
Executive Summary
On Feb. 4, Linux announced CVE-2022-0492, a new privilege escalation vulnerability in the kernel. CVE-2022-0492 marks a logical bug in control groups (cgroups), a Linux feature that is a fundamental building block of containers. The issue stands out as one of the simplest Linux privilege escalations discovered in recent times: The Linux kernel mistakenly exposed a privileged operation to unprivileged users.
Fortunately, the default security hardenings in most container environments are enough to prevent container escape. Containers running with AppArmor, SELinux or Seccomp are protected. That being said, if you run containers without best practice hardenings, or with additional privileges, you may be at risk. The "Am I Affected?" section lists vulnerable container configurations and provides instructions on how to test whether a container environment is vulnerable.
Unit 42 recommends users upgrade to a fixed kernel version. For those running containers, enable Seccomp and ensure AppArmor or SELinux are enabled. Prisma Cloud users can refer to the "Prisma Cloud Protections" section for the mitigations provided by Prisma Cloud.
CVE-2022-0492 is now the third kernel vulnerability in recent months that allows malicious containers to escape. In all three vulnerabilities, securing containers with Seccomp and either AppArmor or SELinux was enough to prevent container escape.
Updated March 7, 2022: Removed mentions of exploitation by (1) containers running with CAP_SYS_ADMIN and not protected by AppArmor or SELinux, and (2) semi-privileged host processes. While those can exploit CVE-2022-0492 to escalate privileges, they often have other avenues to escalate privileges that don't require a vulnerability.
| Vulnerabilities Discussed | CVE-2022-0492 |
| Affected product | Linux |
| Related Unit 42 Topics | Container Escape, Cloud |
Background on Cgroups
Control groups (cgroups) are a Linux feature that allows administrators to limit, account for and isolate the resource usage of a collection of processes. Linux supports two cgroup architectures called v1 and v2. The new vulnerability only affects cgroup v1, which is currently the more widely used architecture by far. The rest of this section will only refer to cgroup v1.
Cgroups are managed via cgroupfs, a management API exposed as a filesystem and normally mounted under /sys/fs/cgroup. By creating and writing to files and directories in a mounted cgroupfs, administrators can create cgroups, control the constraints imposed on a cgroup, add processes to a certain cgroup and so on.
Cgroups are divided into subsystems, each configuring access to a different resource. The memory cgroup for example, can limit the memory consumption of a collection of processes. The device cgroup defines which devices (e.g. the hard drive, or the mouse) can be accessed by processes in the cgroup. Other examples for subsystems include block IO, CPU and remote direct memory access (RDMA).
Each subsystem is typically mounted at /sys/fs/cgroup/<subsystem>, which is considered the root cgroup for the subsystem. Any subsequent directories under the root cgroup denote a new child cgroup. A Docker container, for example, would normally be a part of the /docker/<ctr-id> cgroup, which could be found on the host at /sys/fs/cgroup/<subsystem>/docker/<ctr-id>. Figure 1 shows the cgroup membership of a Docker container, and Figure 2 shows the cgroup membership of a Kubernetes pod.
