
Executive Summary
Palo Alto Networks has released “Securing GenAI: A Comprehensive Report on Prompt Attacks: Taxonomy, Risks, and Solutions,” which surveys emerging prompt-based attacks on AI applications and AI agents. While generative AI (GenAI) has many valid applications for enterprise productivity, there is also potential for critical security vulnerabilities in AI applications and AI agents.
The whitepaper comprehensively categorizes attacks that can manipulate AI systems into performing unintended or harmful actions — such as guardrail bypass, information leakage and goal hijacking. In the appendix, it details the success rates for these attacks – certain attacks can be successful as often as 88% of the time against certain models, demonstrating the potential for significant risk to enterprises and AI applications.
To address these evolving threats, we introduce:
- A comprehensive, impact-focused taxonomy for adversarial prompt attacks
- Mapping for existing techniques
- AI-driven countermeasures
This framework helps organizations understand, categorize and mitigate risks effectively.
As AI security challenges grow, defending AI with AI is critical. Our research provides actionable insights for securing AI systems against emerging threats.
The article below provides a condensed version of the full paper, showing the taxonomy and covering the key points. For a more detailed version of these concepts, as well as references, please refer to “Securing GenAI: A Comprehensive Report on Prompt Attacks – Taxonomy, Risks and Solutions.”
Palo Alto Networks offers a number of products and services that can help organizations protect AI systems, including:
- AI Runtime Security
- AI Access Security
- AI Security Posture Management (AI-SPM)
- Unit 42’s AI Security Assessment
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
The Urgent Need for GenAI Security
As GenAI becomes embedded in critical industries, prompt attacks pose an urgent and severe security threat. These attacks manipulate AI models into leaking sensitive data, bypassing guardrails or executing unintended actions. This can lead to data breaches, misinformation and financial losses. In high-stakes sectors like healthcare and finance, the consequences can be catastrophic, from compromised patient records to flawed automated decision-making such as biased lending decisions.
