
Executive Summary
In the past few years, a Python library for .NET file analysis has been developed internally at Palo Alto Networks. As the library is now stable, we decided it is mature enough to open source it and share it with the research community.
This blog post will serve as an introduction to the dotnetfile library. dotnetfile facilitates the extraction of vital information from .NET Portable Executable (PE) files. In addition to basic parsing, several advanced features are implemented by dotnetfile, which may help both automatic and manual analysis tasks. We also describe a new original fingerprinting technique called MemberRef Hash that is included in the library.
Those of you who wish to jump directly into the deep end are invited to review the code and the documentation.
| Related Unit 42 Topics | Malware |
.NET Background
.NET is a free open source software framework, primarily developed by Microsoft. .NET is a managed software framework, meaning that code execution is managed by a runtime component and the original code isn’t executed directly by the CPU. While most of the programming languages that are supported are high-level, .NET offers an interface to directly interact with the operating system. All of the above make .NET an excellent platform for software development. While there are many legitimate uses for such a platform, malware authors often take advantage of good software development resources, and the .NET platform is no exception.
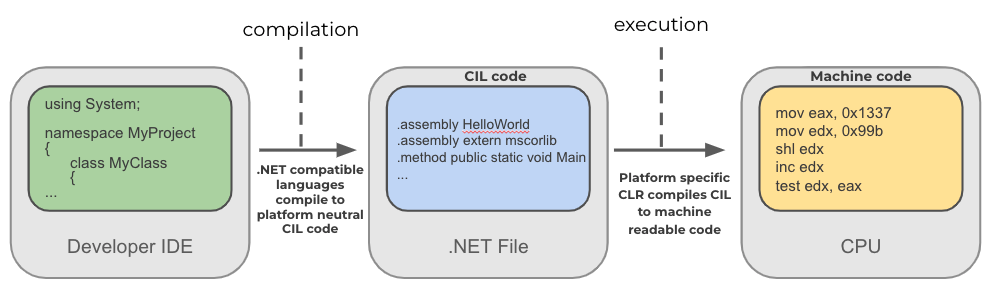
The diagram below schematically represents the .NET compilation and execution process. A programming language supported by .NET gets compiled by an appropriate compiler into a platform-neutral Common Intermediate Language (CIL) bytecode. The CIL is essentially the .NET binary instruction set. In runtime, a platform-specific Common Language Runtime (CLR) component compiles the CIL into native code, such as X86 or X64 Assembly. Besides translating the CIL bytecode into native instructions, the CLR is also in charge of executing the .NET program in a managed manner, handling memory management, type verification and much more.
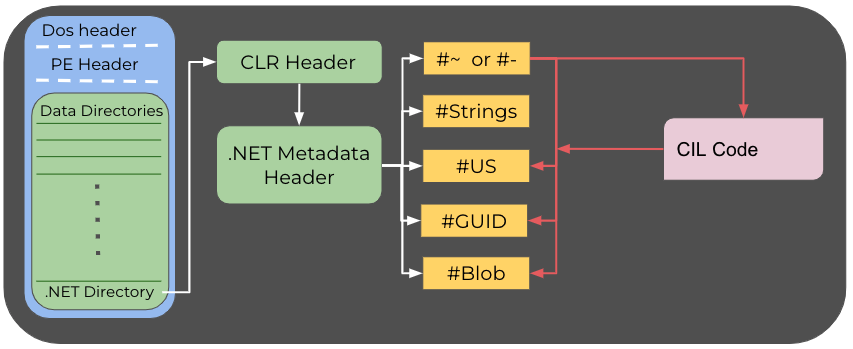
In terms of file format, the common .NET PE file differs from its native PE counterpart. The difference begins at the .NET data directory, also called the COR20 directory. The directory points to the CLR header, which in turn points to the .NET metadata header. These two headers hold global information about the executable. The .NET metadata header usually points to five streams:
- #~ or #- – The metadata stream. #~ indicates that the data is optimized, while data under #- isn’t. This stream includes up to 56 different metadata tables.
- #Strings – This stream is a heap of the system strings, such as the member names, the class names, the method names, etc.
- #US – Contains user string literals.
- #GUID – Holds GUIDs. For some executables, the GUID associated with the project can be found in this stream.
