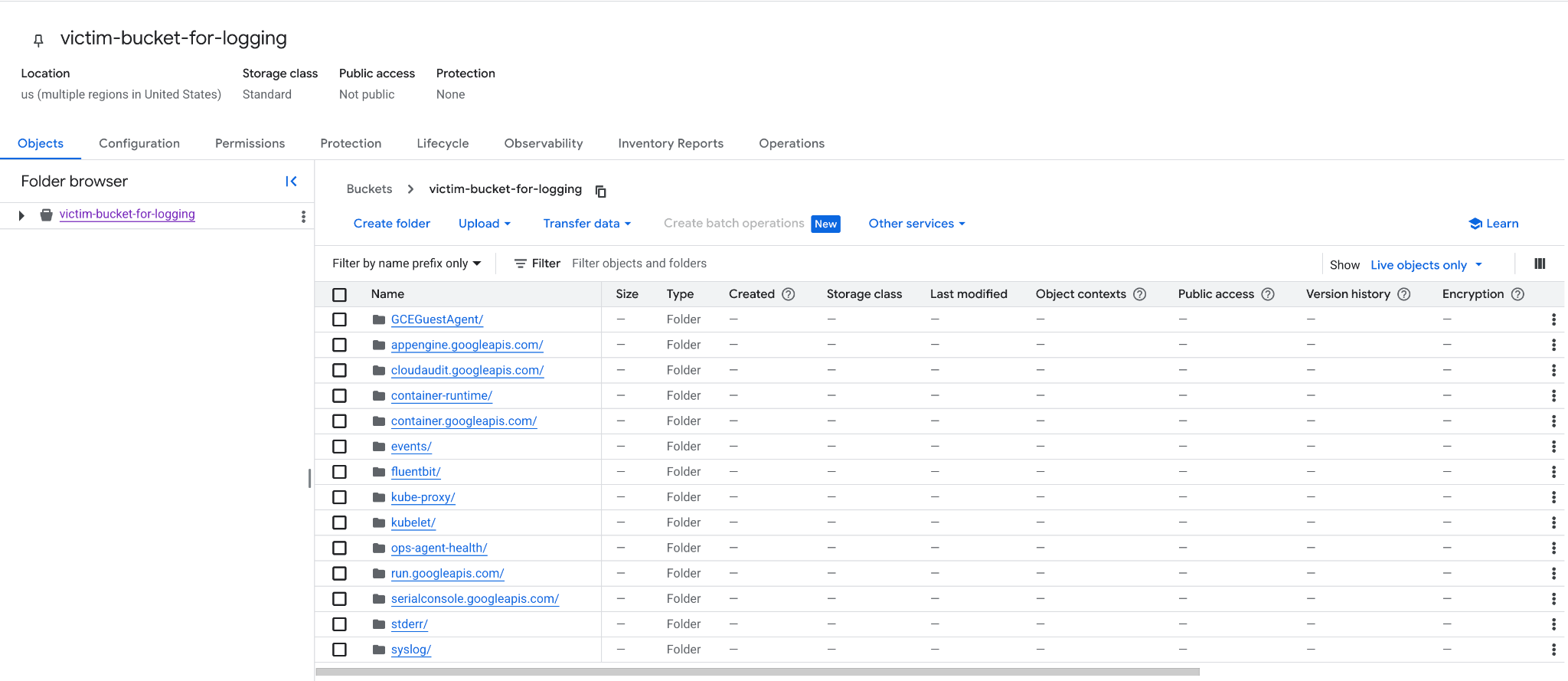
The Expansion to Multiple Services Within Google Cloud
Data streaming into a GCS bucket is not unique to cloud logging. There are many other Google Cloud services in which data can be streamed into cloud storage. We identified and tested a representative subset of potentially vulnerable services, specifically Pub/Sub and Storage Transfer Service, to confirm the systemic prevalence of this security risk.
Pub/Sub
Pub/Sub is an asynchronous messaging service that decouples upstream event producers from downstream processing services. It allows applications to broadcast messages to a topic, which are then distributed to one or more subscriptions for consumption by downstream systems.
This architecture enables scalable, event-driven communication. This allows disparate components such as log aggregators, data pipelines and real-time analytics engines to exchange information reliably without needing direct, synchronous connections.
The Pub/Sub architecture has three core components:
- Publishers (producers) send messages to a named logical channel called a topic, without needing to know who or what will receive them.