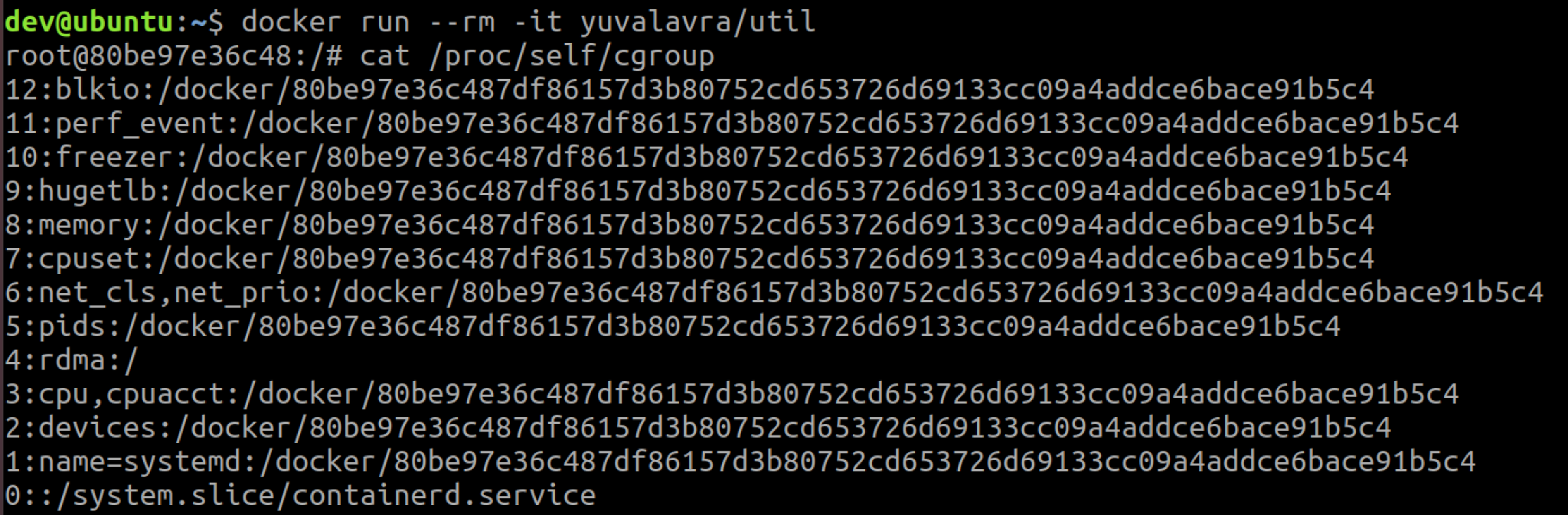
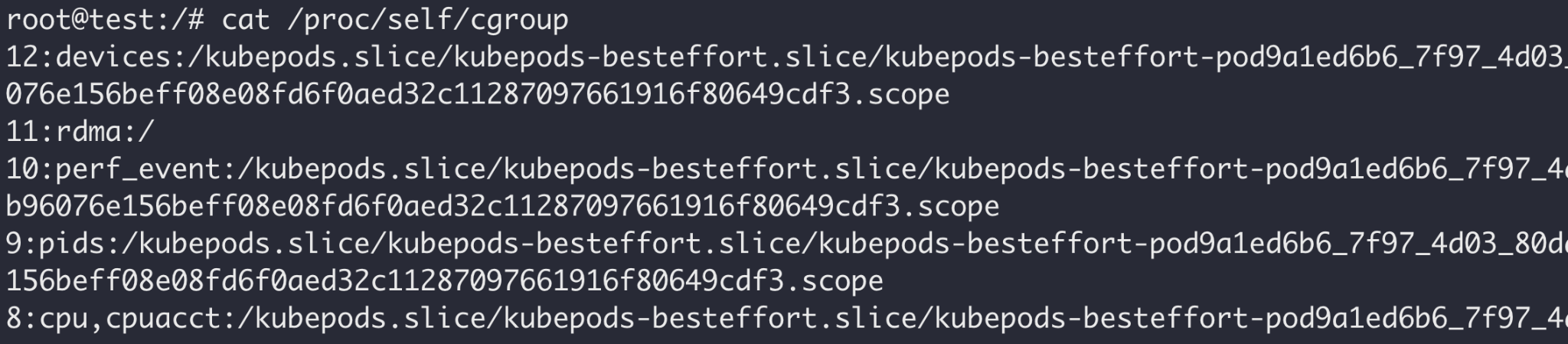
As seen in the screenshots above, not all hosts are configured to support the same subsystems. Docker and Kubernetes also have a variety of cgroup configurations, so containers on your hosts or clusters may not have the same memberships as in the examples above.
Root Cause Analysis – CVE-2022-0492
One of the features of cgroups v1 is the release_agent file. It allows administrators to configure a "release agent" program that would run upon the termination of a process in the cgroup. This is done by writing the desired release agent path to the release_agent file, as demonstrated below:
$ echo /bin/my-release-agent > /sys/fs/cgroup/memory/release_agent
The release_agent file is only visible in the root cgroup directory and affects all its child cgroups. Each child group can be configured to either trigger or not trigger the release agent (upon the termination of one of its processes) by writing to the notify_on_release file. The following command enables the notify_on_release functionality for the a_child_cgroup cgroup:
$ echo 1 > /sys/fs/cgroup/memory/a_child_cgroup/notify_on_release
When a process dies, the kernel checks whether its cgroups had notify_on_release enabled, and if so, spawns the configured release_agent binary. The release agent runs with the highest possible permissions: a root process with all capabilities in the initial namespaces. As such, configuring the release agent is considered a privileged operation, as it allows one to decide which binary will run with full root permissions.
