Executive Summary
Data leakage from mobile applications is a known problem in the industry. Leaked data violates users' privacy and can be used for further attacks by cybercriminals, such as collecting a phone’s location or retrieving called numbers. Leaking data can be defined as transferring certain information from a users' device without their knowledge and collecting it at the receiver’s side, potentially exposing this data to third parties on the transmission channel in the process.
With the help of a machine learning (ML)-based spyware detection system, Unit 42 researchers identified multiple Android applications on Google Play that were leaking data, including Baidu Search Box and Baidu Maps, which had been downloaded a combined 6 million times in the U.S. The leaked data made users trackable, potentially over their lifetime. Previous Unit 42 research has outlined examples of how this type of data can be used by attackers once leaked.
While not a definitive violation of Google’s policy for Android apps, the collection of identifiers, such as the IMSI or MAC address, is discouraged based on Android's best practice guide. Unit 42 notified Baidu of this discovery. Unit 42 also notified Google’s Android team, who confirmed the findings, identified unspecified violations and removed the applications from Google Play globally on Oct. 28, 2020. A compliant version of Baidu Search Box became available on Google Play globally on Nov. 19, 2020, while Baidu Maps remains unavailable globally.
Google’s Android team said, “We appreciate the work of the research community, and companies like Palo Alto Networks, who work to strengthen the security of the Play Store. We look forward to collaborating with them on more research in the future."
Behavior that is typically found in Android malware was also discovered in applications that can be downloaded from official app stores (such as Google Play) and have millions of monthly active users.
Palo Alto Networks Next-Generation Firewall customers are protected by threat and spyware identification, as well as by file analysis with a WildFire security subscription.
To prevent data leakage, Android app developers should follow Android’s best practices guide and correctly handle users’ data. Android users should stay informed about the required permissions requested by applications on their devices.
Android Applications Can Leak Sensitive Information
Some Android applications are known to leak data from a user's device. This data can potentially be sensitive, depending on the type of information being transmitted. Data that is often leaked by Android applications include:
- Phone model.
- Screen resolution.
- Phone MAC address.
- Carrier (Telecom Provider).
- Network (Wi-Fi, 2G, 3G, 4G, 5G).
- Android ID.
- IMSI (International Mobile Subscriber Identity).
- IMEI (International Mobile Equipment Identity).
While some of this information, such as screen resolution, is rather harmless, data such as the IMSI can be used to uniquely identify and track a user, even if that user switches to a different phone and takes the number. The IMEI is a unique identifier of the physical device and denotes information such as the manufacturing date and hardware specifications.
The IMSI uniquely identifies a subscriber to a cellular network and is typically associated with a phone’s SIM card, which can be transferred between devices. Both identifiers can be used to track and locate users within a cellular network.
Android applications that collect data, such as the IMSI, are able to track users over the lifetime of multiple devices. For example, if a user switches their SIM card to a new phone and installs an application that previously collected and transmitted the IMSI number, the app developer is able to uniquely identify that user.
Data such as the IMSI or the IMEI are desirable for cybercriminals, who can use methods such as active and passive IMSI catchers to overhear this information from cell phone users. Once this data is acquired, cybercriminals can profile users and further extract sensitive information about them. For example, if a cybercriminal gets hold of a phone’s IMEI number, they could use it to report the phone as stolen and trigger the provider to disable the device and block its access to the network.
This data can also be misused by cybercriminals or state actors to violate a user’s privacy and take advantage of the leaked information to intercept phone calls or text messages. Users can be put further at risk if cybercriminals or state actors intercept messages that transfer information in plain text or with weak encryption.
The sensitivity of device-specific information, such as IMEI, IMSI or the MAC address of a phone, is further highlighted by Android’s best practices guide for app developers on how to handle unique user identifiers. In particular, the guide points out the importance of avoiding usage of hardware-specific identifiers that are not resettable by the user, including the IMSI or Android ID.