Beyond immediate risks, such attacks erode user trust and system reliability, amplifying ethical concerns such as misinformation and AI-driven exploitation. Our analysis of leading large language models (LLMs) reveals substantial vulnerabilities – certain attacks can be successful as often as 88% of the time against certain models. These findings emphasize the need for a structured defense strategy to secure AI applications against adversarial manipulation.
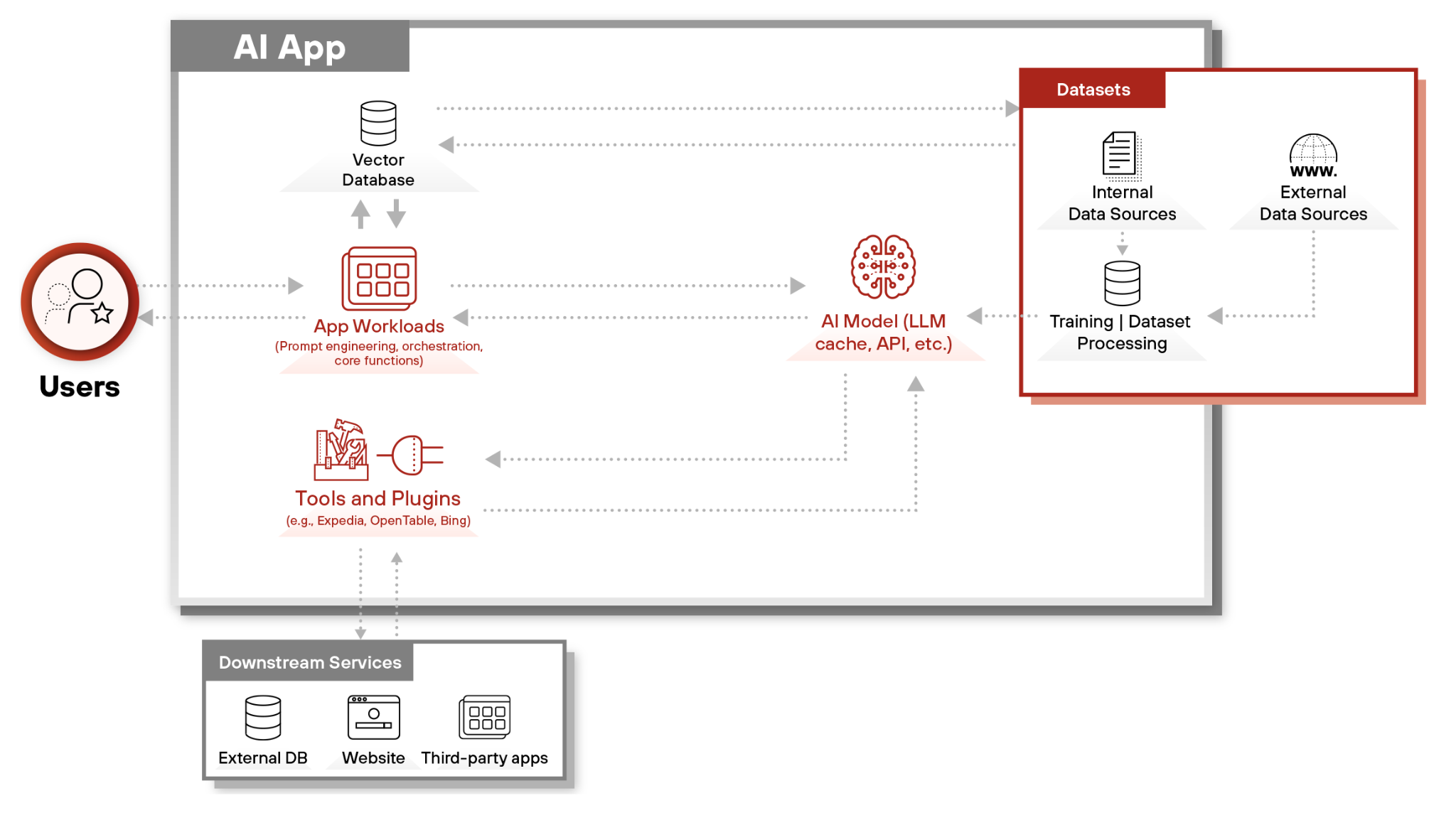
Background: AI System Architecture
AI Applications
A typical enterprise GenAI application consists of multiple interdependent components:
- App workloads: User interfaces, prompt engineering (designing and optimizing the prompt inputs) and business logic
- AI model: Foundation models, fine-tuned models or hybrid AI systems
- Datasets: Retrieval-augmented generation (RAG) data extracted from the knowledge base for real-time knowledge retrieval and training datasets for model fine-tuning
- Tools and plugins: APIs and external services enabling task execution
- Users: End-users or other applications providing instructions
Given the complexity of the interactions between these components, solely monitoring user inputs and outputs is insufficient. Threat detection must extend to AI-generated outputs, RAG interactions and tool integrations to ensure security. Figure 1 shows the architecture of a typical AI application.
AI Agents: A New Layer of Complexity
AI agents extend traditional GenAI applications with reasoning, long-term memory and autonomous decision-making. They coordinate tools, decompose tasks and improve over time. This enables powerful automation but also introduces new security risks:
- Memory corruption: Attackers inject malicious instructions to persistently alter behavior
- Instruction and tool schema exposure: Crafted prompts can extract sensitive system operations
- Tool exploitation: Malicious inputs can trigger unauthorized actions, such as SQL injection attacks
The following sections will explore specific prompt attack techniques and mitigation strategies.
Part 1: Impact-Based Categorization of Prompt Attacks
We categorize adversarial prompt attacks into four impact-based categories to facilitate understanding of the associated security risks.