CVE-2022-0492 stems from a missing verification. Linux simply didn't check that the process setting the release_agent file has administrative privileges (i.e. the CAP_SYS_ADMIN capability). The very short patch for CVE-2022-0492 (lines 2-8 below) best explains the vulnerability:
|
1 2 3 4 5 6 7 8 |
@@ -549,6 +549,14 @@ static ssize_t cgroup_release_agent_write(struct kernfs_open_file *of, + /* + * Release agent gets called with all capabilities, + * require capabilities to set release agent. + */ + if ((of->file->f_cred->user_ns != &init_user_ns) || + !capable(CAP_SYS_ADMIN)) + return -EPERM; |
Exploitation Prerequisites
As established, if you can write to the release_agent file, you can force the kernel into invoking a binary of your choosing with elevated privileges and take control of the entire machine. So who can write to the release_agent file on a vulnerable machine? Even though the kernel won't explicitly check the writing processes' privileges, normal file ownership and permission semantics still apply.
Because Linux sets the owner of the release_agent file to root, only root can write to it (or processes that can bypass file permission checks via the CAP_DAC_OVERRIDE capability). As such, the vulnerability only allows root processes to escalate privileges.
At first glance, a privilege escalation vulnerability that can only be exploited by the root user may seem bizarre. In the past, this wouldn't be considered a security issue. But today, running as root doesn't necessarily mean full control over the machine: There's a gray area between the root user and full privileges that includes capabilities, namespaces and containers. In these scenarios where a root process doesn't have full control over the machine, CVE-2022-0492 becomes a serious vulnerability.
A Win for Defense-In-Depth – Container Escape Prerequisites
Not every container can exploit CVE-2022-0492 to escape; only those with permissive security profiles can perform the necessary steps.
Cgroup mounts are mounted read-only inside containers, so the release_agent file they host cannot be written to. A malicious container that wants to exploit CVE-2022-0492 must mount another, writable cgroupfs.
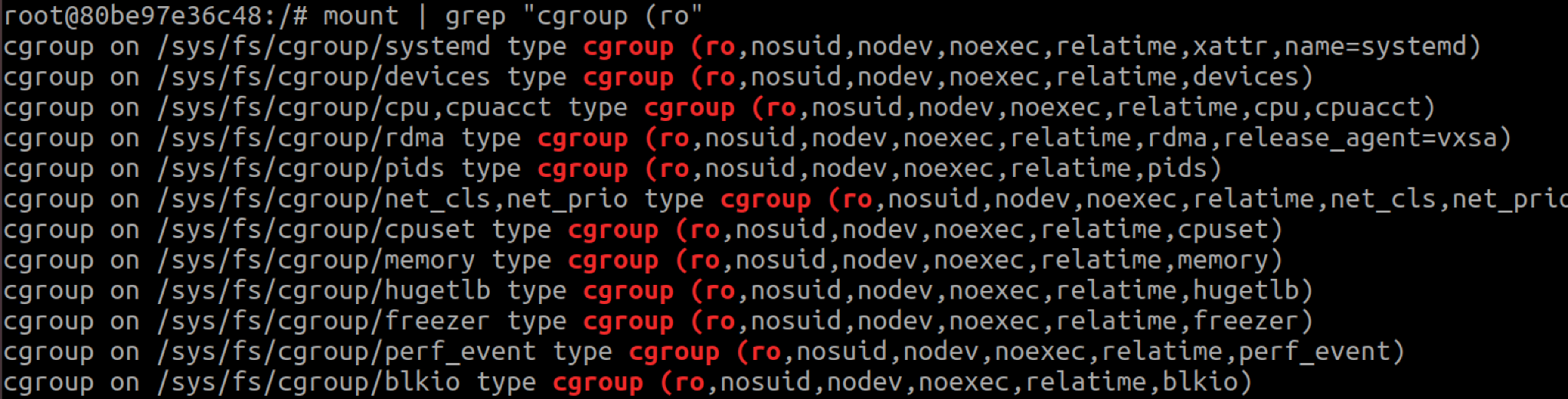
Both AppArmor and SELinux prevent mounting, meaning containers running with either are protected. Without both, a container can mount cgroupfs by abusing user namespaces.