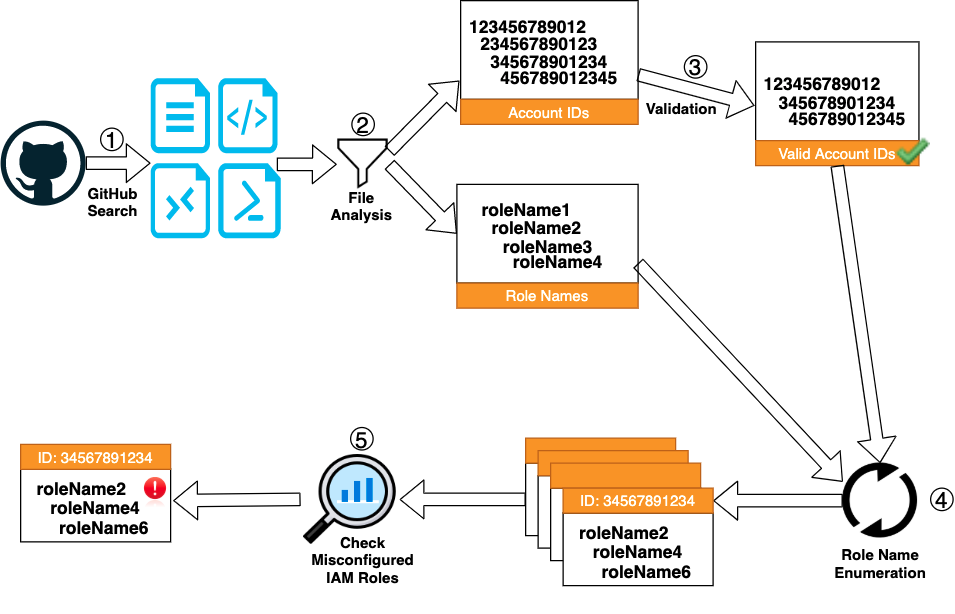
Discovery of Android Applications Leaking Data
To provide an example of data leakage, our ML-based spyware detection system identified the following message from the Android malware UmengAdware (SHA256: 49d7a7c4a2e6afe1feb3642f8aabe314f8c8fa156658e3f3bc0bf6926950d0c1), which was sent to a destination IP address in China (202[.]108.23.105) from an Android application executed in our malware sandbox, WildFire.
{"tiny_msghead":1,"devinfolength":167,"channel_token":"036442386962228444241069682909576236472810696832741015194936","devinfo":"tmAdvNNMC2M\/thyyYqqBnk0qDitAGWECdUbycugQvIMM3lvdew\/V0duYDaWD5edlacVoSVVZUp18\n6SokwTjUs96F8aARRh+IlGEF78CRFfHSJRC\/eSPHZglCMjrVcqmHKS0K+rJCh9Rh4kH5YqRskZVz\ncFIWOXlaRWRN3WCKPyBA1vpqa4ouNPzjSc5IzJBYNKjb6yKt6LRLosaaDlqar5rc12RDEA7micoU\nEDEnKWo=","tinyheart":1,"period":1800,"connect_version":2,"channel_type":3,"channel_id":"3522064114212580475"}
The data of interest is in the devinfo field, as shown in the highlighted part of the message above. After in-depth research on the contents of the message and analyzing multiple Android applications, we identified Baidu’s Android push SDK as the source of the message. The SDK is widely used by some of the largest Baidu applications, such as Baidu Maps or Baidu Search Box, as listed in Table 1 below.
The reverse-engineered Android code in Figure 1 below reflects the message structure and shows the collection of various information about the device, including the phone’s MAC address, carrier information and IMSI number, which is extracted in the function shown in Figure 2.