- Topics act as a buffer or distribution hub, holding the messages until they can be delivered.
- Subscribers (consumers) listen to specific topics via a subscription. When a message arrives in the topic, the Pub/Sub service pushes it to the subscribers (push model) or the subscribers actively request it (pull model).
To simulate a bucket hijacking attack on Pub/Sub, we took the following steps:
- We created a new Pub/Sub topic and a subscription linked to a GCS bucket
- We configured the GCS bucket with the necessary permissions to grant access to the service agent:
- Storage object creator (roles/storage.objectCreator)
- Storage legacy bucket reader (roles/storage.legacyBucketReader)
- We published a message to the topic, which was successfully delivered to the initial bucket
- We deleted the original bucket and created a new bucket with the same name in a different project (the attacker's project)
- When a message was published manually again, we found that the service exfiltrated the message to the attacker's environment
The successful redirection of the message stream proved that the bucket hijacking attack technique was directly applicable to the Pub/Sub service, allowing an attacker to exfiltrate data by deleting and recreating the destination bucket.
Storage Transfer Service
Storage Transfer Service is a managed data migration tool designed to automate the movement of large volumes of data into, out of or between cloud storage environments. It allows organizations to schedule and manage massive data transfers from external sources (like AWS S3 or on-premises systems) to GCS buckets, or to synchronize data between different cloud storage projects.
The service handles the underlying infrastructure, retries and checksum validation. It provides a way to populate data lakes or perform large-scale disaster recovery backups.
The Storage Transfer Service architecture operates as a centralized orchestration engine that manages the movement of data between a designated source and sink. When a user defines a transfer job, they specify the source, the destination and the scheduling parameters. The source can be an S3 bucket, a URL list or another GCS bucket.
To simulate a bucket hijacking attack on Storage Transfer Service, we took the following steps:
- We configured a new transfer job with a GCS bucket as the source and another GCS bucket as the destination
- We assigned the necessary permissions to the buckets to grant access to the service agent:
- Source bucket: Storage Object Viewer (roles/storage.objectViewer) and Storage Legacy Bucket Reader (roles/storage.legacyBucketReader)
- Destination bucket: Storage Object Admin (roles/storage.objectAdmin)
- The user then initiated the transfer job
- We deleted the destination bucket and then immediately re-created it in a different project (the attacker's environment)
- We wrote a new object into the source bucket
- After a period determined by the job's scheduling parameter, the object appeared in the newly hijacked destination bucket, which was under the attacker's control
The impact of this risk was significantly magnified by its broad applicability across numerous services. The permissions storage.buckets.delete and storage.objects.delete could be used to bypass the granular update permissions required for specific resources to redirect sensitive data streams such as logging.sinks.update, pubsub.subscriptions.update and storagetransfer.jobs.update.
The Expansion to Another Cloud Provider: AWS
The architectural flaw of global bucket name uniqueness is not exclusive to Google Cloud. AWS S3 buckets operate under the same design logic. Given this commonality, we investigated whether we could apply the same hijacking technique within the AWS ecosystem.
We successfully simulated the bucket hijacking attack using the S3 bucket replication feature. This feature enables the configuration of a source and destination bucket, where all objects written to the source bucket are automatically replicated to the destination bucket. The simulation followed these steps:
- We created a bucket in our environment with a replication rule targeting a second bucket within the same account
- We deleted the bucket and immediately recreated a new one using the same name within an external account
- We uploaded a file to the source bucket
- We observed the file appearing in the destination bucket located in the external account
Like in Google Cloud, we identified that this was not a localized issue, but applied to a number of AWS data stream services. We simulated the same technique using Amazon Data Firehose (where the destination is an S3 bucket) and observed the same behavior.
Cross-Subscription Data Exfiltration in Azure
Finally, we tested Azure’s environment for the same attack technique. Azure platform limitations prevent the immediate reuse of storage account names across different tenants for several days after deletion. However, we were able to simulate a cross-subscription attack technique.
This scenario was particularly relevant if an attacker gained permission to delete a storage account in one subscription and intended to reroute data to another. This allowed them to move data to a subscription where they maintained higher privileges and persistence, or perhaps where they previously lacked data access permissions. Ultimately, this technique relied on the fact that a storage account must be created with soft-delete disabled to ensure the name was released and could be promptly reclaimed.