Mounting a cgroupfs requires the CAP_SYS_ADMIN capability in the user namespace hosting the current cgroup namespace. By default, containers run without CAP_SYS_ADMIM, and thus cannot mount cgroupfs in the initial user namespace. But through the unshare() syscall, containers can create new user and cgroup namespaces where they possess the CAP_SYS_ADMIN capability and can mount a cgroupfs.

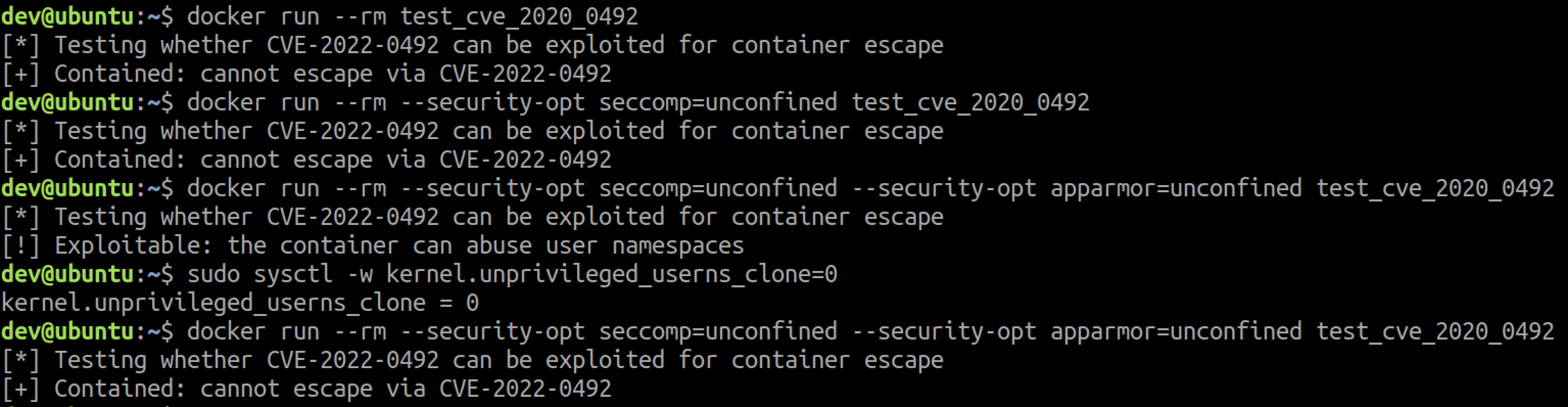
Not every container can create a new user namespace – the underlying host must have unprivileged user namespaces enabled. This is the default on recent Ubuntu releases, for example. Since Seccomp blocks the unshare() syscall, only containers running without Seccomp can create a new user namespace. The container shown in the attached screenshot runs without Seccomp, AppArmor or SELinux.
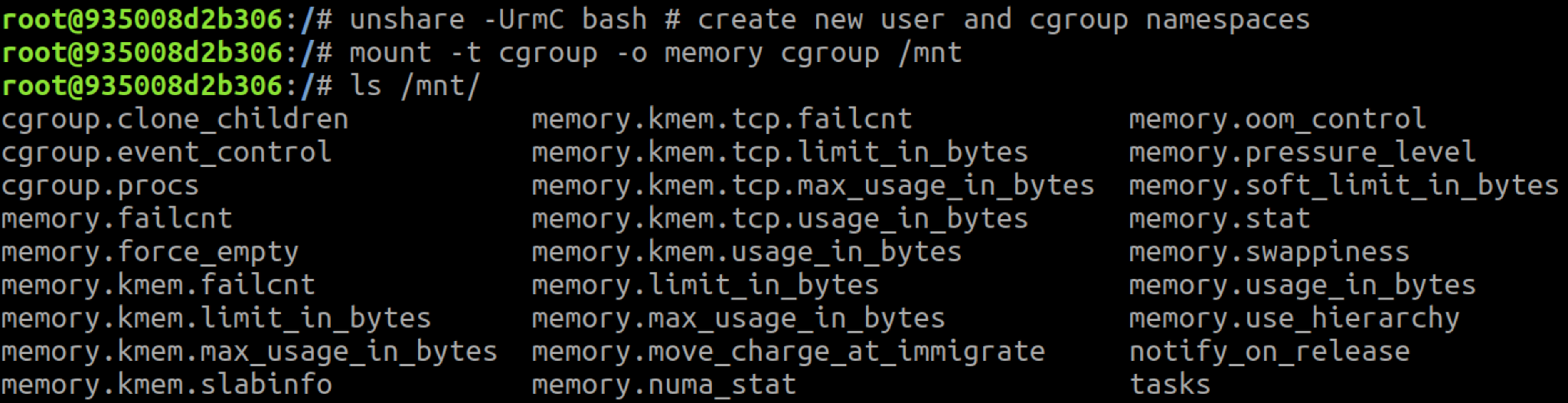
In the screenshot above, the container successfully mounted a memory cgroup, but you may notice that the release_agent file isn't included in the mounted directory!