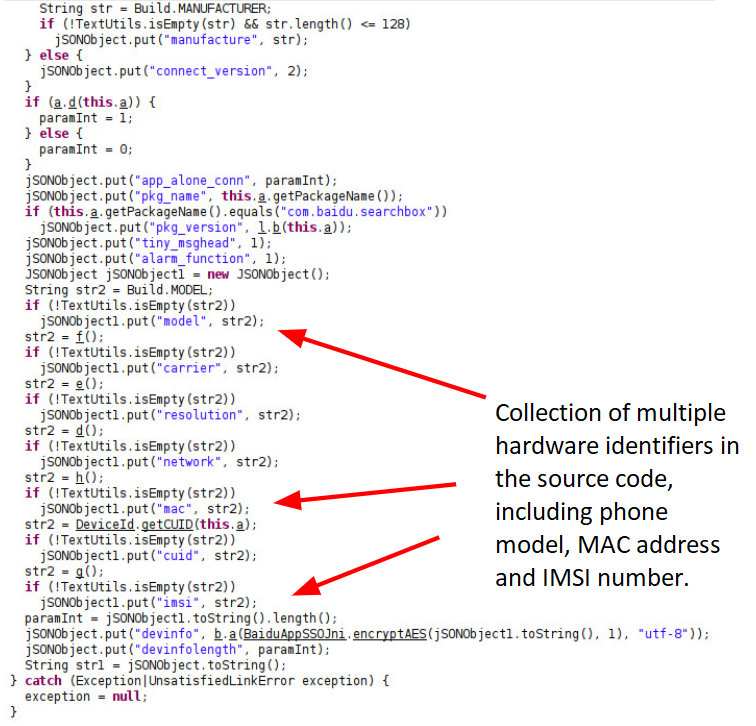
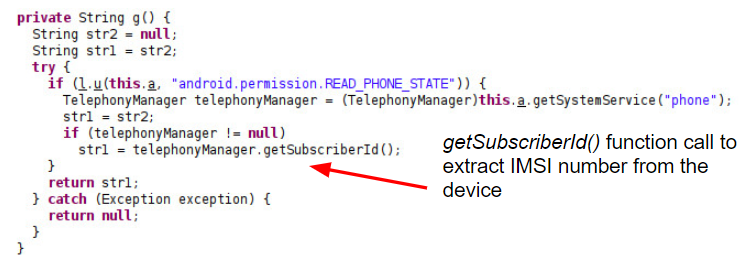
The reverse-engineered code snippets in Figure 2 were found in the Baidu Maps application version 10.24.8, which Unit 42 downloaded from Google Play in the U.S. to analyze. We investigated multiple Android applications for data leakage. The two largest applications we discovered leaking data were Baidu Search Box and Baidu Maps. In Nov. 2020, Baidu reported “Baidu App's daily active users ("DAUs") reached 206 million and its monthly active users ("MAUs") reached 544 million in September 2020.”
Other applications available in Google Play in the U.S. that we analyzed include the Homestyler - Interior Design & Decorating Ideas app, which uses the framework GrowingIO, as shown in Table 1. The app collects private information from a user’s device. This app has not been taken down by Google.
| Android App | SHA256 | Google Play Downloads (U.S.) |
| Baidu Search Box
v11.22.0.8 |
b577fea342897e32a24f57b5cd2f6d9bd6b45f6e0459964c5b21a2ce5cf5830f | 5 million+ |
| Homestyler - Interior Design & Decorating Ideas
v4.0.0 |
bf831b63a7d74463cbca69024eddfb1b10e52543167f0e2ef8ee8fa7a0b4aecf | 5 million+ |
| Baidu Maps v10.24.8 | f6a2487ae55d8b3c7b8f59f585c0c157d90331893a59ed237df868d0b49889fa | 1 million+ |
Table 1. Largest Android apps analyzed by Unit 42 that collect private information, in order by the number of downloads in Google Play in the U.S.
While not a definitive violation of Google’s policy for Android apps, the collection of identifiers, such as the IMSI or MAC address, is discouraged based on Android's best practice guide. Unit 42 notified Baidu of this discovery. We also reported our findings to Google’s Android team. After a detailed analysis of the reported applications, Google confirmed our findings and identified unspecified violations in the reported Baidu applications. This led to the removal of Baidu Search Box and Baidu Maps from Google Play globally on Oct. 28, 2020. A compliant version of Baidu Search Box became available on Google Play globally on Nov. 19, 2020, while Baidu Maps remains unavailable globally.
Another example for Android SDK that collects sensitive information from a user's phone is ShareSDK from the Chinese vendor MobTech. ShareSDK supports more than 40 social media platforms. It helps third-party app developers easily access social media sharing and registration. It also allows them to acquire users' information, friends lists and other social functions. Currently, ShareSDK is offering service for over 37,500 applications, and it has become China's largest developer service platform.
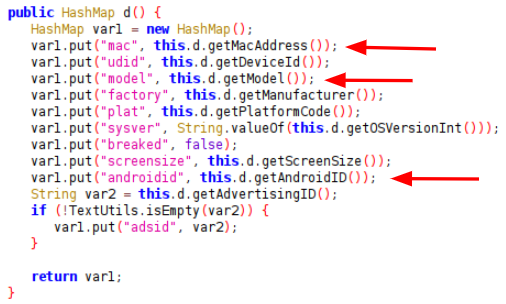
Figure 3 below is the source code of ShareSDK, which collects device data including MAC address, Android ID and Advertising ID and stores it in a HashMap structure.