We used Azure Monitor to demonstrate this attack. Diagnostic settings in Azure Monitor can be configured to export resource logs (e.g., metrics and audit events) to an Azure storage account. While the configuration stores the destination via its Azure Resource Manager (ARM) Resource ID, the internal pipeline resolves the storage account at runtime using its DNS name ({accountname}.blob.core.windows.net).
This architectural behavior facilitated the execution of the attack. If an attacker deleted a destination storage account and recreated it with an identical globally unique name in a different subscription within the same tenant, the diagnostic pipeline would continue to write logs to the attacker-controlled storage account.
The attack was less severe in Azure than in AWS or Google Cloud because it was limited to a cross-subscription scope rather than a cross-tenant one.
Exploitation Scenarios and Excessive Permissions Risks
The practical execution of bucket hijacking relies on specific exploitation vectors that are often facilitated by the widespread use of over-privileged administrative roles.
Exploitation Scenarios and Detection Challenges
We identified two distinct scenarios that could enable an attacker to execute a bucket hijacking operation:
- Privilege escalation: As demonstrated in our simulations, a compromised identity with the permission to delete a bucket could misuse this access to redirect data streams to the attacker's own bucket. The widespread application of storage administrator roles significantly increased the risk of this attack technique and overcame the need for the more granular logging.sinks.update permission (as shown later).
- Dangling router resources: In a similar exploit not demonstrated in this article, if someone deleted a bucket and failed to remove the associated router resource, an attacker could create a new bucket using the same name in their own environment. This action effectively redirects the data to the attacker's bucket, granting the attacker access to the victim's ongoing data.
Detecting these attack scenarios is particularly challenging. In scenarios where destination resources are used primarily for long-term retention or backup, the target may not detect the initial deletion of the original storage bucket. Because the data stream continues to operate autonomously, the sink configuration in Google Cloud appears valid upon inspection as shown in Figure 6. This allows the hijacking and subsequent data exfiltration to remain largely undetected.

How Over-Privileged Roles Increase the Risk
Cloud providers frequently offer broad storage administration roles that grant wide-reaching deletion privileges by default, which significantly increases the practical risk of this attack technique.
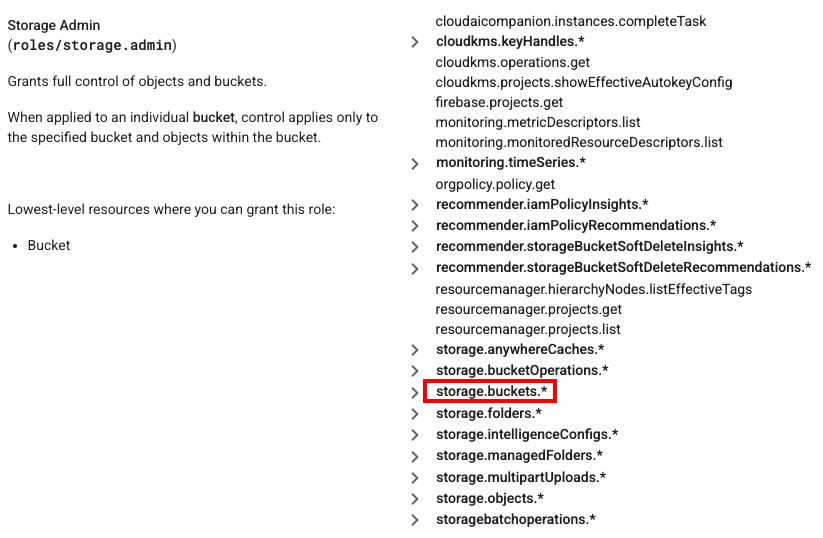
For example, in Google Cloud the common storage admin role provides the storage.buckets.delete permission. However, as Figure 7 shows, it does not include granular permissions to modify data stream configurations like:
- logging.sinks.update
- pubsub.subscriptions.update
- storagetransfer.jobs.update
Mitigation Strategies
Google has adjusted how router resources interact with target storage resources since the time of our initial research.
Microsoft recommended that Azure users review documentation and tooling on addressing dangling DNS for subdomain takeovers (see Additional Resources).
Users can also employ additional defense strategies.
Mitigating the bucket hijacking technique requires a two-pronged approach focusing on preventative guardrails and proactive monitoring. Prevention starts with the principle of least privilege. Organizations must strictly limit the IAM permissions for deletion actions, specifically:
- Storage.buckets.delete in Google Cloud
- DeleteBucket in AWS
- Microsoft.Storage/storageAccounts/delete in Azure
These permissions should be restricted to a minimal set of administrative roles and should never be assigned to service accounts or applications without rigorous justification.