- Goal hijacking: Manipulating the AI’s objective to perform unintended actions
- Guardrail bypass: Circumventing safety measures designed to restrict harmful output
- Information leakage: Extracting sensitive data from the AI model or its associated systems
- Infrastructure attack: Disrupting or damaging the underlying infrastructure of the AI system
Each category highlights a distinct facet of potential threats, enabling organizations to tailor their defense strategies effectively.
What Is Goal Hijacking?
Goal hijacking involves crafting input to redirect the LLM to take actions away from the intended purpose of the application or user. Such attacks do not necessarily require bypassing system guardrails but instead only require the attacker to cause the model to perform the attacker’s goal rather than its intended functionality. For example, an adversary can manipulate an LLM-based application that parses resumes by hiding new instructions inside a document to increase their chances of passing initial resume screening.
Goal hijacking can occur in a RAG system when the application retrieves data from sources poisoned with malicious instructions. This type of attack, which exploits a model’s inability to separate legitimate instructions from an attacker’s instructions within a conversation, is often referred to as indirect prompt injection. The attacker can be a malicious end user or a third party with access to the application’s data sources.
What Is a Guardrail Bypass?
Guardrail bypass involves circumventing the safety measures implemented by the application developers or built into the AI model itself. This includes attempts to disregard guardrails put in place by the system prompt, model training data, or an input monitor.
Successfully bypassing these guardrails allows attackers to exploit plugin permissions, generate toxic content, inject malicious scripts or URLs, and engage in other harmful activities. For example, an attacker can attempt to bypass guardrails by obfuscating disallowed instructions using an encoding scheme.
What Is an Information Leakage Attack?
Information leakage attacks aim to extract sensitive data from the AI system. One common tactic is obtaining the LLM's system prompt, which can reveal information about the application's guardrails and proprietary prompt engineering techniques. Another tactic, known as leak replay, involves crafting prompts to retrieve sensitive information the model has memorized from its training data or previous sessions.
What Is an Infrastructure Attack?
Infrastructure attacks target the application infrastructure and resources supporting the AI application. Two well-documented examples are resource consumption attacks and remote code execution attacks.
For example, a cost utilization attack might involve submitting short prompts designed to execute the LLM's full context window (or trigger a server timeout) such as asking the model to repeat an instruction 100,000 times. Furthermore, when GenAI applications execute commands provided by an LLM, they are vulnerable to remote code execution attacks where an attacker designs input prompts to trick an application into executing arbitrary commands. These arbitrary commands are those that the attacker chooses, not ones chosen by the intended user.
Attacks Targeting AI Agent Platforms
To better understand the security risks posed by AI agent vulnerabilities, it is crucial to categorize attacks based on their techniques and map them to their broader impacts. This systematic approach highlights how specific attack methods lead to consequences such as goal hijacking, information leakage, infrastructure attacks and guardrail bypass.
Linking techniques to their impacts allows organizations to better prioritize mitigation strategies and address vulnerabilities comprehensively. See Table 1 for the AI agent security issues mapping from technique-based categorization to impact-based categorization.
| Technique-based | Impact-based | |||
| Goal Hijacking | Guardrail Bypass | Information leakage | Infrastructure attack | |
| Memory Corruption | X | X | ||
| Exposure of Instructions and Tool Schemas | X | |||
| Direct Function Exploitation | X | X | ||
Table 1. AI Agent security issues mapped from technique to impact categorization.
Part 2: Categorizing Prompt Attacks by Technique
This section categorizes prompt attacks based on the techniques used by attackers. Attackers execute these techniques in two main ways:
- Direct: The attacker sends the malicious prompt or query directly to the LLM-integrated application. This involves crafting input designed to exploit vulnerabilities in the LLM's interpretation or processing.
- Indirect: The attacker embeds malicious information within the data sources used by the LLM-integrated application. When the application processes this poisoned data, it inadvertently creates a malicious prompt that is then passed to the LLM. This is often seen in RAG systems.