- #Blob – This stream contains binary objects such as a binary array and also stores methods’ signatures in an encoded form.
Any other stream is not allowed by .NET. If another string is present, it might have been inserted by obfuscators and protectors as “junk” to break parsers.
Various metadata tables under #~ point to offsets into the CIL code. One such table is the "Method" metadata. Each entry in this table will point to the starting offset of the method it describes in the CIL code. The CIL code references information held in the streams. For instance, this would occur when the code makes use of a string from the user strings heap (#US).
This section only provides a brief overview of .NET. The curious reader may check out ntcore's article or the official CLI spec.
Generally speaking, the overview is accurate, however, a disclaimer is appropriate. There are valid edge cases that divert from this “high-level” representation.
dotnetfile
The dotnetfile library was named after the legendary pefile library. The usage is also very similar. In fact, the main object – DotNetPE – inherits from pefile's PE object. The dotnetfile library is a pure Python library, meaning there is no need to compile anything or rely on third-party .NET executables. We hope that fellow researchers will find the library useful for automating their file analysis workflows as well as for speeding up the manual investigation of samples.
Fields and Structure Parsing
dotnetfile extracts almost any field and structure from the .NET PE file. Among the parsed information, one can find:
- The CLR header.
- The .NET metadata header.
- Metadata tables under #~ – including methods, classes, members and plenty of other table entries.
- System strings.
- User strings.
- .NET resources: Metadata and raw source are parsed out; the resources are not being deserialized at the time of writing.
ImplMap and ModuleRef: The Hidden Import Table
In the most common case, the import table of a .NET PE file will only have entries referencing mscoree.dll, the .NET runtime library. Furthermore, these entries won’t reveal much about the program’s functionality, as oftentimes the same closed set of imports will be present in the import table.
The ImplMap metadata table stores information about unmanaged methods that can be reached from managed code, while the ModuleRef table contains the respective module information. P/Invoke relies on this information. Had the sample planned to use Windows API, the declared API will be stored in these tables. It is worth noting that accessing Windows API, or any other native code, can be achieved by resolving the API in runtime. Hence, in such cases, the ImplMap table won't necessarily store the API information.
dotnetfile provides a means to easily list unmanaged methods.
Advanced Features
dotnetfile includes a few features that were developed in addition to the basic parsing ability that allows it to extract valuable information. We named this group of features "Advanced Features'' since they include logic and heuristics created by us. This logic conveys our own higher-level understanding of the .NET PE file and is not just straightforward parsing.
We believe that researchers can benefit from these features in a variety of tasks and applications.
MemberRef Hash
MemberRef hash is an innovative new fingerprinting technique specifically developed for .NET samples. Like any other fingerprinting technique, it may help us to group, cluster and detect samples.
To better understand the technique, we first need to have a deeper look into the MemberRef metadata table. The MemberRef table contains mostly .NET runtime constructs such as methods, properties, fields and so on. We have found that this table can't be easily obfuscated, meaning the info in this table can help us with grouping obfuscated samples.
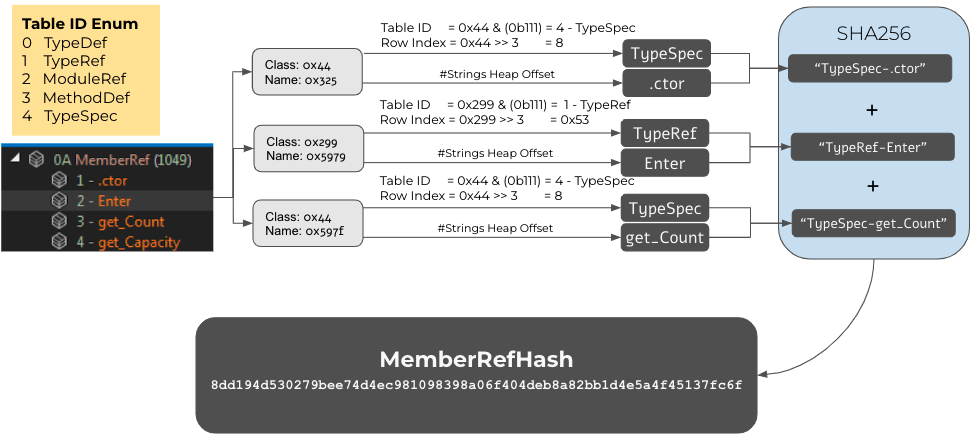
The MemberRef hash is computed over the MemberRef table using the following process:
- For each entry in the MemberRef table, the string that represents the member name is taken, assigned to NAME.