As mentioned earlier, the release_agent file is only visible in the root cgroup. One caveat of mounting a cgroupfs in a cgroup namespace is that you mount the cgroup you belong to, not the root cgroup. If you scroll back up to Figure 1, you'll see that the container doesn't run in the root memory cgroup but in a child cgroup: /docker/<id>. For the release_agent file to be visible in the cgroup mount, the container must run in the root cgroup of a subsystem.
Also back in Figure 1, you'll see that Docker ran the container in the root RDMA cgroup. If we repeat the same commands for the RDMA cgroup, the release_agent file would be visible.

To exploit the issue, we need to write a malicious release agent to the release_agent file. As seen in Figure 6 above, that file is owned by root, so only root container processes may set the release agent. Figure 7 shows the container setting the release agent, while Figure 8 shows a non-root container failing to do so.


The final step of the escape is to invoke the configured release_agent, which doesn't require any privileges. Since this step is always doable, it has no implications on whether an environment is vulnerable to CVE-2022-0492, and so we decided to leave it out. You can still see how a full exploit looks in the screenshot below.

If you go over the bolded lines in this section, you'll find the requirements for exploiting CVE-2022-0492 for container escape via user namespaces.
Am I Affected?
In conclusion, a container can escape if it runs:
- As the root user, or without the no_new_privs flag; and
- Without AppArmor or SELinux; and
- Without Seccomp; and
- On a host that enables unprivileged user namespaces; and
- In a root v1 cgroup.
Unit 42 researchers created a script that can test whether a container environment is vulnerable to CVE-2022-0492. To test your environment, you can simply deploy a new container running our us-central1-docker.pkg.dev/twistlock-secresearch/public/can-ctr-escape-cve-2022-0492 image, which is configured to run the script, print its output and exit. Alternatively, you can build and run your own image using the Dockerfile included in the tool's repository.
While possible, we don't advise running the script in an existing container. That's because the container may not have the utilities the script relies on, or their correct version, which may lead to inaccurate results.
Mitigations
CVE-2022-0492 is fixed on the latest Linux release; all users are encouraged to upgrade to the latest kernel version of their respective distribution.
To protect against malicious containers in scenarios where upgrading isn't possible, users can enable one of the following mitigations:
- Enable AppArmor or SELinux. See this Kubernetes guide for more information.
- Enable Seccomp. See this Kubernetes guide for more information.
Prisma Cloud Protections
Prisma Cloud detects and alerts on hosts running a vulnerable kernel version. The platform also generates compliance alerts on containers that aren't protected by Seccomp, and on those running with neither AppArmor nor SELinux.