A technique refers to a general attack strategy, while an approach is a specific implementation of that strategy. Malicious prompts often combine multiple techniques and approaches.
For example, social engineering is a technique that involves manipulating the LLM through deceptive prompts. An approach using this technique might involve impersonating a trusted authority figure within the prompt.
We classify prompt attacks into four primary techniques:
- Prompt Engineering: Crafting carefully worded prompts to elicit desired (but potentially unintended) responses from the LLM
- Social Engineering: Using deceptive prompts to manipulate the LLM, often by impersonating a trusted authority or exploiting psychological vulnerabilities
- Obfuscation: Disguising malicious instructions within the prompt to evade detection or bypass filters
- Knowledge Poisoning: Contaminating the LLM's training data or knowledge base with malicious information
Figures 2a and 2b illustrate how these techniques map to specific impact categories, clarifying the relationship between the techniques and their potential consequences.
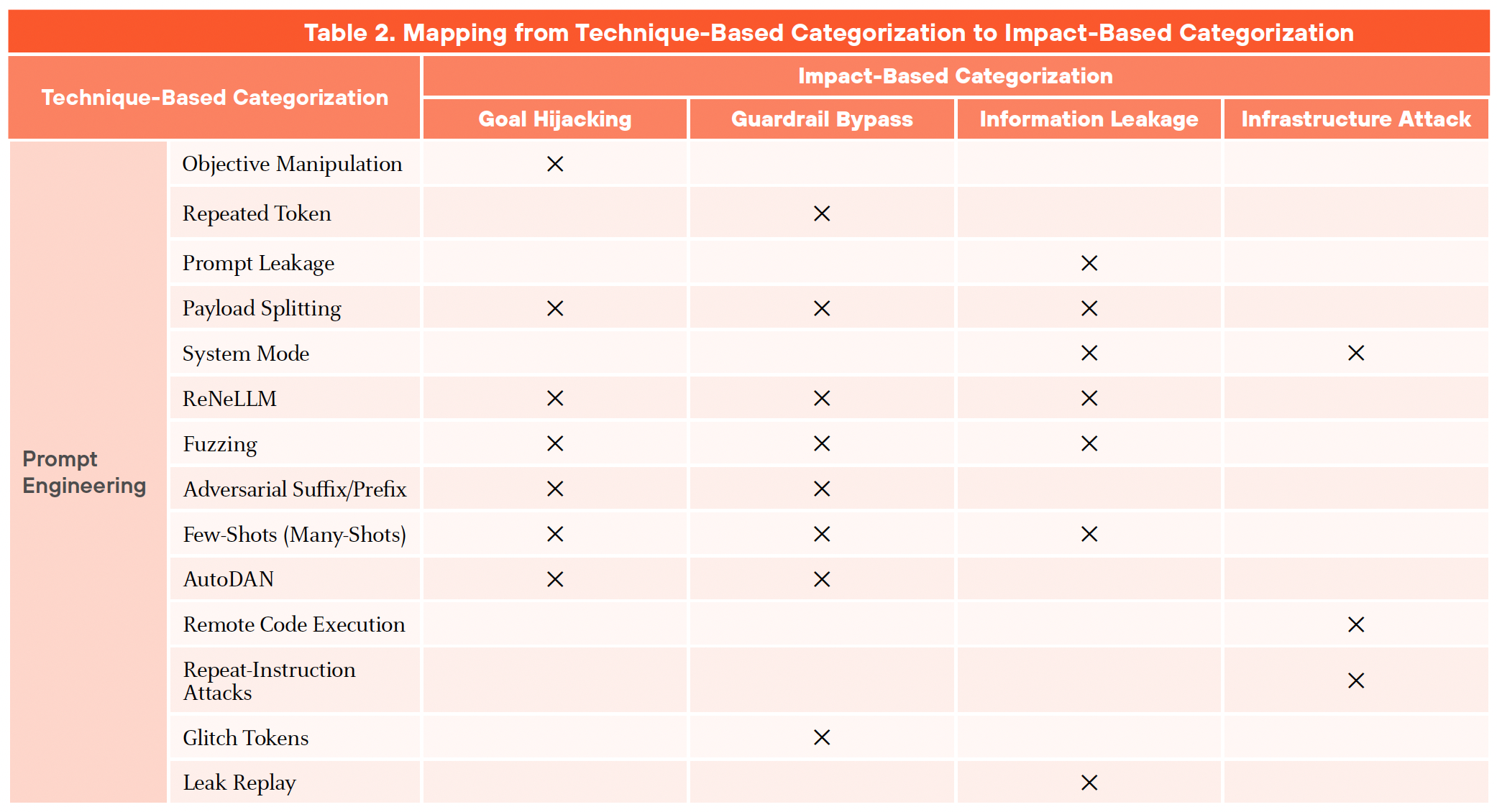
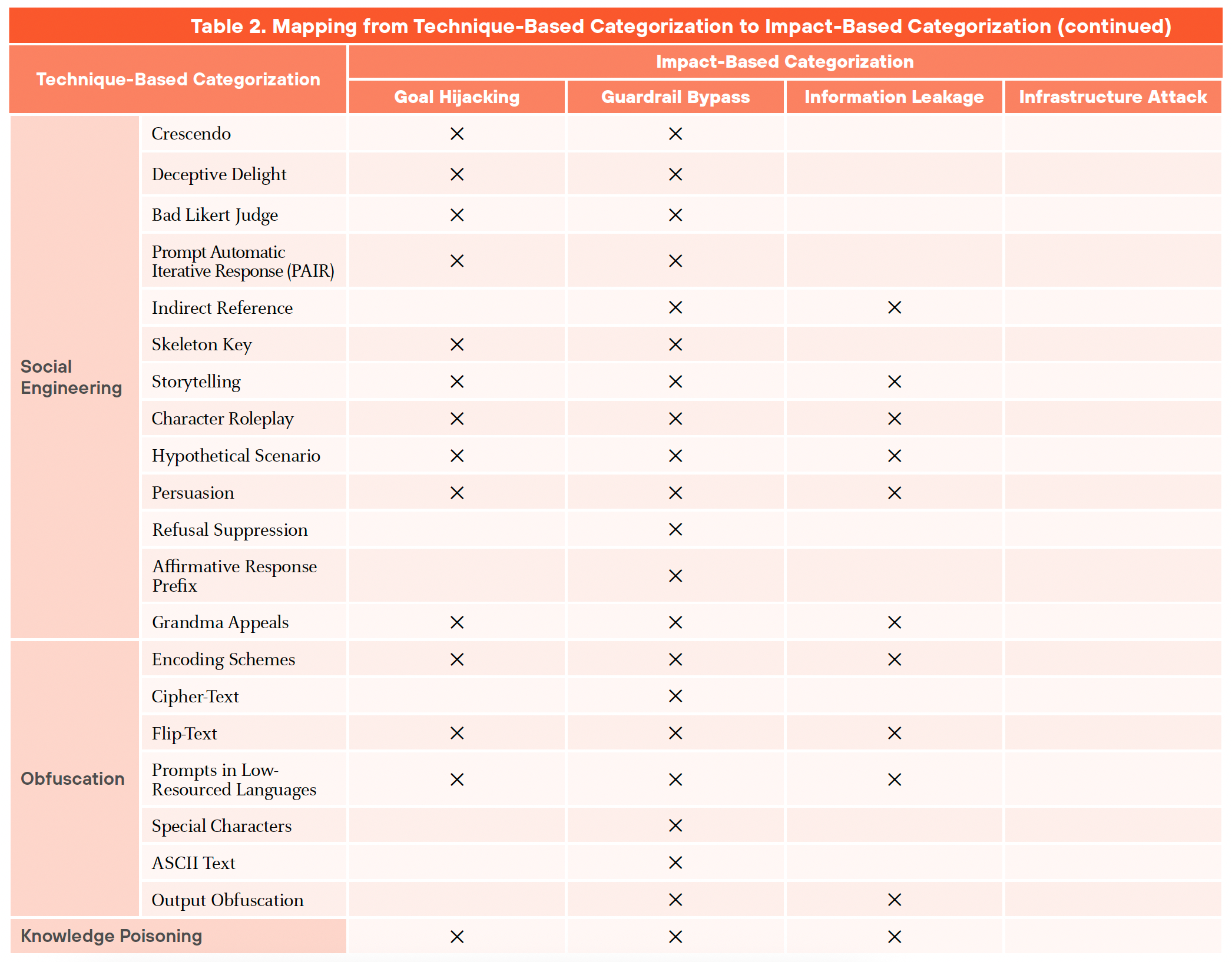
As the landscape of prompt attacks evolves, new techniques will likely emerge, adding complexity to the already diverse set of methods discussed here. Many attacks do not operate in isolation but often involve a combination of techniques, which increases their effectiveness and complicates detection and mitigation. The emergence of multimodal systems further enhances the sophistication of these attacks, as AI integrates diverse inputs (e.g., text, image, audio or video), making them more challenging to detect and mitigate.