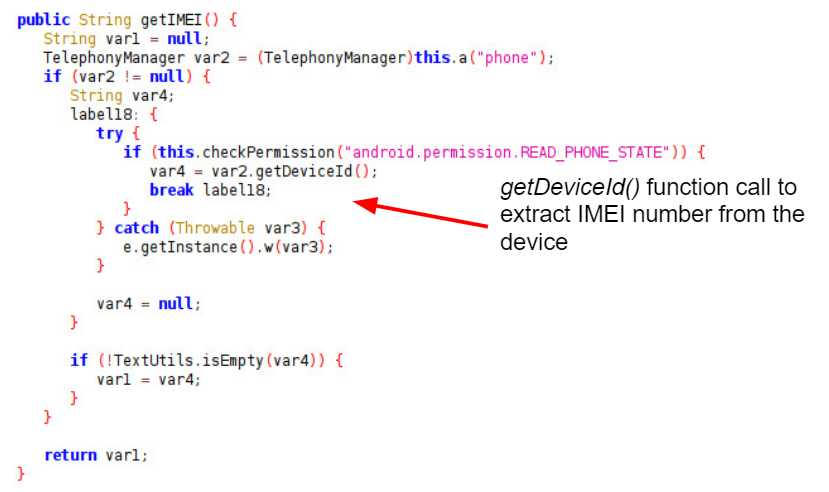
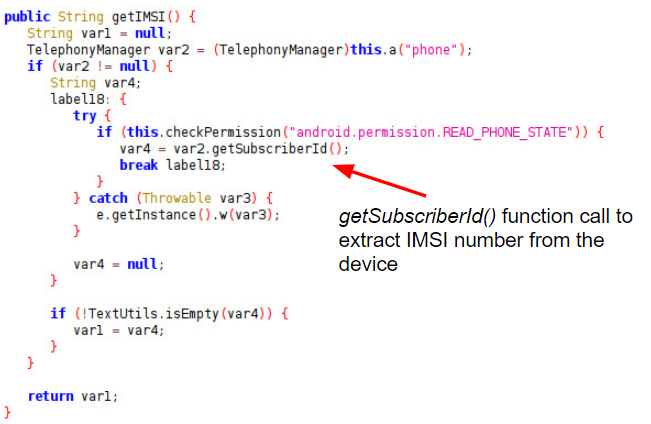
Further code examples from ShareSDK in Figures 4 and 5 show the collection of the IMEI and IMSI data, which are provided in the Android TelephonyManager by calling the functions getDeviceId() and getSubscriberId() respectively.
Similar Behavior Observed in Android Malware
Analysis of Android malware shows that SDKs, such as the Baidu Push SDK or ShareSDK, are frequently used by malicious applications to extract and transmit device data. The sample communication below shows a message extracted from the malware AndroidSudo (SHA256: 3135f8118c55f2a1ca84f69899e330d7ac63c09e77e0c7baff088a0bb185063c), which collects and transmits device data such as the Android ID, IMEI and MAC address.
{"androidid":"**********","model":"**********","plat":1,"sysver":"4.3","screensize":"720x1280","imei":"**********","carrier":-1,"mac":"**********","factory":"asus","serialno":"**********"}
This behavior is equivalent to the functionalities observed in the SDKs and applications previously mentioned in this blog. (Sensitive information in the message is redacted.)
Using Machine Learning to Detect Spyware Traffic
Analyzing traffic patterns for malicious behavior or data leakage is traditionally done based on signatures that make a true/false decision as to whether a traffic pattern matches a signature. To improve our detection capabilities and identify network traffic that is rarely detected by signatures, Unit 42 researchers developed an ML-based spyware detection system able to identify novel and unknown types of malicious traffic by considering over 1,000 features in the network traffic, while maintaining a negligible false positive rate. This new approach shows a considerable increase in detected novel spyware traffic compared to existing intrusion prevention systems.
Our novel spyware detection system identified the findings discussed in this blog by applying models trained on known characteristics, as well as features previously not considered to identify malicious and suspicious network traffic.
Conclusion
Data leakage from Android applications and SDKs represents a serious violation of users' privacy. Detection of such behavior is vital in order to protect the privacy rights of mobile users.