In addition, the following mechanisms help to prevent the bucket hijacking technique:
- Organizations can prevent bucket hijacking for data exfiltration by enforcing data perimeter controls that restrict resource access to stay within a trusted organizational boundary.
- In AWS, data perimeter policies — implemented through service control policies (SCPs) and virtual private cloud (VPC) endpoint policies — can ensure that workloads within the organization are unable to write data to S3 buckets that belong to external accounts. This can effectively block the exfiltration path even if an attacker substitutes a malicious bucket, though the approach has some limitations.
- Similarly, in Google Cloud, VPC Service Controls define a security perimeter around projects and services, to block any API call attempting to access Cloud Storage buckets outside the perimeter.
Deploying these controls as a baseline ensures that data cannot leave the trusted environment boundary, neutralizing the core mechanism of this attack technique.
- AWS offers account regional namespaces for S3 buckets, which scope bucket names to the owning account and region rather than to a single global namespace. This directly eliminates the bucket hijacking vector. If a bucket is deleted, no other account can reclaim its name. This prevents attackers from intercepting traffic by re-registering abandoned bucket names.
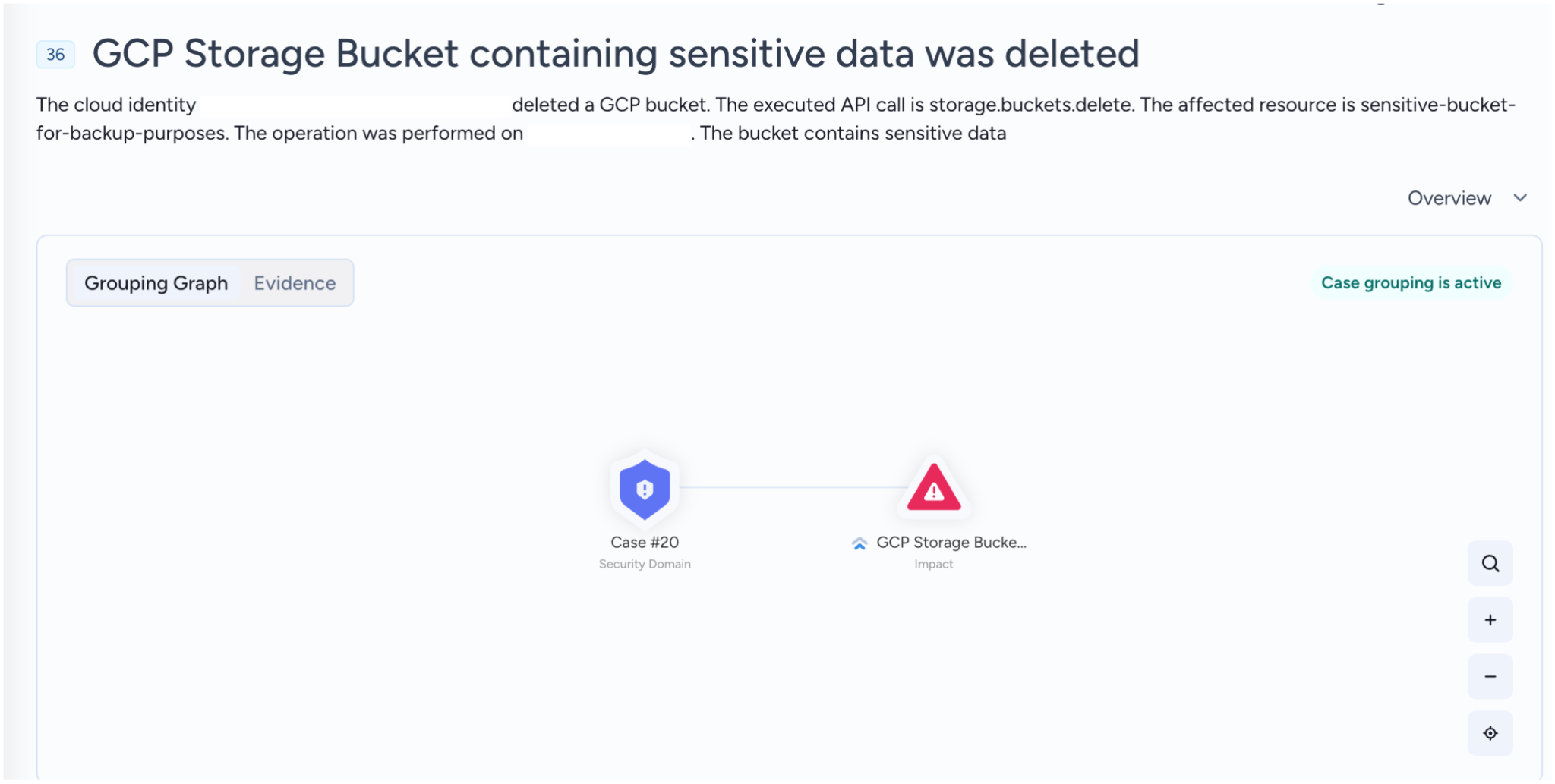
For detection, organizations must implement robust monitoring solutions that specifically alert on the attempted deletion of a storage bucket. Security teams should prioritize high-severity alerts for storage deletion API calls, focusing specifically on resources that house sensitive information.