Advanced attacks span multiple technique categories, such as multimodal jailbreaks, which leverage image or audio inputs to bypass LLM guardrails. For example, typographic visual prompts can embed hidden instructions within an image. This allows attackers to bypass model guardrails leading to impacts such as goal hijacking, information leakage and guardrail bypass. Similarly, audio-based prompts containing hidden messages can yield comparable outcomes, underlining the need for robust defenses against multimodal prompt attacks.
These developments underscore the need for adaptable, proactive security strategies to combat the growing complexity and evolving nature of prompt-based threats.
Part 3: Detect and Prevent Adversarial Prompt Attacks
The following section describes how to secure your GenAI applications against each of the four impact categories, including specific attack scenarios and prevention techniques.
Goal Hijacking
Goal hijacking attacks often involve manipulating the model to disregard prior instructions and perform a different task than intended by the user or system prompt. A key mitigation strategy is to implement input guardrails that detect and prevent adversarial prompt attacks, including those using prompt engineering, social engineering or text obfuscation techniques. These guardrails could include techniques like analyzing prompt similarity to known malicious prompts, detecting unusual patterns in input text, or limiting the model's ability to deviate from the original instructions. Furthermore, robust access controls on data sources used by the model (especially in RAG systems) can reduce the risk of indirect prompt injection, a common method for goal hijacking.
Guardrail Bypass
As shown earlier, many types of prompt attacks enable an attacker to bypass GenAI application guardrails, especially those that use social engineering or obfuscation. A comprehensive LLM prompt guardrail is required to detect the many ways to jailbreak a GenAI model. As new types of LLM jailbreaks are continuously discovered, regularly updating and testing these guardrails against known attack patterns and emerging threats is critical for maintaining a strong security posture. A guardrail that has remained stagnant for just a few months may already have significant vulnerabilities.
Information Leakage
Securing against information leakage requires multiple types of guardrails, due to the many ways that an attacker can exfiltrate information from a GenAI system. Incorporating a guardrail on LLM input and output that scans for sensitive data, such as personally identifiable information (PII), protected health information (PHI), intellectual property and other confidential information is crucial. Specifically, guarding against prompt leakage (exfiltration of system instructions) and leak replay (retrieval of memorized training data) requires robust defenses. Moreover, agentic workflows, where AI agents interact with tools and services, present opportunities for malicious actors to employ the same prompt hacking mechanics to exfiltrate tools signatures and use them without authorization. As a result, a guardrail to prevent adversarial prompt attacks can also mitigate information leakage or unauthorized tool use.