In mobile devices, it is typical to ask a user to grant a list of permissions upon installation of an application or to prompt a user to allow or deny a permission while the application is running. Disallowing permissions can often result in a non-working application, which leads to a bad user experience and might tempt a user to click on “allow” just to be able to use an application. Even if a certain permission is granted, it is often up to the app developers whether it is used in accordance with the official guidelines. For example, reading the phone identifiers such as the Android ID or IMEI requires the permission “read phone status and identity” on Android. While this permission is often used for basic functionality, like detecting an incoming phone call, it also allows access to crucial information such as the IMEI. Once this permission is granted, it is difficult for a user to determine whether the permission is misused by cybercriminals to steal private information.
Palo Alto Networks identifies data leakage by leveraging ML techniques that monitor network traffic for malicious and suspicious behavior during application analysis in WildFire. The advantage of such techniques is that they do not only rely on known traffic patterns, but are also able to identify previously unknown types of data-leaking traffic.
Palo Alto Networks Next-Generation Firewall customers are protected by threat and spyware identification, as well as by file analysis with a WildFire security subscription.
To prevent data leakage, Android app developers should follow Android’s best practices guide and correctly handle users’ data. Android users should stay informed about the required permissions requested by applications on their devices.







![This breaks down how commonly web skimmer samples from family7 used different C2 servers. Results range from 21,122 instances of usage of "onlinestatus[.]site" to 157 instances of usage of "web-stat.me"](https://unit42.paloaltonetworks.com/wp-content/uploads/2020/11/word-image-10.png)








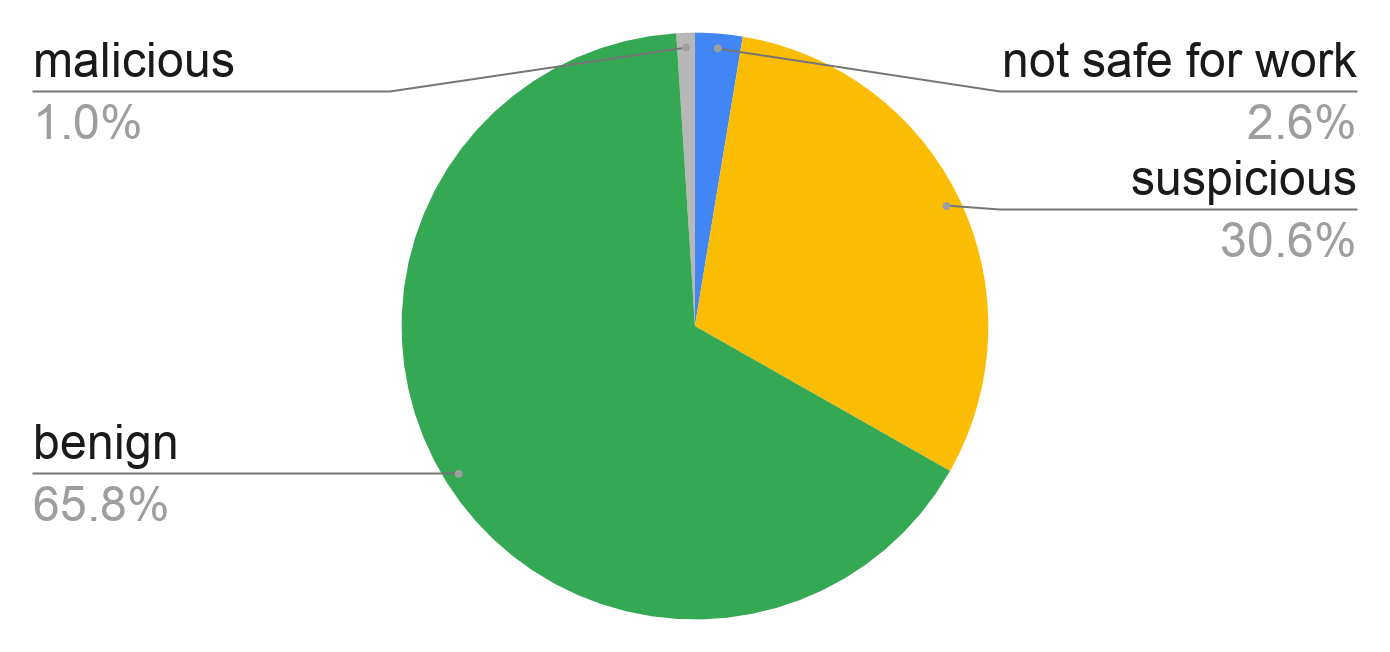
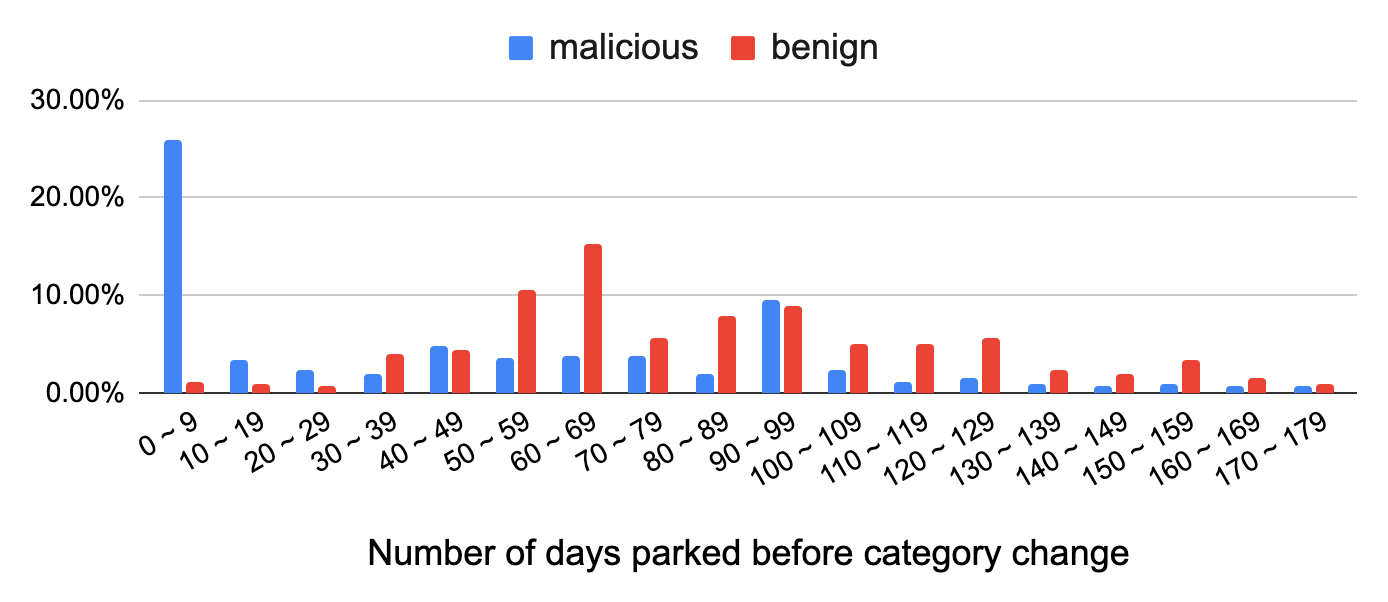
![A list of domain parking service providers, sorted by popularity. Top providers are domaincontrol[.]com, sedoparking[.]com, namebrightdns[.]com, bodis[.]com and parking crew[.]net](https://unit42.paloaltonetworks.com/wp-content/uploads/2020/10/chart-2.png)
![This shows how peoplesvote[.]uk often appears – a parked domain with ad listings.](https://unit42.paloaltonetworks.com/wp-content/uploads/2020/10/word-image-40.png)
![This shows what sometimes occurs after visiting peoplesvote[.]uk - a voting preference landing page.](https://unit42.paloaltonetworks.com/wp-content/uploads/2020/10/word-image-41.png)
![This screenshot shows how bridgeplatform[.]biz appears with ads from domain parking service provider ztomy[.]com](https://unit42.paloaltonetworks.com/wp-content/uploads/2020/10/word-image-43.png)









![The code shown reads: "iam:GetPolicy", "Iam:GetPolicyVersion", "iam:ListRoles", "iam:PassRole", "kms:List*", "s3:*", "sdb:*"], "Effect": "Allow", "Resource": "*" ], -- this shows an unrestricted PassRole permission](https://unit42.paloaltonetworks.com/wp-content/uploads/2020/10/word-image-11.png)