Given the high frequency of storage deletion events in large-scale environments, leveraging data security posture management (DSPM) capabilities is essential. It is particularly important to prioritize monitoring and to focus specifically on high-value, sensitive assets, as shown in a Cortex XSIAM alert in Figure 8.
Conclusion
The bucket hijacking technique detailed in this research exploits the global uniqueness of storage resource names in the major cloud providers. We have demonstrated how a configure-and-forget approach to data streams can lead to silent, long-term data exfiltration.
Reliance on a globally unique, static resource name for buckets is an architectural design common across cloud providers. As such, this technique could be portable to other cloud services and providers not covered in this research.
Our findings underscore two primary lessons for the security community:
- Architecture defines the security boundary: Fundamental design choices made by cloud providers directly influence the security boundaries of our environments. A robust mitigation strategy must include awareness of these architectural nuances and the implementation of guardrails.
- A cross-cloud exploitation methodology: While cloud providers are often managed as distinct ecosystems, their shared design philosophies allow identical attack techniques to be applied across providers. Our simulations prove that a specific architectural observation can evolve into a universal methodology for hijacking sensitive data streams. We encourage the security industry to adopt a cloud-agnostic mindset. A design flaw discovered in one provider could be a blueprint for exploiting another.
Palo Alto Networks Protection and Mitigation
Palo Alto Networks customers are better protected from the threats discussed above through the following products:
- Cortex Cloud customers are better protected from the techniques discussed in this article with cloud runtime security operations through the collection, analysis, detection, alerting and prevention of malicious operations on cloud platform and SaaS application audit logs. Cortex has several out-of-the-box rules built into the Analytics module that detect data movement to external buckets. Using behavioral and static alerting techniques on cloud logs during cloud operations runtime, the techniques discussed within the article can be identified. When this occurs, they trigger alerts, which provide early warning and, in some cases, prevention operations to prevent further compromise from these attacks.
- Cortex Cloud Identity Security can also protect organizations from the techniques discussed in the article. Identity Security encompasses:
- Cloud Infrastructure Entitlement Management (CIEM)
- Identity Security Posture Management (ISPM)
- Data Access Governance (DAG)
- Identity Threat Detection and Response (ITDR)
- These tools provide the necessary capabilities to improve identity-related security requirements within cloud environments. This includes:
- Accurately detecting misconfigurations
- Identifying unwanted access to sensitive data
- Conducting real-time analysis surrounding usage and access patterns
Unit 42 Cloud Security Assessment can help turn cloud complexity into actionable security insights.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 000 800 050 45107
- South Korea: +82.080.467.8774
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Additional Resources
- Aggregated sinks overview – Google Cloud
- Bucket Replication - AWS
- Pub/Sub - Google Cloud
- Pub/Sub Topic - Google Cloud
- Pub/Sub Subscription - Google Cloud
- Storage Transfer Service - Google Cloud
- Amazon Data Firehose - AWS
- Azure Monitor - Azure
- Prevent subdomain takeovers with Azure DNS alias records and Azure App Service's custom domain verification | Microsoft Learn
- Azure-Network-Security/Cross Product /DNS - Find Dangling DNS Records - GitHub
- Building a Data Perimeter on AWS - AWS
- Overview of VPC Service Controls - Google Cloud
- Account regional namespaces for Amazon S3 general purpose buckets - AWS
Table of Contents
Related Cloud Cybersecurity Research Resources