- In addition, for each entry the table name of the corresponding class is taken, assigned to TABLE.
[This might not be clear at first, so let's dive into it. Each entry has a field called class that is an encoded index of one of five possible tables: TypeDef, TypeRef, ModuleRef, MethodDef and TypeSpec. This encoding is officially called MemberRefParent encoding. The lowest three bits represent the table ID, while the upper 13 bits represent the index in the remote table. For the MemberRef hash algorithm, the textual representation of the table ID is captured (such as TypeSpec). In order to keep it simple, only the table ID is being used. The extra step of using the actual information from the remote tables is not part of the algorithm because each one of those tables has its own unique data structures and data types. Furthermore, the current implementation is not too "tight" so it can be used to group samples.] - The textual representation of the table ID (TABLE) and the member name (NAME) are concatenated into TABLE.NAME.
- All the entries from Step 3 are textually concatenated.
- By default, the entries are used in the same order of appearance in the MemberRef table.
- A flag to sort the entries by name is available, but it is unset by default.
- The final MemberRef hash is a result of computing SHA256 over the string from Step 4.
The following diagram depicts the MemberRef hash computation process.
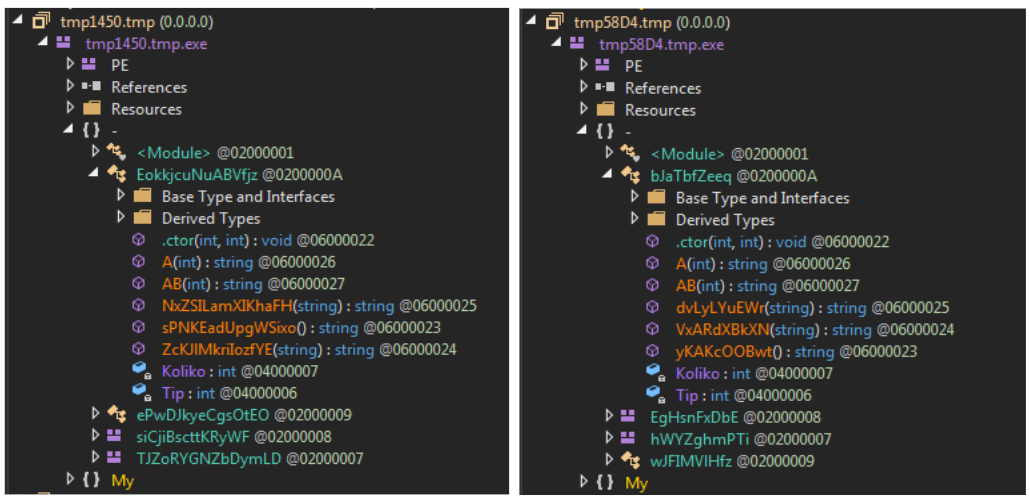
Let’s review an in-the-wild example. The naked eye can tell that the two samples shown in Figure 4 are very similar. However, it gets trickier from an automation point of view.
Fortunately, these two samples share the same MemberRef hash. That means that all of the members under the MemberRef table had the same name and the same table ID in both of the samples. Furthermore, the entries appear in the same order.
TypeRef Hash Reimplementation
TypeRef hash is a fingerprinting technique for .NET samples that was invented by GDATA. The idea is to compute a hash over all of the referenced .NET types. To some degree, TypeRef hash resembles imphash, but there are some key differences.
The dotnetfile library includes implementation of the TypeRef hash functionality with a few “tweaks” compared to GDATA’s original implementation.
- The original TypeRef hash implementation uses the type’s name and the type’s namespace. Our version uses the ResolutionScope names instead of the Namespace names, as the former’s are always present.