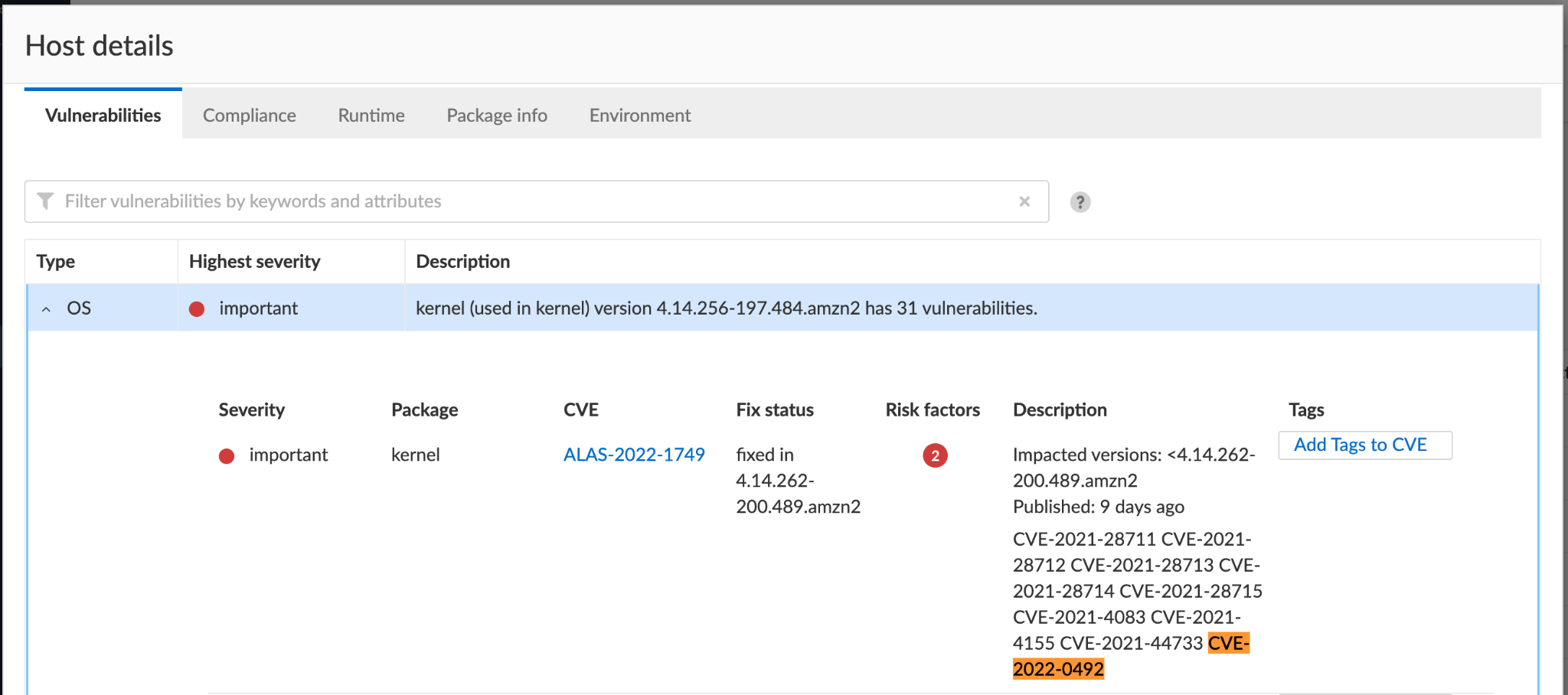
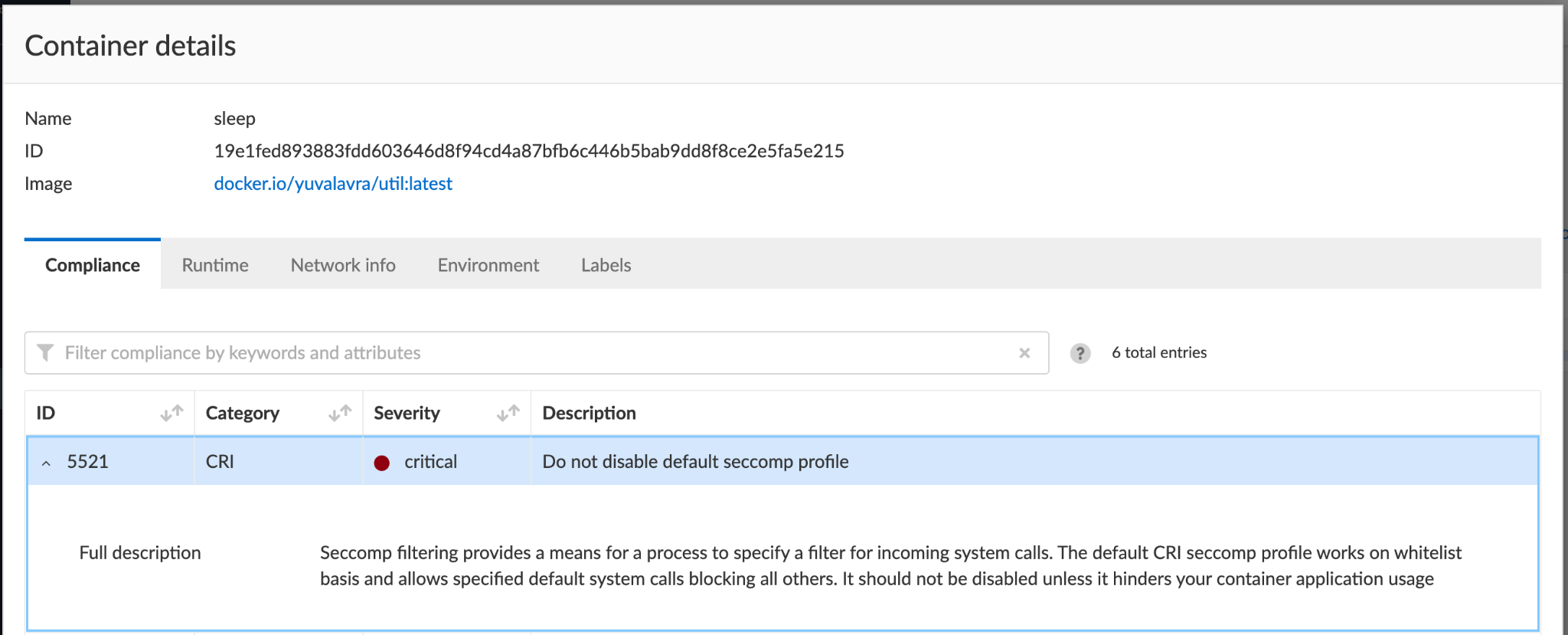
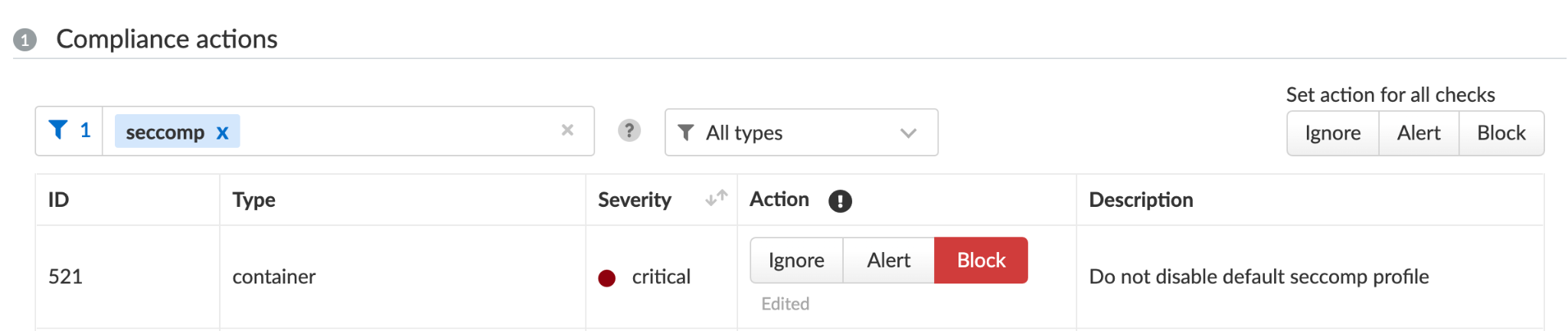
Under Compute/Defend/Compliance, you can further harden your environments by blocking containers that don't follow certain compliance rules, for example, and as shown in Figure 13, those running without Seccomp.
Conclusion
CVE-2022-0492 marks another Linux vulnerability that can be exploited for container escape. Fortunately, environments that follow best practices are protected from this vulnerability. Environments with lax security controls hosting untrusted or publicly exposed containers are, unsurprisingly, at high risk. As always, it's best to upgrade your hosts to a fixed kernel version.
We strongly recommend running containers with Seccomp and either AppArmor or SELinux enabled, to protect against this vulnerability and against future Linux zero-day vulnerabilities. Many privilege escalation vulnerabilities in the Linux kernel can only be exploited for container escape when the container is allowed to create a new user namespace, or in other words, when the container runs without Seccomp.
Prisma Cloud users are encouraged to review Compute/Monitor/Compliance and determine whether any of their containers run without Seccomp. Users can also choose to block containers running without Seccomp, as shown in Figure 13.
Update March 7, 2022, at 7:00 a.m. PT.
Table of Contents
Related Resources


 High Profile Threats
High Profile Threats