Infrastructure Attack
As previously discussed in the earlier sections on prompt attacks, there are multiple ways that an attacker can cause an infrastructure attack on a GenAI application. For example, an attacker can manipulate a GenAI application to compromise its resources with prompt attacks such as the repeat-instruction or remote code execution attacks. Furthermore, an attacker can manipulate a GenAI model to generate malware that can compromise the application workload or end user. Poisoning application data sources with malicious URLs presents another attack vector, potentially exposing people to phishing or other web-based threats.
As a result, preventing infrastructure attacks on GenAI applications requires a multi-faceted approach combining traditional application security and GenAI-specific security measures. Comprehensive prompt guardrails can prevent many prompt injection attacks. Furthermore, the inputs and outputs of GenAI models must be scanned for malicious payloads, including harmful URLs and malware.
Conclusion
This article has introduced a comprehensive, impact-based taxonomy of adversarial prompt attacks, providing a framework for classifying both existing and emerging threats. By establishing a clear and adaptable taxonomy, we aim to empower the GenAI ecosystem to effectively map, understand and mitigate the risks posed by adversarial prompt attacks.
For GenAI application developers, this article highlights the critical importance of designing secure applications and conducting thorough testing before public deployment. Awareness of the techniques and impacts of adversarial prompt attacks will enable developers to build systems that are resilient to evolving threats.
For GenAI users, particularly enterprise users, this article serves as a guide to recognizing the risks of adversarial prompt attacks. By remaining vigilant and cautious when interpreting the outputs of GenAI applications, users can minimize the potential consequences of such attacks.
Enterprise network administrators and policymakers will gain valuable insights into the security risks associated with adversarial prompt attacks. Equipped with this understanding, they can better secure their environments by carefully evaluating GenAI applications, implementing robust policies and managing risks effectively. When attacks occur, they will be better prepared to assess the impacts and take remediation actions.
Robust security solutions can help organizations address these challenges by providing capabilities such as:
- Enhanced visibility and control over GenAI systems
- Model and dataset protection
- Adaptive defense against evolving attacks
- Zero-day threat prevention within the enterprise
These solutions can help detect potential data exposure risks and manage overall security posture. Please refer to the Unit 42 Threat Frontier: Prepare for Emerging AI Risks on how adversaries can leverage GenAI and how Unit 42 can help defend your organization.
By leveraging these tools and the insights shared in this blog, stakeholders across the GenAI ecosystem can confidently navigate the evolving threat landscape and secure their applications, networks and data against adversarial prompt attacks.
Again, please refer to the full prompt attack whitepaper “Securing GenAI: A Comprehensive Report on Prompt Attacks: Taxonomy, Risks, and Solutions” for more technical insights.
Palo Alto Networks offers products and services that can help organizations protect AI systems:
- AI Runtime Security is an adaptive, purpose-built solution that discovers, protects and monitors the entire enterprise application and agent stack including models and data from AI-specific and foundational network threats.
- AI Access Security offers comprehensive visibility and control over GenAI usage in enterprise environments, helping detect potential data exposure risks and strengthening the overall security posture.
- AI Security Posture Management (AI-SPM) enables rapid GenAI application development by reducing risk in the AI application stack and supply chain.
- Unit 42’s AI Security Assessment provides recommended security best practices and helps you proactively identify the threats most likely to target your AI environment.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 00080005045107
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Additional Resources
- Securing GenAI Against Adversarial Prompt Attacks – Palo Alto Networks
- New Frontier of GenAI Threats: A Comprehensive Guide to Prompt Attacks – Palo Alto Networks Blog
- The Unit 42 Threat Frontier: Prepare for Emerging AI Risks – Palo Alto Networks
- Other Unit 42 research on GenAI
Table of Contents
Related Vulnerabilities Resources

 High Profile Threats
High Profile Threats