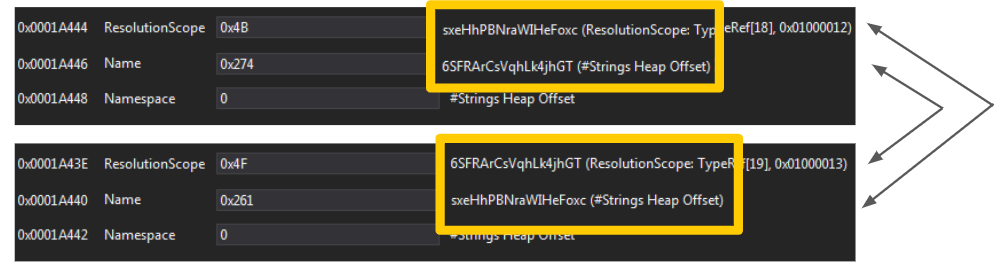
- Some .NET packers and protectors insert into the TypeRef metadata table types that reference each other. In other words, this means that a certain Type A is nested under Type B, and Type B is also nested under Type A. This obviously doesn’t make any sense. These kinds of types are “garbage” that has been artificially inserted in order to break parsers. Another side effect is that the names of these types can be easily randomized (as they are not real), resulting in a different TypeRef hash per sample. dotnetfile‘s implementation can skip such TypeRef entries, making the dotnetfile implementation more resilient against this class of samples. Figure 6 demonstrates a real-world example of TypeRef entries that reference each other.
- Another type of “junk” TypeRef entries are entries that reference a nonexistent TypeRef entry. In Figure 7, we can observe a sample with a TypeRef entry that references the TypeRef entry at index 172, while the TypeRef table has only 170 entries. In addition, in this example, the Name and Namespace fields are nulled out. dotnetfile‘s implementation skips such entries.

Entry Point Discovery
.NET DLLs don't need to have a defined entry point, in contrast to native PE DLLs that always have the DllMain function. Without knowledge of the real entry point, attempting to execute a .NET DLL will likely fail. In order to perform dynamic analysis of these files and fully detonate them, the appropriate entry point method(s) must be invoked.
The dotnetfile library provides an interface to list probable entry points based on tried and true heuristics. These heuristics are not bulletproof but work pretty well.
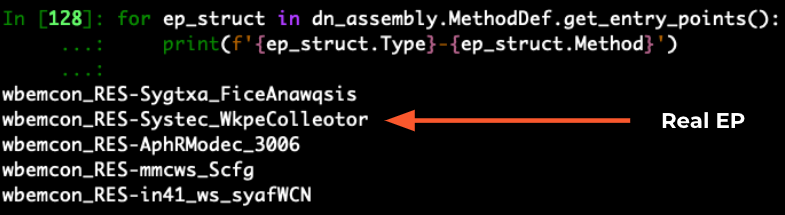
Looking at the analysis hash below, only five possible entry points were listed. This methodology drastically narrows down the search space for the right entry point. Upon manual examination of these five methods, it turns out that the second method is the real entry point.
Anti-Metadata
Packers and protectors often try to break parsing by employing various techniques. The dotnetfile library comes with logic to identify such anomalies in the .NET metadata structures. This collection of anomaly detection methods was named Anti-Metadata. The anomalies that the library detects include:
- Fake .NET streams.
- Abnormal number (more than one) of entries in the Module table and Assembly table.
- Invalid string entries, often employed by ConfuserEx.
- Extra bytes in the .NET metadata header, which is valid but unusual.
- Invalid TypeRef entries.
- Attempts to tamper with the data directories number in the PE header (OPTIONAL_HEADER.NumberOfRvaAndSizes), so it effectively hides the .NET data directory.
- Self-referencing TypeRef entries – by examining the corresponding resolution scope.
This logic is still experimental but can point out anomalies in .NET PE samples, and it can be used as a feature for detection applications.
Conclusion
.NET is a widely used software development framework. Malware authors have adopted .NET, and this fact is reflected in the present threat landscape.
The dotnetfile library is a pure Python library that parses .NET PE files and extracts all sorts of useful information. Furthermore, dotnetfile provides higher-level logic on top of basic parsing functionality. We are proud to share it with the research community and we hope researchers will make use of it.
Additional Resources
Table of Contents
Related Cybersecurity Tutorials Resources







 Threat Actor Groups
Threat Actor Groups